introduzione
Se dovessi scegliere una piattaforma che mi ha tenuto aggiornato con gli ultimi sviluppi in Scienza dei dati e apprendimento automatico – sarebbe GitHub. La grande scala di GitHub, combinato con il potere dei super data scientist di tutto il mondo, lo rende una piattaforma obbligatoria per chiunque sia interessato a questo campo.
Riesci a immaginare un mondo in cui biblioteche e framework di machine learning come BERT, StanfordNLP, TensorFlow, PyTorch, eccetera. non erano open source? È impensabile! GitHub ha democratizzato l'apprendimento automatico per le masse, esattamente in linea con ciò che crediamo in DataPeaker.
Questo è stato uno dei motivi principali per cui abbiamo iniziato questa serie GitHub che copre le librerie e i pacchetti di apprendimento automatico più utili a gennaio 2018.

Insieme a quello, abbiamo anche coperto le discussioni su Reddit che riteniamo siano rilevanti per tutti i professionisti della scienza dei dati. Questo mese non è diverso. Ho selezionato i primi cinque dibattiti per maggio, che si concentrano su due cose: tecniche di apprendimento automatico e consulenza professionale di esperti di dati.
Puoi anche controllare i repository GitHub e le discussioni su Reddit che abbiamo trattato durante quest'anno.:
I migliori repository GitHub (maggio di 2019)


L'interpretabilità è una cosa ENORME nell'apprendimento automatico in questo momento. Essere in grado di capire come un modello ha prodotto il risultato che ha prodotto, un aspetto fondamentale di qualsiasi progetto di machine learning. Infatti, abbiamo anche fatto un podcast con Christoph Molar su ML interpretabile che dovresti controllare.
InterpretML è un pacchetto open source di Microsoft per la formazione di modelli interpretabili e la spiegazione dei sistemi black box. Microsoft lo ha espresso al meglio quando ha spiegato perché l'interpretabilità è essenziale:
- Debug dei modelli: Perché il mio modello ha commesso questo errore??
- Rilevare i pregiudizi: Il mio modello discrimina??
- Cooperazione uomo-IA: Come posso capire e fidarmi delle decisioni del modello??
- Conformità normativa: Il mio modello soddisfa i requisiti legali??
- Applicazioni ad alto rischio: Sanitario, finanziario, giudiziario, eccetera.
Interpretare il funzionamento interno di un modello di apprendimento automatico diventa più difficile con l'aumentare della complessità. Hai mai provato a smontare e comprendere un insieme di più modelli?? Ci vuole molto tempo e fatica per farlo.
Non possiamo semplicemente andare dal nostro cliente o leadership con un modello complesso senza essere in grado di spiegare come ha prodotto un buon punteggio. / precisione. Questo è un biglietto di sola andata per tornare al tavolo da disegno per noi.
I ragazzi di Microsoft Research hanno sviluppato l'algoritmo Explainable Boosting Machine (EBM) per aiutare con l'interpretazione. Questa tecnica MBE ha un'elevata precisione e intelligibilità: Il Sacro Graal.
Interpretare ML non si limita a usare EBM. Supporta anche algoritmi come LIME, modelli lineari, alberi decisionali, tra gli altri. Confrontare modelli e scegliere il migliore per il nostro progetto non è mai stato così facile!
Puoi installare InterpretML usando il seguente codice:
pip install numpy scipy pyscaffold
pip install -U interpret
Google Research fa un'altra apparizione nella nostra serie mensile di Github. Nessuna sorpresa: hanno la maggiore potenza di calcolo nel settore e la stanno utilizzando nell'apprendimento automatico.

La loro ultima versione open source, chiamata Tensor2Robot (T2R) è piuttosto impressionante. T2R è una libreria per addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., valutazione e inferenza di reti neurali profonde su larga scala. Ma aspetta, è stata sviluppata con un obiettivo specifico in mente. È progettato per le reti neurali relative alla percezione e al controllo robotici.
Non ci sono premi per indovinare il framework di apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... in cui viene costruito Tensor2Robot. Ecco com'è, TensorFlow. Tensor2Robot è utilizzato all'interno di Alphabet, Organizzazione principale di Google.
Ecco un paio di progetti realizzati con Tensor2Robot:
TensorFlow 2.0, la versione TensorFlow (TF) il più atteso quest'anno, lanciato ufficialmente il mese scorso. E non vedevo l'ora di metterci le mani sopra!!

Questo repository contiene implementazioni TF di più modelli generativi, Compreso:
- Reti generative antagoniste (GAN)
- Codificatore auto
- Autoencoder variazionale (Ahimè)
- VAE-GAN, tra gli altri.
Tutti questi modelli sono implementati in due set di dati con cui avrai familiarità.: Moda MNIST e NSYNTH.
La parte migliore? Tutte queste implementazioni sono disponibili su un notebook Jupyter!! Quindi puoi scaricarlo ed eseguirlo sul tuo computer o esportarlo su Google Colab. La scelta è tua e TensorFlow 2.0 è qui per te da capire e da usare.
![]()
Un archivio di serie temporali! Non mi sono imbattuto in un nuovo sviluppo di Serie storicheUna serie temporale è un insieme di dati raccolti o misurati in tempi successivi, di solito a intervalli di tempo regolari. Questo tipo di analisi consente di identificare i modelli, Tendenze e cicli dei dati nel tempo. La sua applicazione è ampia, che coprono settori come l'economia, Meteorologia e sanità pubblica, facilitare la previsione e il processo decisionale basato su informazioni storiche.... da abbastanza tempo.
STUMPY è una libreria potente e scalabile che ci aiuta a eseguire attività di data mining di serie temporali. STUMPY è progettato per calcolare un profilo matrice. Vedo che ti stai chiedendo: Che diavolo è un profilo a matrice? Bene, questo profilo di matrice è un vettore che memorizza la distanza euclidea normalizzata z tra qualsiasi sottosequenza all'interno di una serie temporale e il suo vicino più prossimo.
Ecco alcune attività di data mining di serie temporali che questo profilo a matrice ci aiuta a eseguire:
- Scoperta anomalia
- SegmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... semántica
- Stima della densità
- Catene di serie temporali (insieme ordinato temporalmente di schemi di sottosequenza)
- Scoperta del modello / Motivo (sottosequenze approssimativamente ripetute in una serie temporale più lunga)
Utilizzare il seguente codice per installarlo direttamente tramite pepita:
pip install stumpy
MeshCNN è una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. profonda di uso generale per mesh triangolari 3D. Queste mesh possono essere utilizzate per attività come la classificazione o la segmentazione di forme 3D. Un'ottima applicazione di visione artificiale.
Il framework MeshCNN include livelli di convoluzione, raggruppamento e fuga applicati direttamente ai bordi della rete:
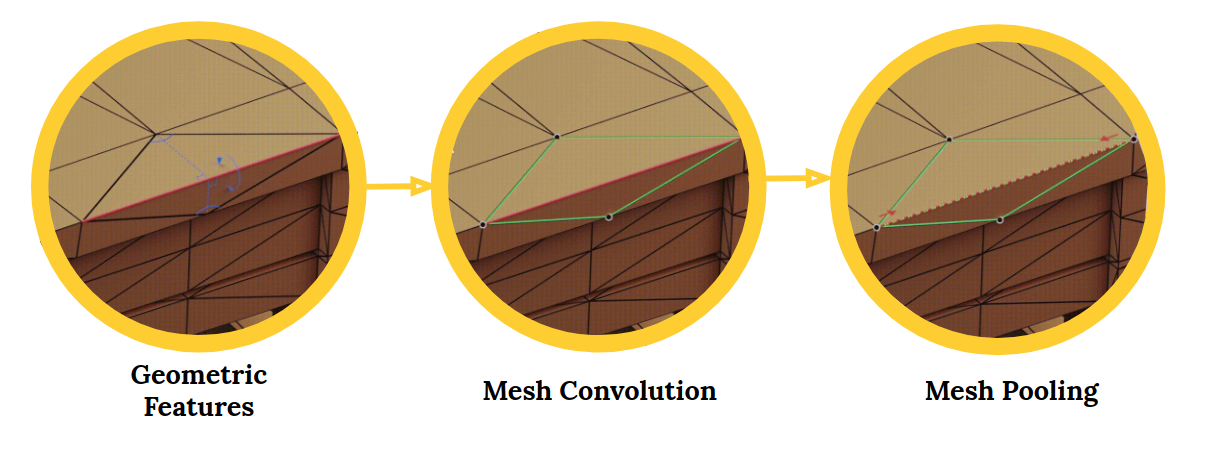
Reti neurali convoluzionali (CNN) sono perfetti per lavorare con immagini e dati visivi. Le CNN sono diventate di gran moda negli ultimi tempi con un boom di attività legate alle immagini che ne emergono.. Rilevamento di oggetti, segmentazione dell'immagine, classificazione delle immagini, eccetera., tutto questo è possibile grazie all'anticipo della CNN.
Il deep learning in 3D sta attirando l'interesse del settore, compresi campi come la robotica e la guida autonoma. Il problema con le forme 3D è che sono intrinsecamente irregolari.. Ciò rende le operazioni come le circonvoluzioni difficili e impegnative..
È qui che entra in gioco MeshCNN.. Dal repository:
Le mesh sono una lista di vertici, bordi e facce, che insieme definiscono la forma dell'oggetto 3D. Il problema è che ogni vertice ha un numero diverso di vicini e non c'è ordine.
Se sei un fan della computer vision e sei interessato a imparare o applicare la CNN, questo è il repository perfetto per te. Puoi saperne di più sulla CNN attraverso i nostri articoli:

Gli algoritmi dell'albero decisionale sono tra le prime tecniche avanzate che apprendiamo nell'apprendimento automatico. Onestamente, Apprezzo molto questa tecnica dopo la regressione logistica. Potrebbe usarlo su set di dati più grandi, capire come ha funzionato, come sono avvenute le divisioni, eccetera.
Personalmente, adoro questo repository. È un tesoro per gli scienziati dei dati. Il repository contiene una raccolta di articoli sugli algoritmi basati su alberi, compresi gli alberi decisionali, regressione e classificazione. Il repository contiene anche l'implementazione di ogni articolo. Cosa potremmo chiedere di più?
Ti sei mai chiesto come funziona il processo di addestramento del tuo algoritmo di machine learning? Scriviamo il codice, qualche complicazione accade dietro le quinte (Il piacere di programmare!), E otteniamo i risultati.
Microsoft Research ha creato uno strumento chiamato TensorWatch che ci permette di vedere visualizzazioni in tempo reale del processo di formazione del nostro modello di machine learning. Sorprendente! Guarda un frammento di come funziona TensorWatch:

TensorWatch, in parole povere, è uno strumento di debug e visualizzazione per l'apprendimento profondo e l'apprendimento per rinforzo. Funziona nei notebook Jupyter e ci consente di eseguire molte altre visualizzazioni personalizzate dei nostri dati e dei nostri modelli.
Discussioni su Reddit
![]()
Prendiamoci qualche minuto per dare un'occhiata alle discussioni più sorprendenti di Reddit relative alla scienza dei dati e all'apprendimento automatico di maggio 2019. Ecco qualcosa per tutti, che tu sia un appassionato o un professionista della scienza dei dati. Quindi scaviamo più a fondo!
Questo è un osso duro. La prima domanda è se dovresti optare per un dottorato di ricerca prima di assumere una posizione nel settore. E più tardi, se ne scegli uno, Quali competenze dovresti acquisire per facilitare la transizione del tuo settore?
Penso che questa discussione possa essere utile per decifrare uno dei più grandi enigmi della nostra carriera: Come passiamo da un campo o linea di lavoro a un altro?? Non guardarlo solo dal punto di vista di un dottorando. Questo è molto importante per la maggior parte di noi che vuole fare il primo salto nell'apprendimento automatico..
Consiglio vivamente di seguire questo thread, come molti esperti data scientist hanno condiviso le loro esperienze e apprendimenti personali.
Recentemente, è stato pubblicato un articolo di ricerca ampliando il titolo di questo thread. Il giornale ha spiegato l'ipotesi del biglietto della lotteria in cui una sottorete più piccola, noto anche come biglietto vincente, potrebbe allenarsi più velocemente rispetto a una rete più grande.
Questa discussione si concentra su questo documento. Per saperne di più sull'ipotesi del biglietto della lotteria e su come funziona, puoi fare riferimento al mio articolo in cui discuto questo concetto in modo che anche i principianti capiscano:
Decodificare i migliori articoli ICLR 2019: le reti neurali sono qui per governare
Ho scelto questa discussione perché posso riconoscerla totalmente. ero solito pensare: Ho imparato molto e, tuttavia, molto altro rimane. Diventerò mai un esperto?? Ho commesso l'errore di guardare solo alla quantità e non alla qualità di ciò che stavo imparando.
Con tecnologia avanzata rapida e continua, ci sarà sempre MOLTO da imparare. Questo thread contiene alcuni solidi consigli su come stabilire le priorità, attenersi a loro e concentrarsi sul compito da svolgere piuttosto che cercare di diventare un esperto in tutti i mestieri.
Note finali
Mi sono divertito molto (e ho imparato) quando metti insieme la raccolta GitHub di machine learning di questo mese! Consiglio vivamente di aggiungere ai segnalibri entrambe le piattaforme e di controllarle regolarmente. È un ottimo modo per tenersi aggiornati con tutte le ultime notizie sull'apprendimento automatico..
Oppure puoi sempre tornare ogni mese e vedere le nostre migliori opzioni. ?
Se pensi che mi sia perso un repository o qualsiasi discussione, commenta qui sotto e sarò felice di discuterne.





