Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Nell'articolo di oggi, Parlerò dello sviluppo di una rete neurale convoluzionale che utilizzi l'API funzionale TensorFlow. Erogherà funzionalità API funzionali, permettendoci di produrre un'architettura del modello ibrido che supera la capacità di un modello sequenziale primario.
Di: TensorFlow
TensorFlow è una libreria popolare, qualcosa che probabilmente senti continuamente nella società del Deep Learning e dell'Intelligenza Artificiale. Existen numerosos paquetes y proyectos de código abierto para el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
- TensorFlow, una libreria di intelligenza artificiale open source che gestisce i diagrammi di flusso dei dati, è la libreria di deep learning più comune. Viene utilizzato per generare reti neurali su larga scala con innumerevoli livelli.
- TensorFlow viene utilizzato per situazioni di deep learning o machine learning come la classificazione, Percezione, Percezione, Scoperta, Previsione e produzione.
Quindi, quando interpretiamo un problema di classificazione, aplicamos un modelo de convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale... Comunque, la maggior parte degli sviluppatori aveva familiarità con la modellazione sequenziale del modello. Gli strati sono accompagnati uno per uno.
- L'API sequenziale ti consente di progettare modelli strato per strato per i problemi più importanti.
- La difficoltà è limitata perché non consente di produrre modelli che condividono livelli o con input o output aggiunti.
- A causa di ciò, possiamo praticare l'API funzionale Tensorflows come modello di output multiplo.
API funzionale (tf.Hard)
L'API funzionale in tf.Hard è un modo alternativo per costruire modelli più flessibili, compresa la formulazione di un modello più complesso.
- Ad esempio, quando si implementa un esempio trascurabilmente più complicato con l'apprendimento automatico, raramente potresti trovarti di fronte allo stato in cui richiedi modelli aggiuntivi per gli stessi dati.
- Quindi dovremmo produrre due output. L'opzione più gestibile sarebbe quella di costruire due modelli separati basati sui dati corrispondenti per fare previsioni..
- Questo sarebbe liscio, ma cosa succede se?, nello scenario attuale, dovevamo avere 50 risultati? Potrebbe essere una seccatura tenere separati tutti quei modelli.
- In alternativa, è più fruttuoso costruire un unico modello con risultati migliori.
Nel metodo API aperto, i modelli sono determinati formando strati e correlandoli direttamente tra loro in insiemi, quindi viene stabilito un Modello che definisce i livelli per funzionare come input e output.
Cosa c'è di diverso nell'API sequenziale?
L'API sequenziale ti consente di generare modelli strato per strato per la maggior parte delle query principali. È regolamentato perché non consente di progettare modelli che condividono livelli o hanno input o output aggiunti.
Di seguito capiamo come creare un oggetto modello API sequenziale:
modello = tf.keras.models.Sequential([ tf.keras.layers.Appiattire(input_shape=(28, 28)), tf.strati.duri.Densi(128, attivazione = "correzione di bozze"), tf.keras.layers.Dropout(0.2), tf.strati.duri.Densi(10, attivazione='softmax') ])
- Nell'API funzionale, puoi progettare modelli che producono molta più versatilità. Decisamente, può correggere i modelli in cui i livelli si riferiscono a più livelli rispetto a prima e dopo.
- Può combinare livelli con più altri livelli. Dovuto, diventa fattibile la produzione di reti eterogenee come reti siamesi e reti residuali.
Iniziamo a sviluppare un modello CNN praticando un'API funzionale
In questo post, utilizamos el conjunto de datos MNIST para construir la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. convolucional para la clasificación de imágenes. Il Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... del MNIST comprende 60,000 immagini di allenamento e 10,000 imágenes de prueba obtenidas de trabajadores de la Oficina del Censo de Estados Unidos y estudiantes de tercer año de secundaria estadounidenses.
# import libraries import numpy as np import tensorflow as tf from tensorflow.keras.layers import Dense, Ritirarsi, Input from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten from tensorflow.keras.models import Model from tensorflow.keras.datasets import mnist # load data (x_treno, y_train), (x_test, y_test) = mnist.load_data() # convert sparse label to categorical values num_labels = len(np.unique(y_train)) y_train = to_categorical(y_train) y_test = to_categorical(y_test) # preprocess the input images image_size = x_train.shape[1] x_train = np.reshape(x_treno,[-1, image_size, image_size, 1]) x_test = np.reshape(x_test,[-1, image_size, image_size, 1]) x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255
Nel codice sopra,
- Distribuí estos dos grupos como addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y prueba y distribuí las etiquetas y las entradas.
- Le variabili indipendenti (x_train y x_test) contengono codici RGB in scala di grigi di 0 un 255, mentre le variabili dipendenti (y_train e y_test) portare etichette di 0 un 9, che descrivono che numero sono veramente.
- È buona norma normalizzare i nostri dati, come è costantemente richiesto nei modelli di deep learning. Podemos lograr esto dividiendo los códigos RGB por 255.
Prossimo, inicializamos los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para las redes.
# parameters for the network input_shape = (image_size, image_size, 1) batch_size = 128 kernel_size = 3 filtri = 64 abbandono = 0.3
Nel codice sopra,
- input_shape: Il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... representa la necesidad de planificar y diseñar una livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche.... independiente que designe los datos de entrada. Il livello di input accetta un argomento in modo che sia una tupla che descrive le dimensioni dei dati di input.
- Dimensione del lotto: è un iperparametro che determina il numero di campioni da eseguire prima di aggiornare i parametri interni del modello.
- kernel_size: si riferisce alle dimensioni (altezza x larghezza) maschera filtro. Reti neurali convoluzionali (CNN) sono essenzialmente una pila di strati segnati dalle operazioni di vari filtri sull'input. Questi filtri sono comunemente chiamati core..
- filtro: se expresa mediante un vector de pesos entre los que convolvemos la entrada.
- Abandonar: es un proceso en el que se descuidan las neuronas seleccionadas al azar durante el entrenamiento. Esto implica que su participación en la activación de las neuronas aguas abajo se descarta temporalmente en el pase frontal.
Definamos un perceptrón multicapa simplista, una red neuronal convolucional:
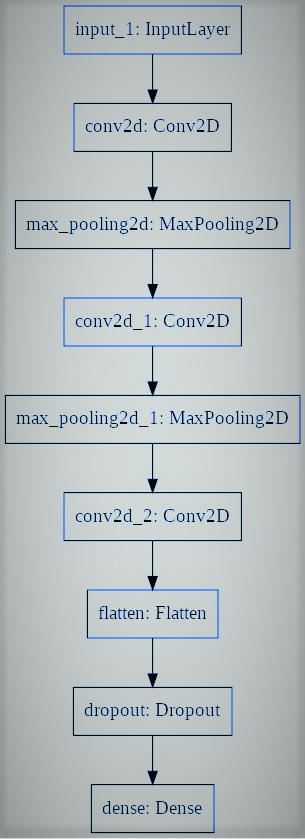
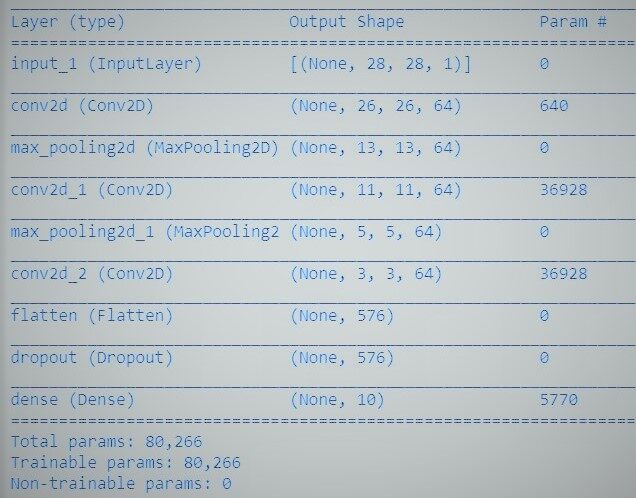
# utiliaing functional API to build cnn layers inputs = Input(shape=input_shape) y = Conv2D(filters=filters, kernel_size=kernel_size, attivazione = 'rileggere')(inputs) y = MaxPooling2D()(e) y = Conv2D(filters=filters, kernel_size=kernel_size, attivazione = 'rileggere')(e) y = MaxPooling2D()(e) y = Conv2D(filters=filters, kernel_size=kernel_size, attivazione = 'rileggere')(e) # convert image to vector y = Flatten()(e) # dropout regularization y = Dropout(ritirarsi)(e) outputs = Dense(num_labels, attivazione='softmax')(e) # model building by supplying inputs/outputs model = Model(inputs=inputs, uscite=uscite)
Nel codice sopra,
- Specifichiamo un modello perceptron multistrato verso la classificazione binaria.
- Il modello contiene un livello di input, 3 livelli nascosti accanto a 64 neuroni e uno strato di prodotto con 1 Uscita.
- Le funzioni di trigger lineare rettificate si applicano a tutti i livelli nascosti, y se adopta una funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... softmax en la capa de producto para la clasificación binaria.
- E puoi vedere che gli strati nel modello sono correlati a coppie. Ciò si ottiene stabilendo da dove proviene l'input durante la determinazione di ogni nuovo livello.
- Come con tutte le API sequenziali, il modello è l'informazione che possiamo riassumere, regolare, valutare e applicare per eseguire previsioni.
TensorFlow introduce una classe di modelli con cui puoi esercitarti per generare un modello dai livelli sviluppati. Richiede che tu definisca solo i livelli di input e output, mapeando la estructura y el gráfico del modelo de la arquitectura de red.
Finalmente, entrenamos al modelo.
modello.compila(perdita="categorical_crossentropy", ottimizzatore="Adamo", metriche=['precisione']) model.fit(x_treno, y_train, validation_data=(x_test, y_test), epochs=20, batch_size=batch_size) # accuracy evaluation score = model.evaluate(x_test, y_test, batch_size=batch_size, verboso=0) Stampa("nTest accuracy: %.1F%%" % (100.0 * punto[1]))
Ahora hemos desarrollado con éxito una red neuronal convolucional para distinguir dígitos escritos a mano con la API funcional de Tensorflow. Abbiamo ottenuto una precisione superiore a 99% e possiamo salvare il modello e progettare un'applicazione web di classificazione delle cifre.
Riferimenti:
- https://www.tensorflow.org/guide/keras/functional
- https://machinelearningmastery.com/keras-functional-api-deep-learning/
Il supporto mostrato in questo articolo sul riconoscimento della lingua dei segni non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





