introduzione
L'e-commerce ha rivoluzionato il modo di fare acquisti. Quel telefono che hai risparmiato per comprare per mesi? È solo una ricerca e pochi clic di distanza. Gli articoli vengono consegnati in pochi giorni (A volte anche il giorno dopo!).
Per i rivenditori online, non ci sono restrizioni relative alla gestione dell'inventario o alla gestione dello spazio. Possono vendere tutti i prodotti che vogliono. I negozi fisici possono tenere solo un numero limitato di prodotti a causa dello spazio limitato che hanno a disposizione.
Ricordo quando ordinavo libri nella mia libreria locale, e prima ci metteva più di una settimana ad arrivare. Sembra una storia dei tempi antichi ormai!

Fonte: http://www.yeebaplay.com.br
Ma lo shopping online ha i suoi avvertimenti. Una delle sfide più grandi è verificare l'autenticità di un prodotto. È buono come pubblicizzato sul sito di e-commerce?? Il prodotto durerà più di un anno?? Le opinioni degli altri clienti sono davvero vere o sono pubblicità ingannevole?? Queste sono domande importanti che i clienti dovrebbero porsi prima di sprecare i loro soldi.
Questo è un ottimo posto per sperimentare e applicare tecniche di elaborazione del linguaggio naturale. (PNL). Questo articolo ti aiuterà a capire l'importanza di sfruttare le recensioni dei prodotti online con l'aiuto di Topic Modeling.
Dai un'occhiata agli articoli seguenti nel caso avessi bisogno di un rapido aggiornamento sulla modellazione del tema:
Sommario
- Importanza delle recensioni online
- Dichiarazione problema
- Perché la modellazione del tema è per questo compito??
- Implementazione Python
- Leggi i dati
- Pretrattamento dei dati
- Costruire un modello LDA
- Visualizzazione dei temi
- Altri metodi per sfruttare le recensioni online
- Qual è il prossimo?
Importanza delle recensioni online
Qualche giorno fa, Mi sono lanciata nell'e-commerce e ho comprato uno smartphone online. Rientrava nel mio budget e aveva una valutazione decente di 4.5 su 5.

Sfortunatamente, si è rivelata una cattiva decisione poiché la batteria di riserva era molto al di sotto della media. Non ho controllato le recensioni del prodotto e ho preso la decisione affrettata di acquistarlo basandomi esclusivamente sulle sue valutazioni. E so di non essere l'unico che ha commesso questo errore!
Le sole valutazioni non danno un quadro completo dei prodotti che vogliamo acquistare, come ho scoperto a mio discapito. Perciò, Che cosa misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de precaución, Consiglio sempre alle persone di leggere le recensioni di un prodotto prima di decidere se acquistarlo o meno.
Ma poi sorge un problema interessante. E se il numero di recensioni fosse centinaia o migliaia?? Non è possibile passare attraverso tutte quelle recensioni, verità? Ed è qui che trionfa l'elaborazione del linguaggio naturale.
Afferma la dichiarazione del problema
Una dichiarazione di problema è il seme da cui germoglia la tua analisi. Perciò, è davvero importante avere una solida dichiarazione del problema, chiaro e ben definito.

Come possiamo analizzare un gran numero di recensioni online utilizzando l'elaborazione del linguaggio naturale? (PNL)? Definiamo questo problema.
Le recensioni dei prodotti online sono un'ottima fonte di informazioni per i consumatori. Dal punto di vista dei venditori, le recensioni online possono essere utilizzate per valutare il feedback dei consumatori sui prodotti o servizi che vendono. tuttavia, poiché queste recensioni online sono spesso travolgenti in termini di numeri e informazioni, un sistema intelligente, in grado di trovare informazioni chiave (temi) da queste recensioni, sarà di grande aiuto sia per i consumatori che per i venditori. Questo sistema avrà due scopi:
- Consenti ai consumatori di estrarre rapidamente gli argomenti chiave coperti dalle recensioni senza doverli esaminare tutti.
- Aiuta i venditori / rivenditori per ottenere il feedback dei consumatori sotto forma di argomenti (tratto dalle recensioni dei consumatori)
Per risolvere questo compito, useremo il concetto di Modellazione a Tema (LDA) nei dati di Amazon Automotive Review. Puoi scaricarlo da questo Collegamento. Set di dati simili possono essere trovati per altre categorie di prodotti qui.
Perché dovresti usare la modellazione del tema per questa attività??
Come suggerisce il nome, la modellazione degli argomenti è un processo per identificare automaticamente gli argomenti presenti in un oggetto di testo e derivare modelli nascosti esibiti da un corpus di testo. I modelli di temi sono molto utili per molteplici scopi, Compreso:
- Raggruppamento di documenti
- Organizza grandi blocchi di dati testuali
- Recupero di informazioni di testo non strutturato
- Selezione delle funzioni
Un buon modello a tema, quando ti alleni in un testo sul mercato azionario, dovrebbe tradursi in argomenti come “offerta”, “negoziazione”, “dividendo”, “scambio”, eccetera. L'immagine seguente illustra come funziona un tipico modello di tema:

Nel nostro caso, invece di documenti di testo, abbiamo migliaia di recensioni di prodotti online per gli articoli elencati nella categoria "Automotive". Il nostro obiettivo qui è estrarre un certo numero di gruppi di parole importanti dalle recensioni.. Questi gruppi di parole sono fondamentalmente gli argomenti che aiuterebbero a determinare ciò di cui i consumatori stanno realmente parlando nelle recensioni..

Implementazione Python
In questa sezione, attiveremo i nostri taccuini Jupyter (O qualsiasi altro IDE che usi per Python!). Qui lavoreremo sulla dichiarazione del problema definita sopra per estrarre argomenti utili dal nostro set di dati di recensioni online utilizzando il concetto di mappatura di Dirichlet latente. (LDA).
Nota: Come ho detto nell'introduzione, Consiglio vivamente di leggere questo articolo per capire cos'è l'LDA e come funziona.
Carichiamo prima tutte le librerie necessarie:
import nltk
da nltk import FreqDist
nltk.download('stopword') # corri questa volta
importa panda come pd
pd.set_option("display.max_colwidth", 200)
importa numpy come np
importare re
importare spazio
import gensim
da gensim import corpora
# librerie per la visualizzazione
import pyLDAvis
import pyLDAvis.gensim
importa matplotlib.pyplot come plt
import seaborn come sns
%matplotlib in linea
Per importare i dati, prima estrai i dati nella tua directory di lavoro e poi usa il read_json () funzione panda per leggerlo in un frame di dati panda.
df = pd.read_json('Automotive_5.json', righe=Vero)
df.head()

Come potete vedere, i dati contengono le seguenti colonne:
- IDrecensore – ID del revisore
- come in – numero identificativo del prodotto
- nomerecensore – nome del revisore
- utile – rivedere la valutazione dell'utilità, ad esempio, 2/3
- recensioneText – rivedere il testo
- generalmente – valutazione del prodotto
- astratto – riassunto della recensione
- unixReviewTime – tempo di revisione (unix ora)
- tempo di revisione – tempo di revisione (senza elaborazione)
Per lo scopo della nostra analisi e di questo articolo, useremo solo la colonna delle recensioni, vale a dire, recensioneText.
Pretrattamento dei dati
La preelaborazione e la pulizia dei dati è un passaggio importante prima di qualsiasi attività di estrazione di testo, in questo passaggio, elimineremo i segni di punteggiatura, le stopword e normalizzeremo il più possibile le revisioni. Dopo ogni fase di pre-elaborazione, è buona norma controllare le parole più frequenti nei dati. Perciò, definamos una función que trazaría un grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia.... de n palabras más frecuentes en los datos.
# funzione per tracciare i termini più frequenti
def freq_words(X, termini = 30):
all_words=" ".aderire([testo per testo in x])
all_words = all_words.split()
fdist = FreqDist(tutte le parole)
word_df = pd.DataFrame({'parola':elenco(fdist.keys()), 'contare':elenco(fdist.values())})
# selezionando in alto 20 parole più frequenti
d = parole_df.nlargest(colonne="contare", n = termini)
plt.figure(figsize=(20,5))
ax = sns.barplot(dati=d, x= "parola", y = "contare")
ax.set(ylabel="Contare")
plt.mostra()
Proviamo questa funzione e scopriamo quali sono le parole più comuni nel nostro set di dati delle recensioni.
freq_words(df['recensione'])
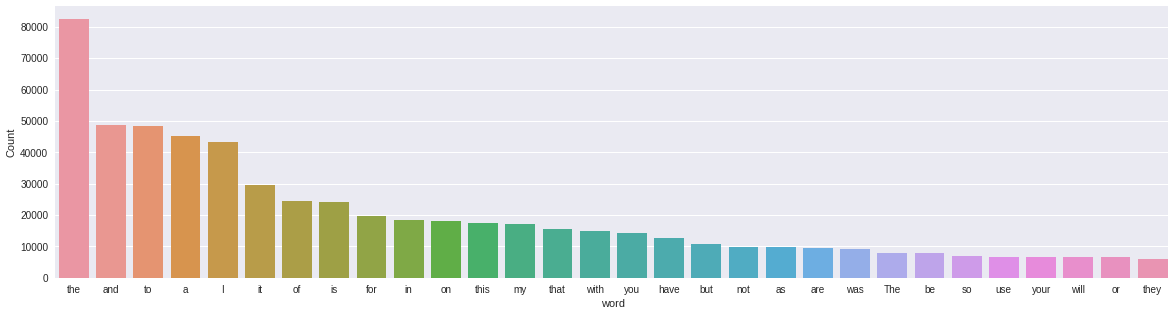
Le parole più comuni sono “il”, “e”, “per”, eccetera. Queste parole non sono così importanti per il nostro compito e non raccontano alcuna storia.. Dobbiamo sbarazzarci di questo tipo di parole. Prima di ciò, rimuoviamo punteggi e numeri dai nostri dati di testo.
# rimuovere i caratteri indesiderati, numeri e simboli
df['recensione'] = df['recensione'].str.replace("[^ a-zA-Z #]", " ")
Proviamo ad eliminare le stopword e le parole brevi (<2 lettere) di recensioni.
da nltk.corpus importa parole non significative
stop_words = stopwords.parole('inglese')
# funzione per rimuovere le stopword
def remove_stopwords(rev):
rev_new = " ".aderire([io per io in rev se non in stop_words])
rev_new di ritorno
# rimuovi le parole brevi (lunghezza < 3)
df['recensione'] = df['recensione'].applicare(lambda x: ' '.aderire([w per w in x.split() se len(w)>2]))
# rimuovere le stopword dal testo
recensioni = [remove_stopwords(r.split()) per r in df['recensione']]
# rendere l'intero testo minuscolo
recensioni = [r.inferiore() per r nelle recensioni]
Rintracciamo le parole più frequenti e vediamo se sono uscite le parole più significative.
freq_words(recensioni, 35)
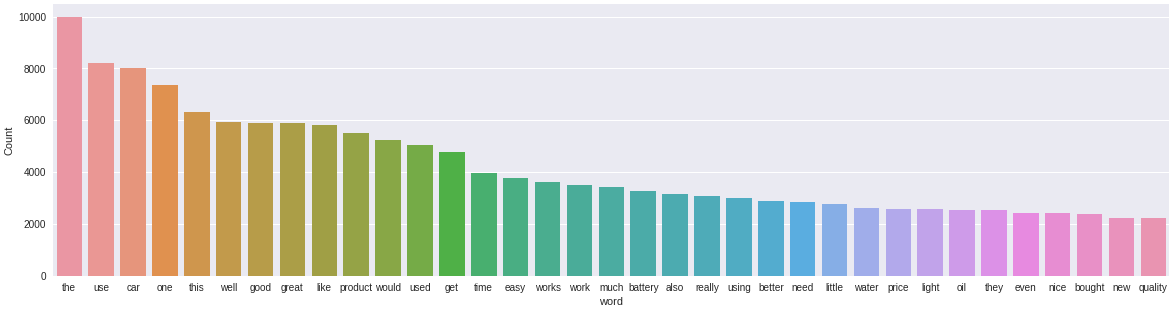
Possiamo vedere alcuni miglioramenti qui. Termini come “batteria”, “prezzo”, “Prodotto”, “olio”, che sono abbastanza rilevanti per la categoria Automotive. tuttavia, abbiamo ancora termini neutri come "il", 'questo', 'tanto', 'loro’ che non sono così rilevanti.
Per rimuovere ulteriormente il rumore dal testo, possiamo usare la lemmatizzazione dalla libreria spaCy. Riduci ogni parola data alla sua forma base, riducendo così più forme di una parola a una singola parola.
!python -m spacy download it # corsa una volta
nlp = spacy.load('Su', disabilita=['analizzatore', 'fuori uso'])
def lemmatizzazione(testi, tag=['SOSTANTIVO', 'REG.']): # filter noun and adjective
output = []
per l'invio di testi:
doc = nlp(" ".aderire(spedito))
output.append([token.lemma_ per token in doc if token.pos_ in tags])
Uscita di ritorno
Tokenizziamo le recensioni e poi lemmatizziamo le recensioni tokenizzate.
tokenized_reviews = pd.Series(recensioni).applicare(lambda x: x.split()) Stampa(tokenized_reviews[1])
['queste', 'lungo', "cavi", 'opera', 'bene', 'camion', 'qualità', 'sembra', 'poco', 'squallido', 'lato', 'per', 'soldi', 'in attesa', 'dollaro', 'affrettato', 'Maglione', "cavi", 'sembrare', 'Come', 'voluto', 'vedere', 'Cinese', 'bussare', 'negozio', 'Come', 'porto', 'trasporto', 'dollari']
recensioni_2 = lemmatizzazione(tokenized_reviews) Stampa(recensioni_2[1]) # stampa recensione lemmatizzata
['lungo', 'cavo', 'bene', 'camion', 'qualità', 'poco', 'squallido', 'lato', 'soldi', 'dollaro', 'Maglione', 'cavo', 'Cinese', 'negozio', 'porto', 'trasporto', 'secchio']
Come potete vedere, non abbiamo solo lemmatizzato le parole, ma abbiamo anche filtrato solo nomi e aggettivi. Rimuoviamo i token dalle recensioni di slogan e tracciamo le parole più comuni.
recensioni_3 = []
per io nel raggio d'azione(len(recensioni_2)):
recensioni_3.append(' '.aderire(recensioni_2[io]))
df['recensioni'] = recensioni_3
freq_words(df['recensioni'], 35)
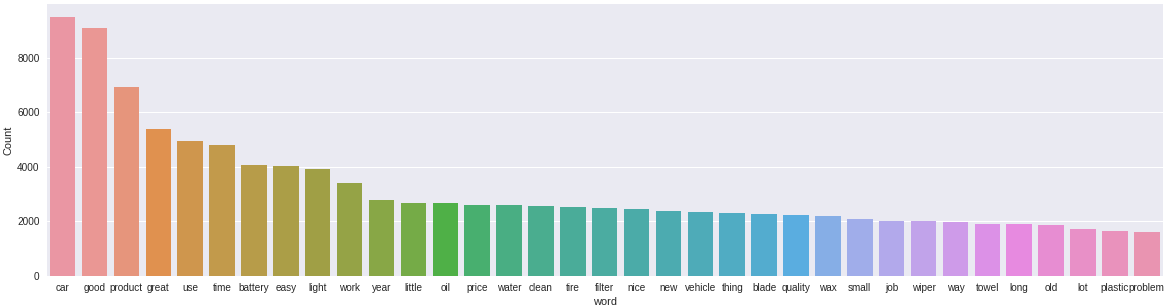
Sembra che ora i termini più frequenti nei nostri dati siano rilevanti. Ora possiamo andare avanti e iniziare a costruire il nostro modello di tema.
Costruire un modello LDA
Inizieremo creando il dizionario dei termini del nostro corpus, donde a cada término único se le asigna un indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori....
dizionario = corpora.Dizionario(recensioni_2)
Dopo, convertiremo l'elenco delle revisioni (recensioni_2) in una Matrice di termini del documento utilizzando il dizionario preparato sopra.
doc_term_matrix = [dizionario.doc2bow(rev) per revisione in recensioni_2]
# Creazione dell'oggetto per il modello LDA utilizzando la libreria gensim
LDA = gensim.models.ldamodel.LdaModel
# Costruisci il modello LDA
lda_model = LDA(corpus=doc_term_matrix, id2word=dizionario, num_topics=7, random_state=100,
chunksize=1000, passa=50)
Il codice sopra richiederà un po' di tempo. Nota che ho specificato il numero di temi come 7 per questo modello utilizzando il num_topics parametro. Puoi specificare un numero qualsiasi di temi utilizzando lo stesso parametro.
Stampiamo gli argomenti che il nostro modello LDA ha imparato.
lda_model.print_topics()
[(0, '0.030*"macchina" + 0.026*"olio" + 0.020*"filtro" + 0.018*"motore" + 0.016*"dispositivo" + 0.013*"codice" + 0.012*"veicolo" + 0.011*"app" + 0.011*"modificare" + 0.008*"bosch"'), (1, '0.017*"facile" + 0.014*"installare" + 0.014*"porta" + 0.013*"nastro" + 0.013*"jeep" + 0.011*"davanti" + 0.011*"stuoia" + 0.010*"lato" + 0.010*"faro" + 0.008*"in forma"'), (2, '0.054*"Lama" + 0.045*"tergicristallo" + 0.019*"parabrezza" + 0.014*"piovere" + 0.012*"neve" + 0.012*"Buona" + 0.011*"anno" + 0.011*"vecchio" + 0.011*"macchina" + 0.009*"tempo"'), (3, '0.044*"macchina" + 0.024*"asciugamano" + 0.020*"Prodotto" + 0.018*"pulire" + 0.017*"Buona" + 0.016*"cera" + 0.014*"acqua" + 0.013*"utilizzo" + 0.011*"tempo" + 0.011*"lavare"'), (4, '0.051*"leggero" + 0.039*"batteria" + 0.021*"lampadina" + 0.019*"potenza" + 0.018*"macchina" + 0.014*"luminosa" + 0.013*"unità" + 0.011*"caricabatterie" + 0.010*"Telefono" + 0.010*"carica"'), (5, '0.022*"pneumatico" + 0.015*"tubo flessibile" + 0.013*"utilizzo" + 0.012*"Buona" + 0.010*"facile" + 0.010*"pressione" + 0.009*"piccolo" + 0.009*"trailer" + 0.008*"simpatico" + 0.008*"acqua"'), (6, '0.048*"Prodotto" + 0.038*"Buona" + 0.027*"prezzo" + 0.020*"Grande" + 0.020*"pelle" + 0.019*"qualità" + 0.010*"opera" + 0.010*"recensione" + 0.009*"amazon" + 0.009*"di valore"')]
Il quarto tema Tema 3 ha termini come “asciugamano”, “ripulire”, “cera”, “Acqua”, il che indica che l'argomento è strettamente correlato al lavaggio dell'auto. Simile, Tema 6 sembra avere a che fare con il valore complessivo del prodotto, poiché ha termini come “prezzo”, “qualità” e “valore”.
Visualizzazione dei temi
Per visualizzare i nostri temi in uno spazio bidimensionale utilizzeremo il libreria pyLDAvis. Questa visualizzazione è di natura interattiva e mostra argomenti insieme alle parole più rilevanti..
# Visualizza gli argomenti pyLDAvis.enable_notebook() vis = pyLDAvis.gensim.prepare(lda_model, doc_term_matrix, dizionario) vis

Il codice completo è disponibile qui.
Altri metodi per sfruttare le recensioni online
Oltre ai temi di modellazione, ci sono molti altri metodi di PNL utilizzati per analizzare e comprendere le recensioni online. Alcuni di loro sono elencati di seguito:
- Riepilogo del testo: Riassumi le recensioni in un paragrafo o in alcuni punti elenco.
- Riconoscimento di entità: Estrai le entità dalle recensioni e identifica quali prodotti sono più popolari (o impopolare) tra i consumatori.
- Identificare le tendenze emergenti: Secondo il timestamp delle recensioni, possono essere identificati temi o entità nuovi ed emergenti. Ci permetterebbe di scoprire quali prodotti stanno diventando popolari e quali stanno perdendo presa sul mercato..
- Analisi del sentimento: Per i rivenditori, comprendere il sentimento delle recensioni può essere utile per migliorare i tuoi prodotti e servizi.
Qual è il prossimo?
Il recupero delle informazioni ci risparmia la fatica di rivedere le recensioni dei prodotti una per una. Ci dà un'idea chiara di ciò che gli altri consumatori stanno parlando del prodotto.
tuttavia, non ci dice se le recensioni sono positive, neutro o negativo. Questo diventa un'estensione del problema del recupero delle informazioni in cui non dobbiamo solo estrarre i problemi, ma determina anche il sentimento. Questo è un compito interessante che tratteremo nel prossimo articolo..
Note finali
La modellazione di argomenti è una delle tecniche di PNL più popolari con varie applicazioni del mondo reale, come riduzione dimensionale, riassunto del testo, motore di raccomandazione, eccetera. Lo scopo di questo articolo era dimostrare l'applicazione dell'LDA nel testo normale generato dalla folla. dati. Ti incoraggio a implementare il codice in altri set di dati e a condividere i tuoi risultati.
Se hai qualche suggerimento, domande o qualsiasi altra cosa tu voglia condividere sulla modellazione del tema, sentiti libero di usare la sezione commenti qui sotto.
Se stai cercando di entrare nel campo dell'elaborazione del linguaggio naturale, allora abbiamo un videocorso progettato per te che copre la preelaborazione del testo, modellazione del tema, riconoscimento di entità denominate, apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... para PNL y muchos más temas.





