Tipi di apprendimento automatico

1. Apprendimento supervisionato: In un modello di apprendimento supervisionato, l'algoritmo apprende su un set di dati etichettato per generare previsioni attese per la soluzione a nuovi dati.
P.ej; Per la previsione dei prezzi delle case, prima abbiamo bisogno di dati su abitazioni come; piede quadrato, no. di stanze, la casa ha un giardino o no, e così via. Quindi dobbiamo conoscere i prezzi di queste case, In altre parole; etichette di classe. Ora che i dati provengono da centinaia di case, le sue caratteristiche e i suoi prezzi, ora possiamo addestrare un modello di apprendimento automatico supervisionato per prevedere il prezzo di una nuova casa in base alle esperienze passate del modello.
L'apprendimento supervisionato è di due tipi:
un) Classificazione: In Classificazione, un programma per computer si allena su un set di dati di allenamento e, secondo la formazione, categorizzare i dati in diverse etichette di classe. Questo algoritmo viene utilizzato per prevedere i valori discreti come maschio | donna, vero | impostore, spam | niente spam, eccetera.
P.ej; Rilevamento spam, accreditamento vocale, identificazione delle cellule tumorali, eccetera.
Tipi di algoritmi di classificazione:
- Classificatore Naive Bayes
- Alberi decisionali
- Regressione logistica
- K-vicini più vicini
- Supporta macchine vettoriali
- Classificazione casuale delle foreste
B) Regressione: Il compito dell'algoritmo di regressione è trovare la funzione di mappatura per mappare le variabili di input (X) alla variabile di uscita continua (e). Gli algoritmi di regressione vengono utilizzati per prevedere valori continui come il prezzo, stipendio, età, Appunti, eccetera.
P.ej; Previsione del tempo, previsione del prezzo della casa, rilevamento di notizie false, eccetera.
Tipi di algoritmi di regressione:
- Regressione lineare semplice
- Regressione lineare multipla
- regressione polinomiale
- Regressione dell'albero decisionale
- Regressione casuale della foresta
- Imposta metodo
2. Apprendimento non supervisionato: In un modello di apprendimento non supervisionato, l'algoritmo apprende su un set di dati non etichettato e cerca di dare un senso estraendo caratteristiche, co-occorrenza e modelli sottostanti da soli.
P.ej; Rilevamento anomalie, compreso il rilevamento delle frodi. Un altro esempio è l'apertura di ospedali di emergenza nelle aree a più alto rischio di incidenti.. Clustering K-means raggrupperà queste posizioni dell'area massima incline in cluster e definirà un centro di cluster (In altre parole, Ospedale) per ogni gruppo (In altre parole, aree soggette a incidenti).
Tipi di apprendimento non supervisionato:
- Raggruppamento
- Rilevamento anomalie
- Associazione
- Codificatori per auto
- Modelli variabili latenti
- Reti neurali
3. Insegnamento rafforzativo: L'apprendimento per rinforzo è un tipo di apprendimento automatico in cui il modello impara a comportarsi in un ambiente eseguendo alcune azioni e analizzando le reazioni. RL adotta le misure appropriate per massimizzare la soluzione positiva nella situazione particolare. Il modello di rinforzo decide quali azioni intraprendere per eseguire un determinato compito, per questo è obbligato ad imparare dall'esperienza stessa.
P.ej; Facciamo un esempio di un bambino che impara a camminare. Nel primo caso, quando il bambino inizia a camminare e raggiunge il cioccolato dato che il cioccolato è l'obiettivo finale del bambino e la soluzione di un bambino è positiva dato che è felice. Nel secondo caso, quando il bambino inizia a camminare e mentre cammina viene investito dalla sedia e non riesce a prendere il cioccolato, inizia a piangere, che è una risposta negativa. In altre parole, come gli umani imparano dalla traccia e dall'errore. Qui, il bambino è il “agente”, il cioccolato è il “ricompensa” e molti ostacoli in mezzo. Ora l'agente prova in vari modi e scopre il miglior modo fattibile per ottenere la ricompensa.
Ciclo di vita dell'apprendimento automatico
L'apprendimento automatico aiuta ad aumentare le prestazioni e la produttività delle attività. Include l'apprendimento e l'autocorrezione quando vengono presentati nuovi dati.
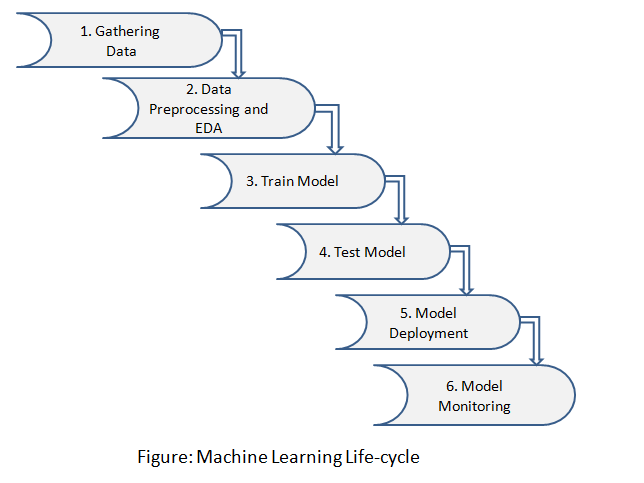
Il ciclo di vita dell'apprendimento automatico prevede sei fasi principali:
passo 1: raccolta dati
Identifica più fonti di dati come Kaggle e raccogli il set di dati richiesto
passo 2: pre-elaborazione dei dati e EDA
In questo passaggio, facciamo un'analisi dei dati alla ricerca dei valori mancanti, dati duplicati, dati non validi utilizzando diverse tecniche analitiche. E anche pre-elaborare i dati per l'estrazione delle funzionalità, analisi delle caratteristiche e visualizzazione dei dati.
passo 3: modellino di treno
Utilizziamo un set di dati per addestrare il modello utilizzando vari algoritmi di apprendimento automatico. La formazione di un modello è essenziale in modo che possa comprendere i vari modelli, regole e caratteristiche.
passo 4: modello di prova
In questo passaggio, verifichiamo l'accuratezza del nostro modello fornendo un set di dati di test al modello addestrato.
passo 5: Implementazione del modello
L'implementazione del modello significa integrare un modello di apprendimento automatico in un ambiente di produzione esistente che accetta input e restituisce risultati per prendere decisioni aziendali basate sui dati. Sono elencate diverse tecnologie che puoi utilizzare per mettere in pratica i tuoi modelli di machine learning.:
- Stivaggio
- governatori
- AWS SageMaker
- MLflusso
- Servizio Azure Machine Learning
passo 6: Monitoraggio del modello
Dopo l'implementazione del modello, ecco che arriva il monitoraggio del modello che monitora i tuoi modelli di apprendimento automatico per fattori come errori, guasti e latenza e, il più importante, per garantire che il tuo modello mantenga le prestazioni desiderate. Il monitoraggio del modello è molto importante poiché i tuoi modelli si degraderanno nel tempo a causa di vari fattori, come dati invisibili, cambiamenti nell'ambiente e relazioni tra variabili.
Alcune applicazioni del machine learning nel mondo reale
- Traduzione automatica della lingua in Google Translate
- Selezione più rapida del percorso nel motore di ricerca di Google Map
- Auto senza conducente / autonomo
- Smartphone con riconoscimento facciale
- Accreditamento vocale
- Sistema di raccomandazione degli annunci
- Sistema di raccomandazione Netflix
- Suggerimento di tag automatico degli amici su Facebook
- Negoziazione in borsa
- Intercettazione di una frode
- Previsione del tempo
- Diagnostica medica
- Chatbot
- Apprendimento automatico in agricoltura
Vantaggi dell'apprendimento automatico
- Automazione del lavoro
- Potente capacità predittiva
- Aumento delle vendite nel mercato dell'e-commerce.
- Vantaggi dell'AA in ambito medico per guidare la diagnosi medica e lo sviluppo di farmaci
- L'apprendimento automatico è utilizzato nella chirurgia medica robotica
- Il machine learning in finanza aumenta la produttività migliora i ricavi e fornisce transazioni sicure
- Modella i dati per prendere decisioni utili
Riepilogo
L'apprendimento automatico può essere utilizzato in quasi tutti i settori della vita umana per svolgere il nostro lavoro efficiente, robusto, e Senza complicazioni. Come sappiamo, tutto ha i suoi pro e contro, Anche il machine learning ha i suoi lati negativi, come esempio, con l'avvento del machine learning, molte persone potrebbero perdere il loro attuale lavoro sul palco. Ma più in tono ampolloso è benefico a lungo termine per umanità.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





