El árbol comienza con el nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... raíz que consta de los datos completos y, successivamente, utilizzare strategie intelligenti per dividere i nodi in più rami.
Il set di dati originale è stato diviso in sottoinsiemi in questo processo.
Per rispondere alla domanda fondamentale, il tuo cervello inconscio fa dei calcoli (alla luce delle domande campione registrate di seguito) e finisce per comprare la quantità di latte necessaria. È normale o durante la settimana?
Nei giorni lavorativi che richiediamo 1 litro di latte.
È un fine settimana? Nei fine settimana abbiamo bisogno 1,5 litri di latte.
È corretto dire che oggi anticipiamo gli ospiti? dobbiamo comprare 250 ML di latte aggiuntivi per ogni ospite, e così via.
Prima di saltare all'ipotetica idea degli alberi delle decisioni, Che ne dici di spiegare inizialmente cosa sono gli alberi decisionali?? è più, Perché sarebbe una buona idea per noi usarli??
Perché usare gli alberi decisionali??
Entre otros métodos de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in..., gli algoritmi basati su alberi eccellono. Questi sono modelli predittivi con maggiore precisione e semplice comprensione.
Come funziona l'albero decisionale??
Esistono diversi algoritmi scritti per assemblare un albero decisionale, che può essere utilizzato per il problema.
Alcuni degli algoritmi più comunemente usati sono elencati di seguito:
• CARRELLO
• ID3
• DO4,5
• CHAID
Ora spiegheremo passo dopo passo l'algoritmo CHAID. Prima di ciò, parleremo un po di chi_square.
chi_square
Chi-Cuadrado es una misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... estadística para encontrar la diferencia entre los nodos secundarios y principales. Per calcolare questo, encontramos la diferencia entre los conteos observados y esperados de la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... objetivo para cada nodo y la suma al cuadrado de estas diferencias estandarizadas nos dará el valor de Chi-cuadrado.
Formula
Per trovare la caratteristica più dominante, utilizzeranno i test chi-quadrato che è anche chiamato CHAID, mentre ID3 utilizza il guadagno di informazioni, C4.5 usa la relación de ganancia y CART usa el indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... GINI.
Oggi, la maggior parte delle librerie di programmazione (ad esempio, Panda per Python) usa la metrica di Pearson per la correlazione per impostazione predefinita.
La formula del chi quadrato: –
? ((e – e ')2 / e ')
dove ed è reale e atteso e '.
Set di dati
Creiamo regole decisionali per il set di dati seguente. La colonna delle decisioni è l'obiettivo che vorremmo trovare in base ad alcune funzionalità.
A proposito, Ignoreremo la colonna del giorno perché è solo il numero di riga.
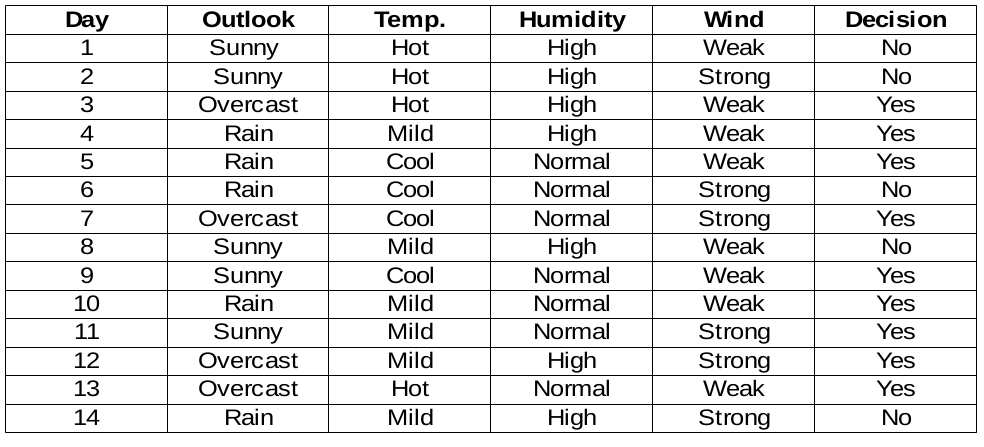
Per leggere il set di dati di implementazione Python dal file CSV riportato di seguito: –
import pandas as pd
data = pd.read_csv("set di dati.csv")
data.head()
Dobbiamo trovare la funzionalità più importante nelle colonne di destinazione per scegliere il nodo per dividere i dati in questo set di dati.
Caratteristica dell'umidità
Esistono due tipi di classe presenti nelle colonne di umidità: alto e normale. Ora calcoleremo i valori chi_square per loro.
| sì | No | Totale | Previsto | Chi-quadrato Sì | Chi-quadrato No | |
| Alto | 3 | 4 | 7 | 3,5 | 0,267 | 0,267 |
| basso | 6 | 1 | 7 | 3,5 | 1.336 | 1.336 |
per ogni riga, la colonna totale è la somma delle decisioni sì e no. La metà della colonna totale è chiamata valori attesi perché c'è 2 classi in decisione. È facile calcolare i valori del chi quadrato in base a questa tabella..
Ad esempio,
chi-quadrato sì per alta umidità è √ ((3– 3,5)2 / 3,5) = 0,267
mentre quello vero è 3 e il previsto è 3,5.
Quindi, il valore chi-quadrato della caratteristica di umidità è
= 0,267 + 0,267 + 1,336 + 1,336
= 3.207
Ora, troveremo anche valori chi-quadrato per altre caratteristiche. La caratteristica con il valore chi-quadrato massimo sarà il punto di decisione. Che dire della funzione vento??
Caratteristica del vento
Ci sono due tipi della classe presenti nelle colonne del vento: debole e forte. La tabella seguente è la tabella seguente.
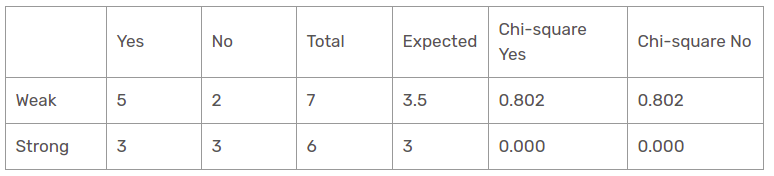
Qui, il valore del test chi-quadrato della caratteristica del vento è
= 0,802 + 0,802 + 0 + 0
= 1,604
Anche questo è un valore inferiore al valore chi-quadrato dell'umidità. E la funzione temperatura??
caratteristica di temperatura
Ci sono tre tipi di classe presenti nelle colonne della temperatura: piccante, freddo e liscio. La tabella seguente è la tabella seguente.
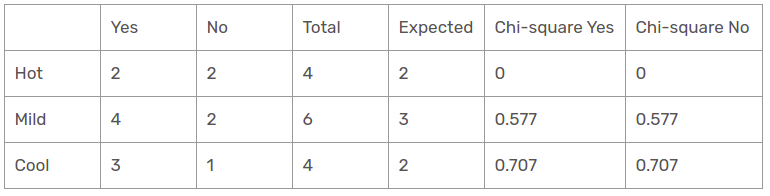
Qui, il valore del test chi-quadrato della caratteristica di temperatura è
= 0 + 0 + 0,577 + 0,577 + 0,707 + 0,707
= 2.569
Questo è un valore inferiore al valore chi-quadrato dell'umidità e anche maggiore del valore chi_quadrato del vento. Che dire della funzione Outlook??
Funzionalità di Outlook
Ci sono tre tipi di classi presenti nelle colonne di temperatura: soleggiato, piovoso e nuvoloso. La tabella seguente è la tabella seguente.
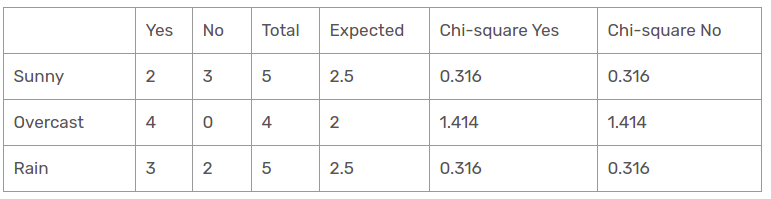
Qui, il valore del test chi-quadrato della funzione prospettica è
= 0,316 + 0,316 + 1,414 + 1,414 + 0,316 + 0,316
= 4.092
Abbiamo calcolato i valori del chi quadrato di tutte le caratteristiche. Vediamoli tutti a tavola.
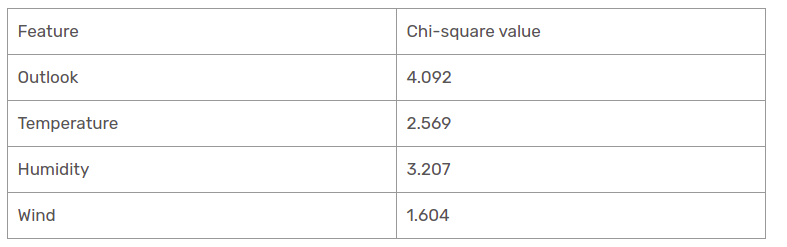
Come appare, la colonna Outlook ha il valore chi-quadrato più alto e più alto. Ciò implica che è la caratteristica principale del componente. Insieme a questi valori, posizioneremo questa funzione nel nodo radice.
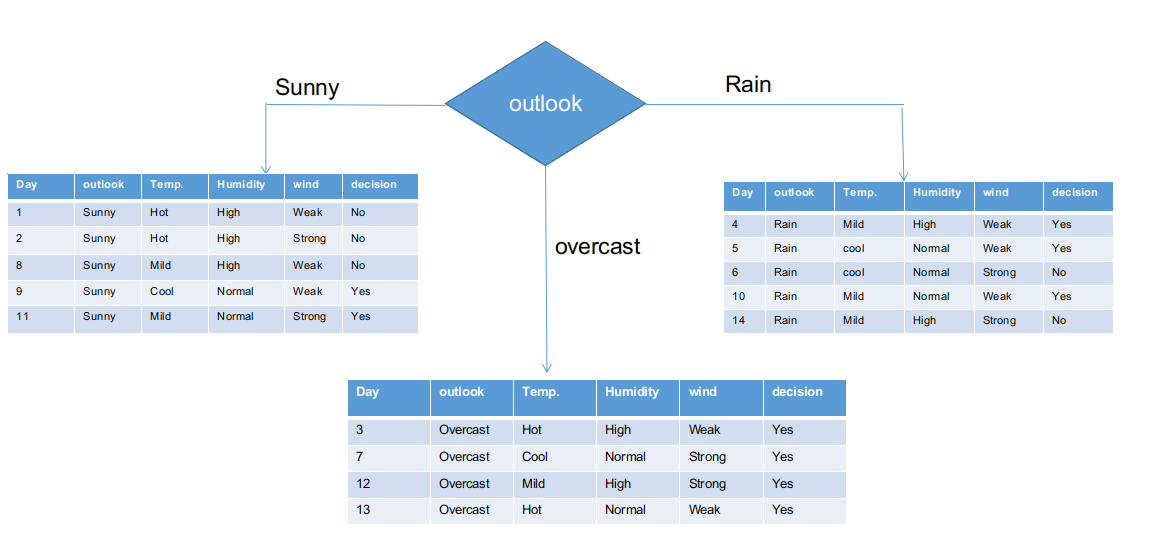
Abbiamo separato le informazioni grezze in base alle classi di Outlook nell'illustrazione sopra. Ad esempio, il ramo offuscato ha semplicemente una decisione affermativa sul set di dati di sottoinformazioni. Ciò implica che l'albero CHAID restituisce S se il panorama è nuvoloso.
Sia i rami soleggiati che quelli piovosi hanno decisioni sì e no. Applicheremo i test chi-quadrato per questi set di dati subinformativi.
Outlook = ramo soleggiato
Questo ramo ha 5 esempi. Attualmente, cerchiamo la caratteristica più predominante. A proposito, ignoreremo la funzione di Outlook ora, visto che sono completamente uguali. Alla fine del giorno, troveremo le colonne più predominanti tra temperature, umidità e vento.
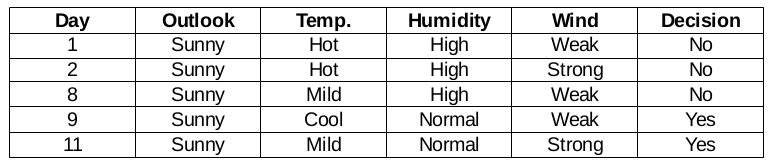
Funzione umidità per quando il panorama è soleggiato
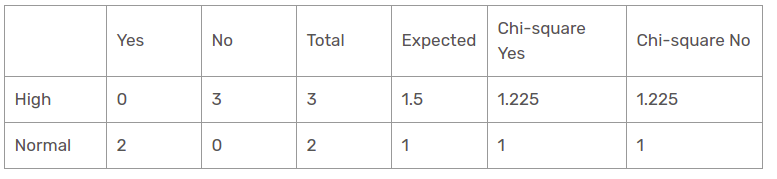
Il valore chi-quadrato della caratteristica di umidità per una prospettiva soleggiata è
= 1,225 + 1,225 + 1 + 1
= 4.449
Funzione vento per quando il panorama è soleggiato
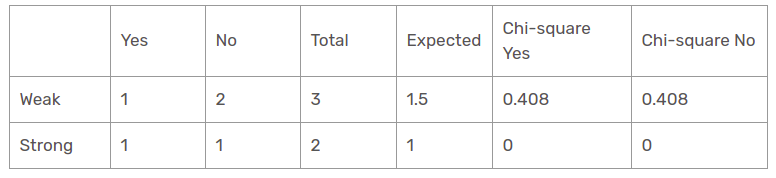
Il valore chi-quadrato della caratteristica del vento per la prospettiva soleggiata è
= 0,408 + 0,408 + 0 + 0
= 0,816
Funzione temperatura per quando il panorama è soleggiato
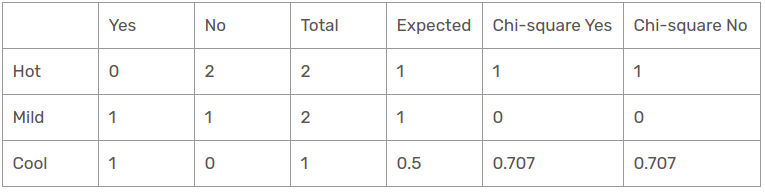
Quindi, il valore chi-quadrato della caratteristica di temperatura per la prospettiva soleggiata è
= 1 + 1 + 0 + 0 + 0,707 + 0,707
= 3.414
Abbiamo trovato i valori del chi quadrato per la prospettiva soleggiata. Vediamoli tutti a tavola.
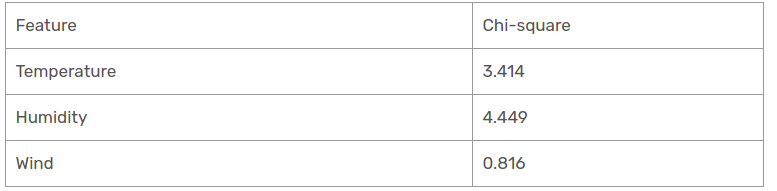
Attualmente, l'umidità è la caratteristica predominante del ramo soleggiato del gazebo. Metteremo questa caratteristica come regola di decisione.
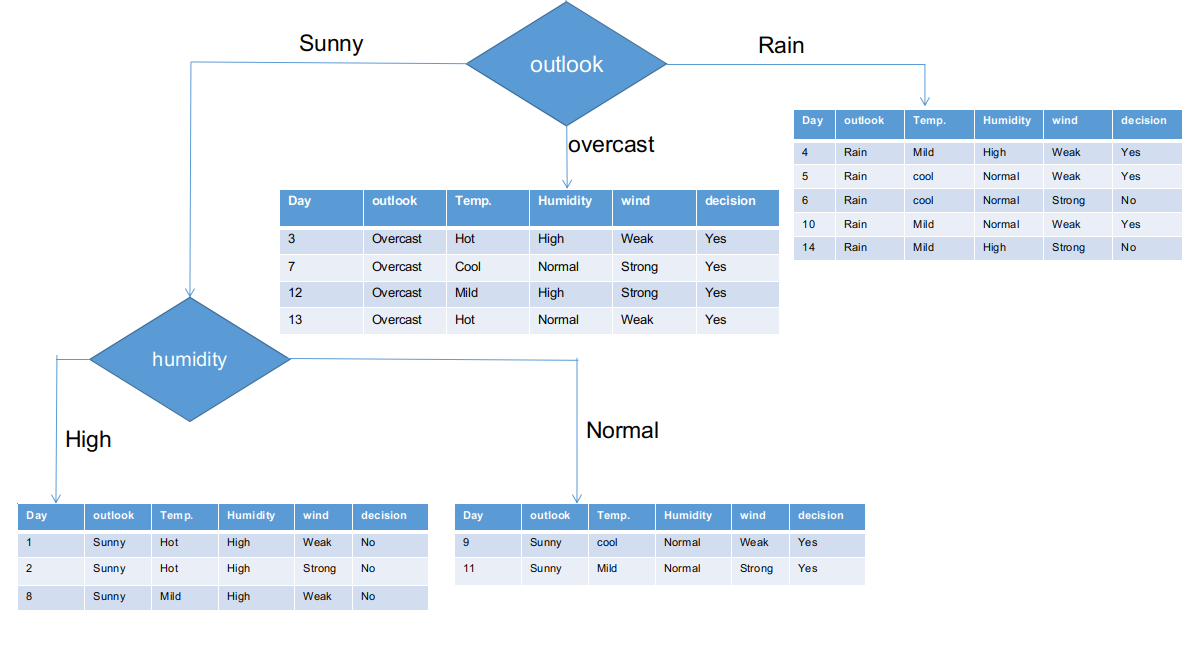
Attualmente, entrambi i rami dell'umidità per la prospettiva soleggiata hanno una sola decisione come descritto sopra. L'albero CHAID restituirà NO per una prospettiva soleggiata e un'umidità elevata e restituirà S per una prospettiva soleggiata e un'umidità normale.
Ramo prospettico pioggia
In realtà, questo ramo ha decisioni sia positive che negative. Dobbiamo applicare il test chi-quadrato per questo ramo per trovare una decisione accurata. Questo ramo ha 5 istanze diverse, come dimostrato nel set di dati di raccolta delle sottoinformazioni allegato. Che ne dici di scoprire la caratteristica più predominante tra la temperatura?, umidità e vento?
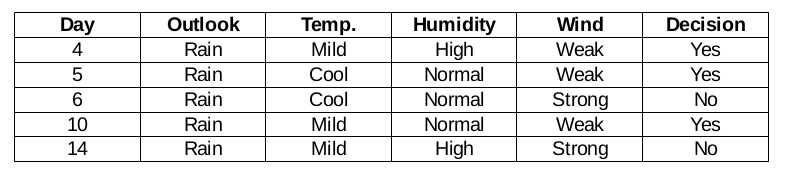
Funzione vento per previsione pioggia
Ci sono due tipi di una classe presente nella caratteristica del vento per la prospettiva della pioggia: debole e forte.
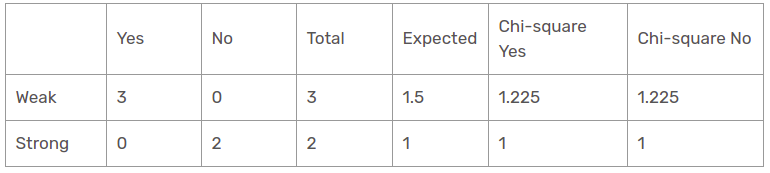
Quindi, il valore chi-quadrato della caratteristica del vento per la prospettiva della pioggia è
= 1,225 + 1,225 + 1 + 1
= 4.449
Funzione umidità per previsione pioggia
Ci sono due tipi di una classe presente nella caratteristica di umidità per la prospettiva della pioggia: alto e normale.
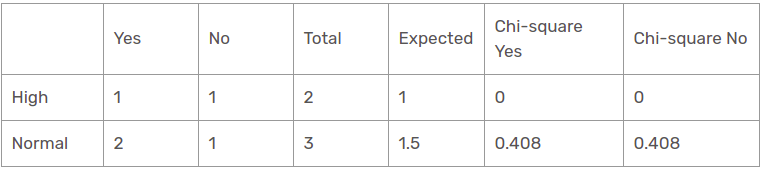
Il valore chi-quadrato della caratteristica di umidità per la prospettiva della pioggia è
= 0 + 0 + 0.408 + 0.408
= 0,816
Caratteristica della temperatura per la previsione della pioggia
Ci sono due tipi di classi presenti nelle caratteristiche di temperatura per la prospettiva della pioggia, come caldo e freddo.

Il valore chi-quadrato della caratteristica di temperatura per la prospettiva della pioggia è
= 0 + 0 + 0.408 + 0.408
= 0,816
Abbiamo scoperto che tutti i valori del chi quadrato per la pioggia sono il ramo prospettico. Vediamoli tutti ad un unico tavolo.
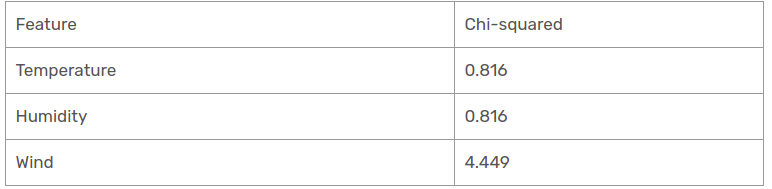
Perciò, la funzione del vento è il vincitore della pioggia è il ramo della prospettiva. Inserire questa colonna nel ramo connesso e visualizzare il dataset subinformativo corrispondente.
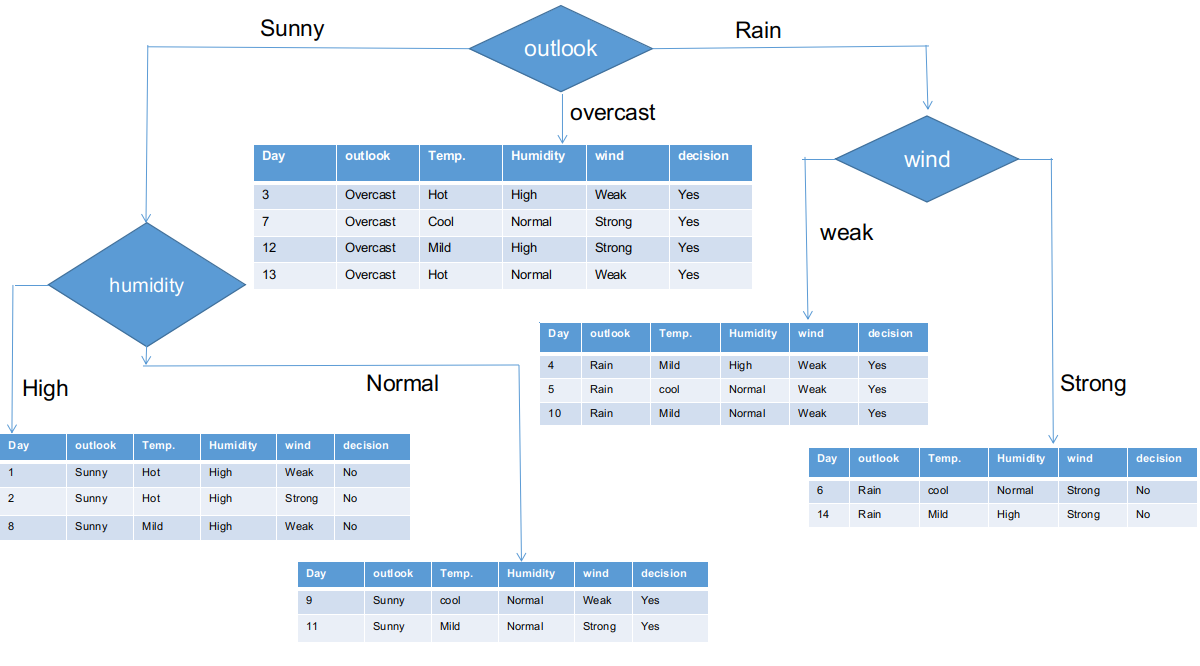
Come appare, Tutte le succursali dispongono di set di dati sub-informativi con un'unica decisione, come sì o no. In questo modo, possiamo generare l'albero CHAID come illustrato di seguito.
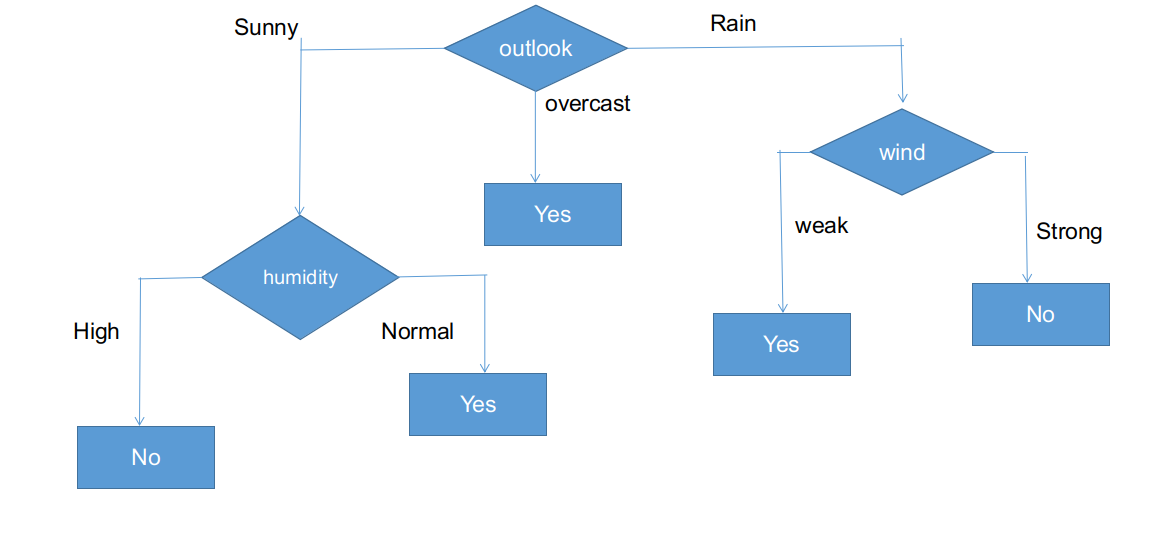
La forma finale dell'albero CHAID.
Implementazione Python di un albero decisionale utilizzando CHAID
from chefboost import Chefboost as cb
import pandas as pd
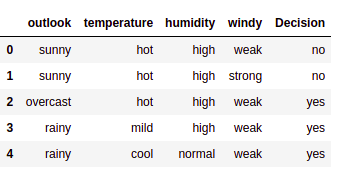
data = pd.read_csv("/home/kajal/Download/meteo.csv")
data.head()
config = {"algoritmo": "CHAID"}
albero = cb.fit(dati, config)

albero
# test_instance = ['soleggiato','caldo','alto','debole','no'] test_instance = data.iloc[2] test_instance
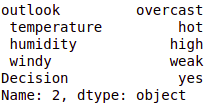
cb.predict(albero,test_instance) produzione:- 'Yes' #obj[0]: prospettiva, ogg[1]: temperatura, ogg[2]: umidità, ogg[3]: ventoso # {"caratteristica": "prospettiva", "Istanze": 14, "metric_value": 4.0933, "profondità": 1} def findDecisione(ogg): se obj[0] == 'piovoso': # {"caratteristica": " ventoso", "Istanze": 5, "metric_value": 4.4495, "profondità": 2} se obj[3] == 'debole': return 'yes' elif obj[3] == 'forte': return 'no' else: return 'no' elif obj[0] == 'soleggiato': # {"caratteristica": " umidità", "Istanze": 5, "metric_value": 4.4495, "profondità": 2} se obj[2] == 'alto': return 'no' elif obj[2] == 'normale': return 'yes' else: return 'yes' elif obj[0] == 'nuvoloso': return 'yes' else: restituisci 'sì'
conclusione
Perciò, hemos creado un árbol de decisiones CHAID desde cero para terminar en esta publicación. CHAID utilizza una metrica di misurazione chi-quadrato per scoprire la caratteristica più importante e applicarla in modo ricorsivo fino a quando i set di dati sub-informativi non hanno un'unica decisione. Sebbene sia un algoritmo di albero decisionale legacy, è sempre lo stesso processo per l'ordinamento dei problemi.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





