I dati vengono generati in grandi quantità ovunque. Twitter genera più di 12 TB di dati ogni giorno, Facebook genera più di 25 TB di dati ogni giorno e Google genera ogni giorno molto di più di queste quantità. Poiché questi dati vengono prodotti ogni giorno, Abbiamo bisogno di creare strumenti per gestire i dati con un alto
1. Volume : Oggi vengono archiviati grandi volumi di dati per qualsiasi settore. I modelli convenzionali con dati così grandi non sono fattibili.
2. Velocità : I dati arrivano ad alta velocità e richiedono algoritmi di apprendimento più rapidi.
3. Varietà : Origini dati diverse hanno strutture diverse. Tutti questi dati contribuiscono alla previsione. Un buon algoritmo può assorbire una tale varietà di dati.
Un semplice algoritmo predittivo come Random Forest in circa 50 migliaia di punti dati e 100 Dimensioni Takes 10 minuti per l'esecuzione su una macchina 12 GB di RAM. I problemi con centinaia di milioni di osservazioni sono semplicemente impossibili da risolvere con questi tipi di macchine. Perché, Ci rimangono solo due opzioni: Usa una macchina più potente o cambia il modo in cui funziona un algoritmo predittivo. La prima opzione non è sempre praticabile. In questo post, Impareremo a conoscere gli algoritmi di apprendimento online che hanno lo scopo di gestire dati con un volume e una velocità così elevati con macchine a prestazioni limitate.
In che modo l'apprendimento online è diverso dagli algoritmi di apprendimento in batch??
Se sei un principiante nel analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche...., Tutto ciò di cui probabilmente hai sentito parlare rientrerà nella categoria dell'apprendimento in batch. Proviamo a visualizzare in che modo i due funzionano in modo diverso.
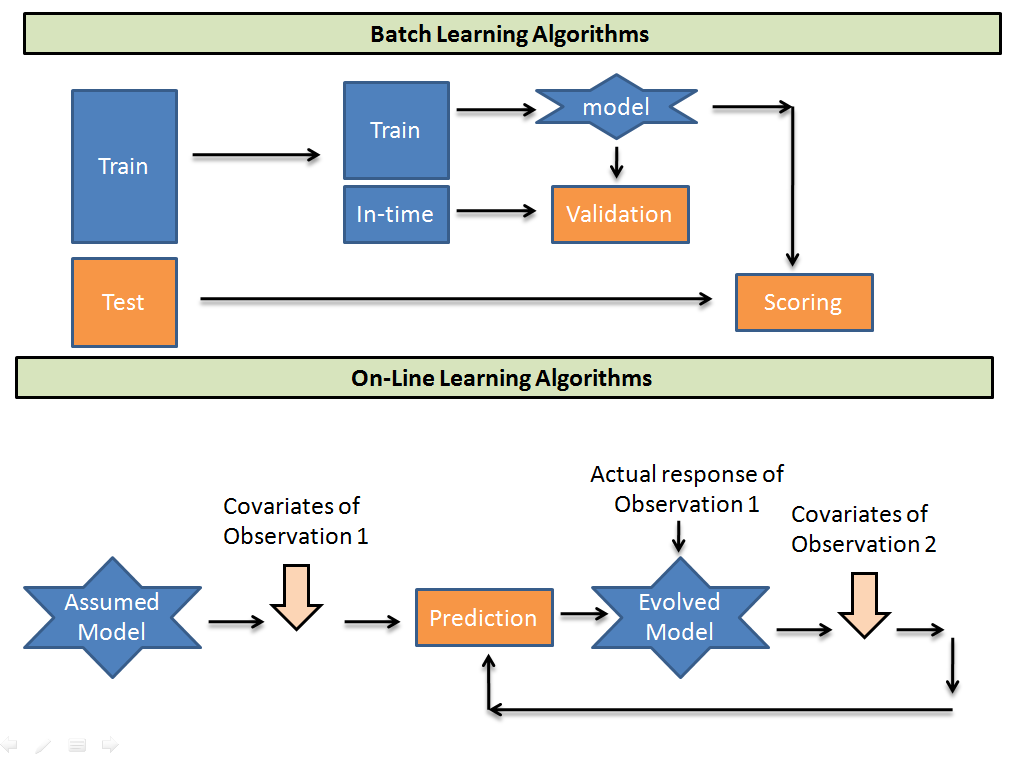
Gli algoritmi di apprendimento batch prendono batch di dati da addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... Per eseguire il training di un modello. Quindi prevede il campione di test utilizzando il collegamento trovato. Considerando che, Gli algoritmi di e-learning prendono un modello di ipotesi iniziale e poi prendono l'osservazione one-to-one della popolazione di addestramento e ricalibrano i pesi su ciascun parametro di input. Di seguito sono riportati alcuni compromessi quando si utilizzano i due algoritmi.
- Computazionalmente molto più veloce ed efficiente nello spazio. Nel modello online, Puoi fare esattamente un passaggio dei tuoi dati, Quindi questi algoritmi sono generalmente molto più veloci dei loro equivalenti di apprendimento batch, Poiché la maggior parte degli algoritmi di apprendimento batch sono multi-pass. Allo stesso tempo, Dal momento che non puoi riconsiderare i tuoi esempi precedenti, regolarmente non li memorizza per inserirli successivamente nella procedura di apprendimento, il che significa che tende a utilizzare un ingombro di memoria più piccolo.
- Di solito è più facile da mettere in pratica. Dal momento che il modello online fa passare sopra i dati, Finiamo per elaborare un esempio allo stesso tempo, sequenzialmente, un misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che entrano dal flusso. Questo generalmente semplifica l'algoritmo, se lo fai da zero.
- Più difficile da mantenere in produzione. L'implementazione di algoritmi online in produzione richiede in genere che si disponga di un elemento che passi costantemente i punti dati all'algoritmo. Se i dati cambiano e i selettori di funzione non producono più risultati utili, o se c'è una latenza di rete significativa tra i server dei selettori di funzione, o uno di questi server si interrompe, o addirittura, un numero qualsiasi di altre cose, Il tuo apprendista accumula e la tua produzione è spazzatura. Assicurarsi che tutto questo funzioni correttamente può essere un test.
- Più difficile da esaminare online. Nell'apprendimento online, Non possiamo offrire una serie di “test” per la valutazione perché non facciamo ipotesi di distribuzione; Se scegliamo un insieme da esaminare, Daremmo per scontato che il set di test sia rappresentativo dei dati che stiamo operando, E questa è un'ipotesi distributiva. dato che, nel caso più generale, Non c'è modo di ottenere un set rappresentativo che caratterizzi i tuoi dati, La tua unica opzione (ancora, nel caso più generale) Si tratta semplicemente di osservare quanto bene l'algoritmo ha funzionato di recente.
- Generalmente, È più difficile farlo “Buona”. Come abbiamo visto nell'ultimo punto, La valutazione degli studenti online è difficile. Per motivi simili, Può essere molto difficile far sì che l'algoritmo si comporti “correttamente” automaticamente. Può essere difficile diagnosticare se l'algoritmo o l'infrastruttura si comportano in modo anomalo.
Dove lavoriamo con grandi quantità di dati, Non abbiamo altra scelta che utilizzare algoritmi di apprendimento online. L'unica altra alternativa consiste nell'eseguire l'apprendimento batch su un campione più piccolo.
Esempio di caso per conoscere il concetto
Vogliamo prevedere la probabilità di pioggia oggi. Abbiamo un pannelloUn panel è un gruppo di esperti che si riunisce per discutere e analizzare un argomento specifico. Questi forum sono comuni alle conferenze, seminari e dibattiti pubblici, dove i partecipanti condividono le loro conoscenze e prospettive. I pannelli possono riguardare una varietà di aree, Dalla scienza alla politica, e il suo obiettivo è quello di favorire lo scambio di idee e la riflessione critica tra i partecipanti.... a partire dal 11 Persone che prevedono la classe: Pioggia e non pioggia in diversi parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto..... Dobbiamo progettare un algoritmo per prevedere la probabilità. Inizializziamo prima alcune denotazioni.
Sono predittori individuali
w (io) è il peso attribuito all'i-esimo predittore
Iniziale w (io) per me in [1,11] Sono tutti 1
Prevediamo che oggi pioverà se,
Somma (w (io) per tutte le previsioni di pioggia)> Suma (w (io) per tutti i pronostici senza pioggia)
Una volta che abbiamo la vera soluzione del variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... obbiettivo, Ora inviamo un feedback sui pesi di tutti i parametri. In questa circostanza prenderemo un meccanismo di feedback molto semplice. Per ogni previsione corretta, Manterremo lo stesso peso del predittore. Mentre per ogni previsione sbagliata, Dividiamo il peso del predittore per 1,2 (tasso di apprendimento). Col tempo, Ci aspettiamo che il modello converga con un set corretto di parametri. Creiamo una simulazione con 1000 previsioni fatte da ciascuno dei 11 predittori. Ecco come è venuta fuori la nostra curva di precisione,
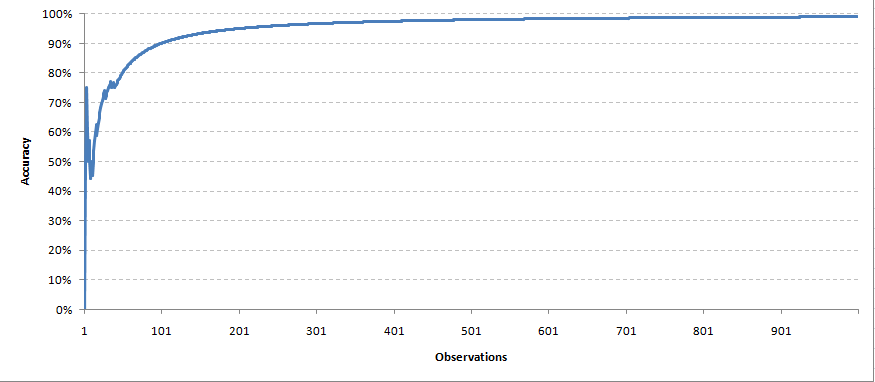
Ogni osservazione è stata effettuata contemporaneamente per riaggiustare i pesi. Nello stesso modo, Faremo previsioni per i punti dati futuri.
Note finali
Gli algoritmi di apprendimento online sono ampiamente utilizzati dall'industria dell'e-commerce e dei social media. Non solo è veloce, ma ha anche la capacità di catturare eventuali nuove tendenze visibili nel tempo. Attualmente è disponibile una gamma di sistemi di feedback e algoritmi convergenti che devono essere selezionati in base alle esigenze. In alcuni dei seguenti post, Prenderemo anche alcuni esempi pratici di applicazioni degli algoritmi di apprendimento online.
Il post ti è stato utile?? Hai già utilizzato algoritmi di apprendimento online? Condividi queste esperienze con noi. Fateci sapere i vostri pensieri su questo post nella casella qui sotto..





