Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
Cos'è l'apprendimento automatico??
Apprendimento automatico: Apprendimento automatico (ML) è un processo altamente iterativo e ML I modelli vengono appresi dalle esperienze passate e anche per analizzare i dati storici. Cosa c'è di più, I modelli ML possono identificare modelli per fare previsioni sul futuro del set di dati specificato.

WPerché il machine learning è importante?
Dal momento che le 5V stanno dominando il mondo digitale di oggi (volume, varietà, Variazione e visibilità del valore), La maggior parte delle industrie sta sviluppando vari modelli per analizzare la propria presenza e le opportunità di mercato., Sulla base di questo risultato, stanno offrendo i migliori prodotti. Servizi ai tuoi clienti su larga scala.
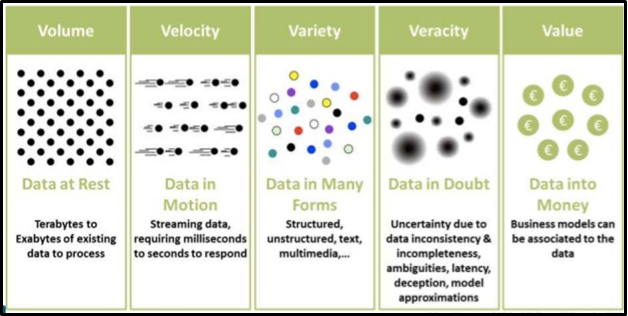
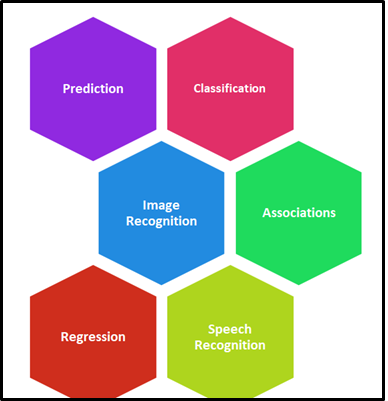
Quali sono le principali applicazioni del machine learning?
Apprendimento automatico (ML) è ampiamente applicabile in molti settori e l'implementazione e il miglioramento dei loro processi. Attualmente, Il ML è stato utilizzato in molteplici campi e settori senza limiti. La figura seguente rappresenta l'area in cui il ML svolge un ruolo vitale..
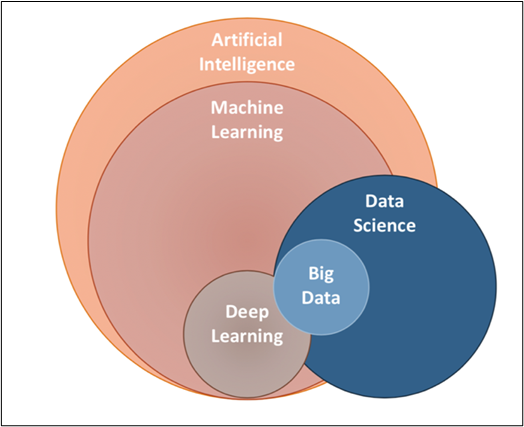
Dov'è l'apprendimento automatico nello spazio AI??
Basta dare un'occhiata al Diagramma di Venn, potremmo capire dove si trova il ML nello spazio AI e come si relaziona con altri componenti dell'AI..
Come sappiamo i gerghi che volano intorno a noi, Vediamo rapidamente di cosa parla esattamente ogni componente.
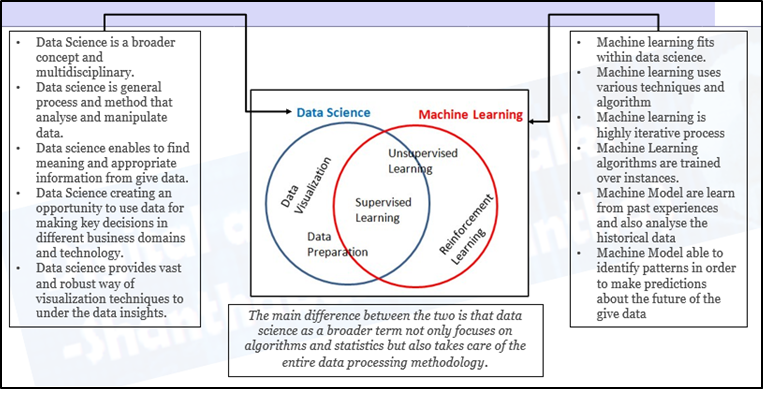
In che modo la scienza dei dati e l'apprendimento automatico sono correlati?
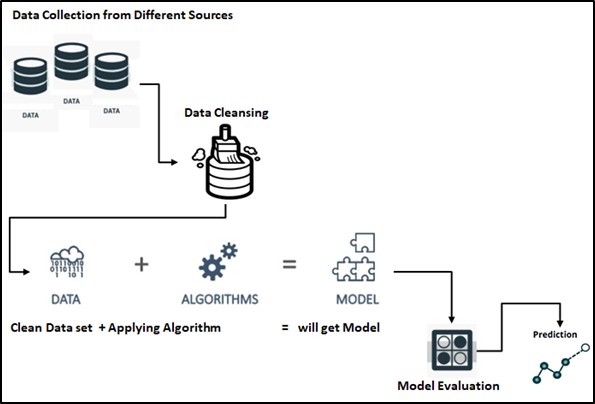
Processo di Machine Learning, è il primo passo nel processo ML per prendere dati da più fonti e seguito da un processo di dati ottimizzati, questi dati sarebbero la fonte per gli algoritmi ML basati sulla dichiarazione del problema, come i modelli predittivi, classificazione e altri che sono disponibili nello spazio mondiale ML. Discutiamo ogni processo uno per uno qui.
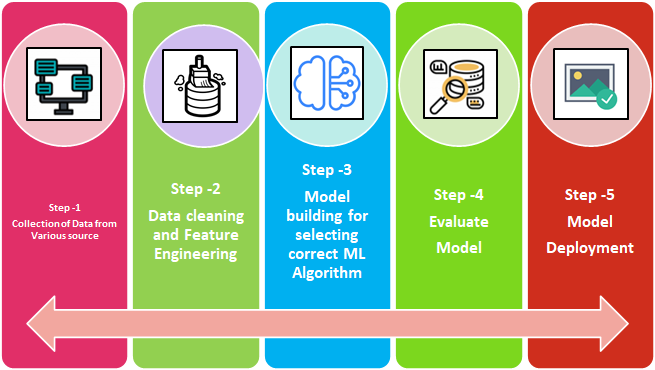
Apprendimento automatico – Etapas: Possiamo dividere le fasi del processo ML in 5 Come indicato di seguito nel diagramma di flusso.
- Set di dati
- Negoziazione dei dati
- Costruzione del modello
- Evaluación del modelo
- Distribuzione del modello
Individuazione dei problemi commerciali, Prima di passare alle fasi precedenti. Quindi, dobbiamo essere chiari sull'obiettivo dello scopo dell'attuazione del ML. Trova la soluzione al problema dato / individuato. Dobbiamo raccogliere i dati e tracciare correttamente i prossimi passi.
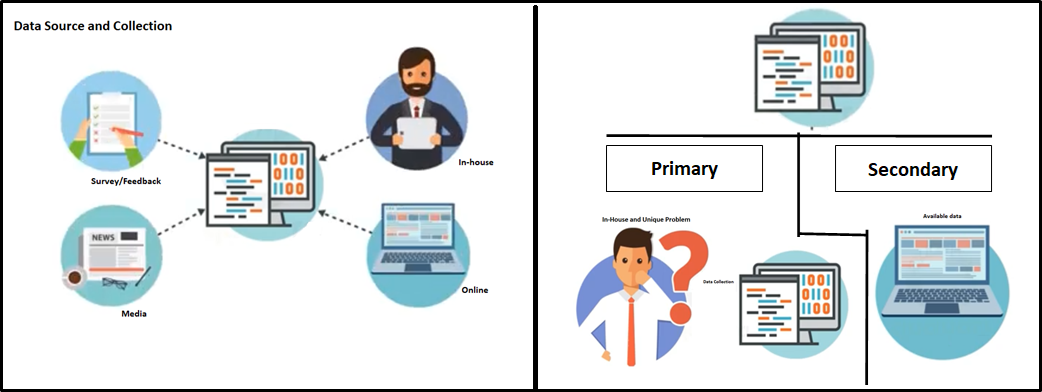
Set di dati
La raccolta di dati da diverse fonti può essere interna e / o esterno per soddisfare i requisiti / Problemi commerciali. I dati possono essere in qualsiasi formato. CSV, XML.JSON, eccetera., qui i Big Data svolgono un ruolo fondamentale nell'assicurarsi che i dati giusti siano nel formato e nella struttura previsti..
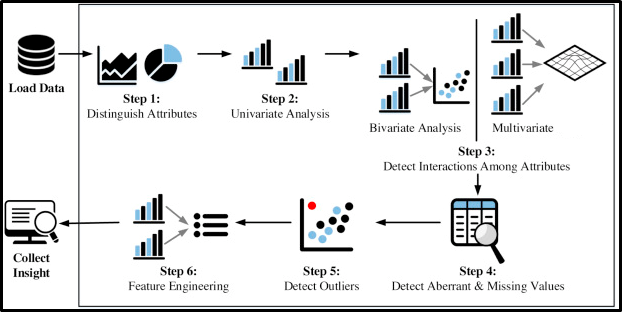
Negoziazione ed elaborazione dei dati: L'obiettivo principale di questa fase e approccio sono i seguenti.
Elaborazione dati (EDA):
- Comprendere il set di dati specificato e contribuire a ripulire il set di dati specificato.
- Ti dà una migliore comprensione delle caratteristiche e delle relazioni tra loro
- Estrai le variabili essenziali e lascia indietro / Eliminare variabili non essenziali.
- Gestione di valori mancanti o errori umani.
- Identificazione dei valori anomali.
- Il processo EDA massimizzerebbe le informazioni da un set di dati.
Ingegneria delle funzioni:
- Gestione dei valori mancanti nelle variabili
- Converti categorico in numerico poiché la maggior parte degli algoritmi richiede caratteristiche numeriche.
- Ha bisogno di una correzione non gaussiana (normale). I modelli lineari assumono che le variabili abbiano distribuzione gaussiana.
- Individuazione dei valori anomali presenti nei dati, Quindi tronchiamo i dati al di sopra di una soglia o trasformiamo i dati trasformando i record.
- Caratteristiche di ridimensionamento. Questo è necessario per dare uguale importanza a tutte le caratteristiche e non più a quelle il cui valore è maggiore..
- La progettazione delle funzionalità è un processo costoso e dispendioso in termini di tempo.
- La progettazione delle funzionalità può essere un processo manuale, può essere automatizzato
Formazione e test:
- I dati di addestramento vengono utilizzati per assicurarsi che la macchina riconosca i modelli nei dati, La convalida incrociata dei dati viene utilizzata per garantire una migliore accuratezza e
l'efficienza dell'algoritmo utilizzato per addestrare la macchina. - I dati di test vengono utilizzati per vedere quanto bene la macchina può prevedere nuove risposte in base all'addestramento..
- La procedura di suddivisione dei test del treno viene utilizzata per stimare le prestazioni ML degli algoritmi quando vengono utilizzati per fare previsioni su
utilizzato per eseguire il training del modello.
Addestramento
- I dati di training sono il set di dati su cui viene eseguito il training del modello.
- Addestrare i dati da cui il modello ha imparato dalle esperienze.
- I set di allenamento vengono utilizzati per regolare e regolare i modelli.
Prova
- I dati di test sono i dati utilizzati per verificare se il modello dispone di
ha imparato abbastanza bene dalle esperienze acquisite nel set di dati Train. - Suite di test
sono dati “Invisibile” per valutare i tuoi modelli.
Dettagli del treno: Addestra il nostro algoritmo di machine learning
Dati di test: Dopo il training del modello, I dati di test vengono utilizzati per testare l'efficienza e le prestazioni del modello.
Lo scopo dello stato casuale nella divisione di prova del treno: Stato casuale garantisce che il divisioni che si generano sono riproducibili. il Stato casuale che fornisci viene utilizzato come seme per il a caso Generatore di numeri. Ciò garantisce che il a caso I numeri vengono generati nello stesso ordine.
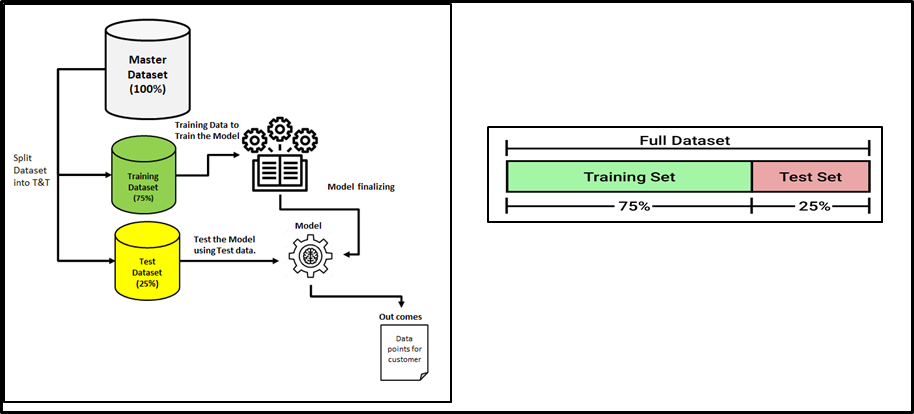
Dati suddivisi in training set / prova
- Eravamo soliti dividere un set di dati in dati di addestramento e dati di test nello spazio di apprendimento automatico..
- L'intervallo diviso è di solito 20% al 80% tra le fasi di test e addestramento del set di dati specificato.
- Molti dati verrebbero spesi per addestrare il tuo modello
- Il resto dell'importo può essere speso per valutare il modello di test.
- Ma non puoi mescolare / riutilizzare gli stessi dati per scopi di formazione e test
- Se si valuta il modello con gli stessi dati utilizzati per il training, Il tuo modello potrebbe essere molto sovradimensionato. Quindi sorge la domanda se i modelli possono prevedere nuovi dati..
- Perciò, Devono avere sottoinsiemi di test e training separati dal set di dati.
VALUTAZIONE DEL MODELLO: Ogni modello ha la sua mitologia di valutazione del modello, Alcune delle migliori recensioni sono qui.
- Valutare Regressione Modello.
- Somma dell'errore al quadrato (SSE)
- Root errore quadratico medio (MSE)
- Root errore quadratico medio (RMSE)
- Errore assoluto medio (Amico)
- Coefficiente di determinazione (R2)
- R2 regolato
- Valutare Classificazione Modello.
- Matrice di confusione.
- Puntuación de precisión.
- AUC e ROC.
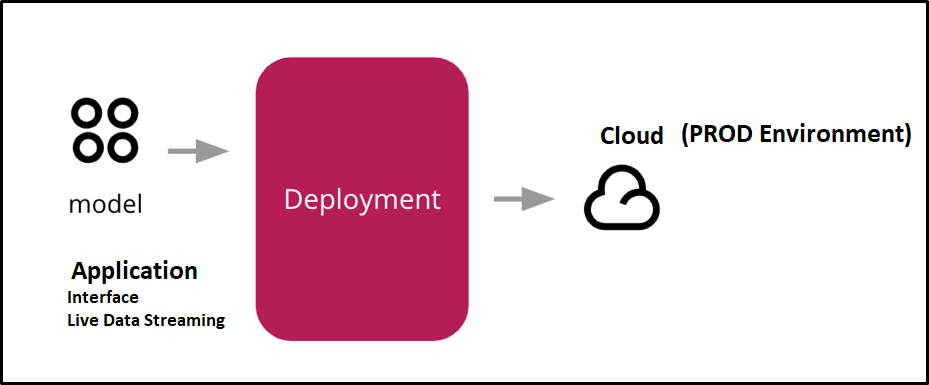
Distribuzione di una ML-Modello significa semplicemente integrare il modello finito in un ambiente di produzione e ottenere risultati per prendere decisioni aziendali..
Perciò, Spero che tu possa capire il flusso di processo end-to-end dell'apprendimento automatico e penso che sarebbe utile per te. Grazie per il tuo tempo.





