Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
L'algoritmo Random Forest è senza dubbio uno degli algoritmi più popolari tra i data scientist.. Funziona alla grande sia su problemi di classificazione che di regressione. La foresta casuale è nota come tecnica di insieme perché è una raccolta di alberi decisionali multipli.
Qual era lo scopo principale dell'utilizzo di più alberi decisionali??
L'utilizzo di un singolo albero decisionale presenta diversi inconvenienti. Quando usiamo un singolo albero decisionale per risolvere una dichiarazione di problema, troviamo una situazione di bassa distorsione e alta varianza. Vale a dire, el árbol capturará toda la información sobre los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., così come il rumore. Di conseguenza, il modello sviluppato utilizzando l'algoritmo dell'albero decisionale funzionerà bene con i dati di addestramento, ma funzionerà male se valutato sui dati del test (dati sconosciuti). L'overfitting è la condizione di avere un bias basso e un'alta varianza.
Albero decisionale -----> Sovrapposizione ————–> bassa deviazione alta varianza
Random Forest utilizza più alberi decisionali per evitare questo problema presente nell'algoritmo dell'albero decisionale.
Ma, In che modo Random Forest affronta il problema del sovradattamento??
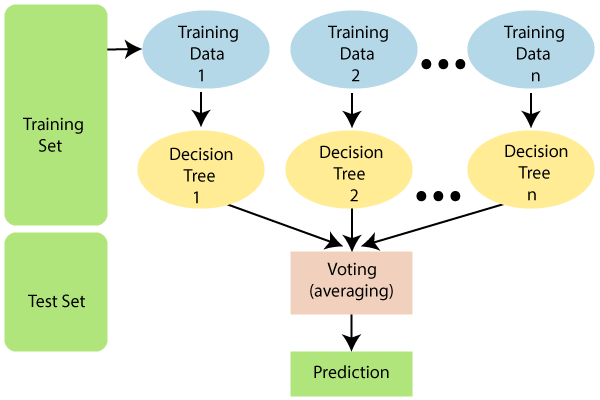
L'algoritmo Random Forest non utilizza tutti i dati di addestramento durante l'addestramento del modello, come si vede nello schema qui sotto. Anziché, campioni di righe e colonne con ripetizione. Ciò significa che ogni albero può essere addestrato solo con un numero limitato di righe e colonne con dati ripetuti. Nel diagramma seguente, dati di allenamento 1 sono usati per addestrare l'albero decisionale 1, e i dati di addestramento n vengono utilizzati per addestrare l'albero decisionale n. tuttavia, poiché ogni albero è creato in tutta la sua profondità e ha la proprietà di sovradattamento, Come evitiamo questo problema??
Poiché l'algoritmo non dipende dal risultato di un particolare albero decisionale. Otterrai prima i risultati di tutti gli alberi decisionali e poi darai il risultato finale in base al tipo di dichiarazione del problema. Ad esempio; se il tipo di affermazione del problema è la classificazione, si utilizzerebbe il voto a maggioranza. supponiamo di classificare “sì” e “no” insieme a 10 alberi, e 6 gli alberi stanno ordinando “sì” e 4 si stanno classificando “no”, la risposta finale sarà “sì” utilizzando il voto a maggioranza. ¿Qué pasa si nuestra salida es una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... continuo? Quindi, el resultado final sería la media o la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... de la producción de todos los árboles.
problema di classificazione -> Voto a maggioranza
Problema di regressione -> Media / Mediano
Il modello esegue il campionamento delle righe. tuttavia, Il campionamento delle caratteristiche dovrebbe essere effettuato in base al tipo di dichiarazione del problema.
- Se il tipo di dichiarazione del problema è “classificazione”.
Il numero totale di funzioni / colonne casuali selezionate = p^ ½ o la radice quadrata di p,
dove p è il numero totale di Indipendente attributi / caratteristiche presenti nei dati.
- Se il tipo di dichiarazione del problema è “regressione”.
Il numero totale di colonne casuali selezionate = P / 3.
Random Forest evita il sovradattamento con: –
1) Esecuzione del campionamento di riga e caratteristica.
2) Connettere tutti gli alberi decisionali in parallelo.
Perché è nota come tecnica di aggregazione Bootstrap?
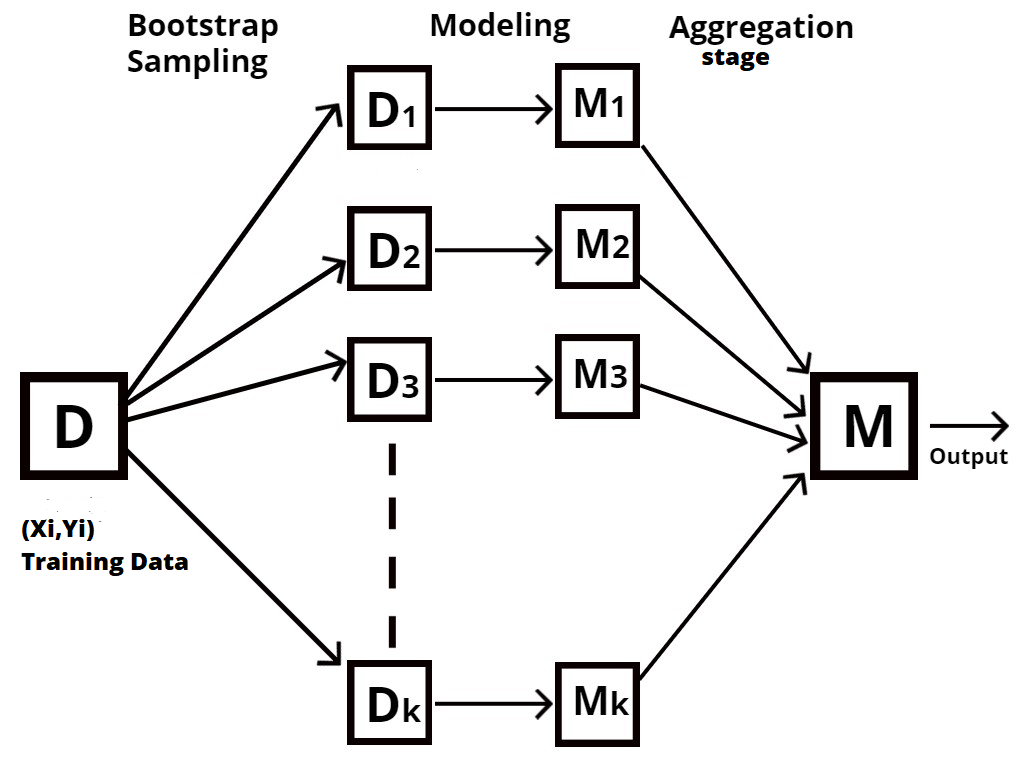
Random Forest è un tipo di tecnica di set, conosciuto anche come aggregazione bootstrap oh harpillera.
Il processo di campionamento di diverse righe e caratteristiche dei dati di addestramento con ripetizione per costruire ogni modello di albero decisionale è noto come bootstrap., come mostrato nel diagramma seguente.
L'aggregazione è il processo che prende tutti i risultati da ciascun albero decisionale e li combina per produrre un risultato finale utilizzando voti di maggioranza o valori medi., a seconda del tipo di affermazione del problema.
Foresta casuale usando R
biblioteca(caTools) biblioteca(casualeForesta)
Dobbiamo installare caTools delle librerie’ y 'randomForest’ e attivarli utilizzando la funzione libreria ()
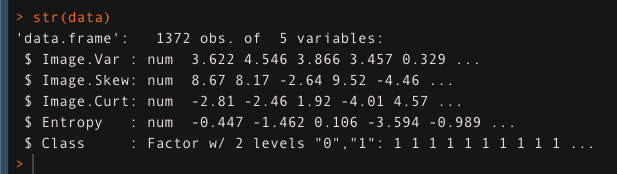
Abbiamo utilizzato il set di dati di autenticazione delle banconote e l'abbiamo memorizzato nella variabile 'data'. Verificheremo la struttura dei dati utilizzando la funzione str ().
dati <- leggi.csv ('banconota_data.csv', intestazione = T)
str (dati)
Ora divideremo i nostri dati in parti di test e di addestramento. 80% per la formazione e 20% per testare il modello.
semi (123)
diviso <- sample.split (dati, Rapporto di divisione = 0.8)
treno <- sottoinsieme (dati, dividere == T)
prova <- sottoinsieme (dati, divisione == F)
Dopo aver diviso i dati, costruiremo il nostro modello usando la funzione randomForest (). Qui 'ntree’ è l'iperparametro. cosa c'è da aggiustare. In questo caso, è selezionato come 500.
modello_casuale <- foresta casuale (Classe ~., dati = treno, metri = 2, nalbero = 500)
Previsione dell'accuratezza del modello sui dati di test utilizzando la funzione di previsione ().
valuta <- prevedere (modello_casuale, prova)
Valutare la precisione del modello utilizzando la matrice di confusione.
confusioneMatrix (tavolo (valuta, prova $ Classe))
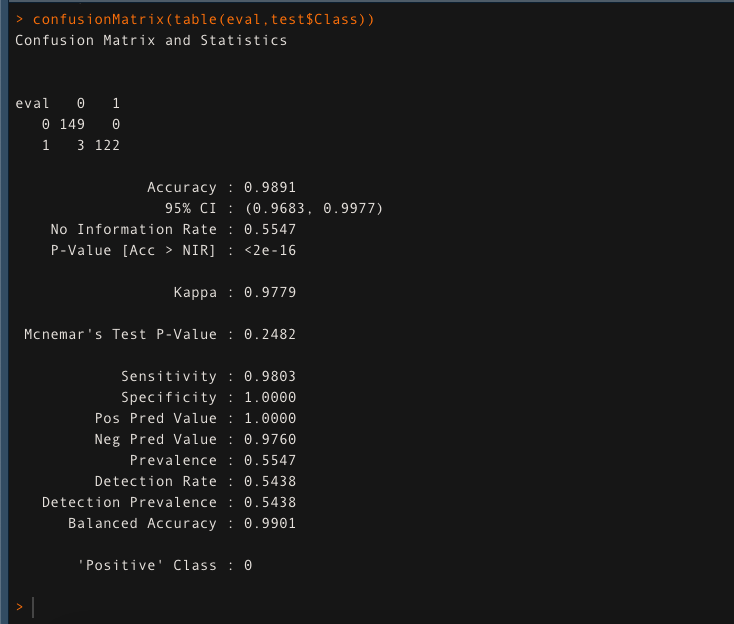
Il modello fornisce una precisione di 98,91% nei dati di prova. Ciò garantisce che Random Forest stia facendo un lavoro fantastico..





