
Con el aumento de la potencia computacional, ahora podemos seleccionar algoritmos que realicen cálculos muy intensivos. Uno de esos algoritmos es el “foresta casuale”, del que hablaremos en este post. Aunque el algoritmo es muy popular en varias competiciones (come esempio, las que se ejecutan en Kaggle), el resultado final del modelo es como una caja negra y, perché, debe usarse con prudencia.
prima di continuare, aquí hay un ejemplo sobre la relevancia de seleccionar el mejor algoritmo.
Relevancia de seleccionar el algoritmo correcto
Ayer vi una película llamada ” La era de El Mañana“. Me encantó el concepto y el procedimiento de pensamiento que estaba detrás de la trama de esta película. Permítanme resumir la trama (sin comentar el clímax, claro). A diferencia de otras películas de ciencia ficción, esta película gira en torno a un solo poder que se otorga a ambos lados (héroe y villano). El poder es la capacidad de reiniciar el día.
La raza humana está en guerra con una especie exótica llamada “Mimics”. Mimic se describe como una civilización mucho más evolucionada de una especie exótica. Toda la civilización Mimic es como un solo organismo completo. Tiene un cerebro central llamado “Omega” que controla a todos los demás organismos de la civilización. Permanece en contacto con todas las demás especies de la civilización cada segundo. “Alpha” es la principal especie guerrera (como el sistema nervioso) de esta civilización y toma el mando de “Omega”. “Omega” tiene el poder de reiniciar el día en cualquier momento.
Ora, usemos el sombrero de un analista predictivo para analizar esta trama. Si un sistema tiene la capacidad de reiniciar el día en cualquier momento, usará este poder siempre que muera alguna de sus especies guerreras. E, perché, no habrá una guerra única, cuando cualquiera de las especies guerreras (alfa) verdaderamente morirá, y el cerebro “Omega” probará repetidamente el mejor escenario para maximizar la muerte de la raza humana y limitar el número de muertes de alfa (especies guerreras) a cero todos los días. Puede imaginarse esto como “EL MEJOR” algoritmo predictivo jamás creado. Es literalmente imposible derrotar a tal algoritmo.
Volvamos ahora a “Foreste casuali” usando un estudio de caso.
Argomento di studio
A continuación se muestra una distribución de los ingresos anuales Gini Coeficientes en diferentes países:
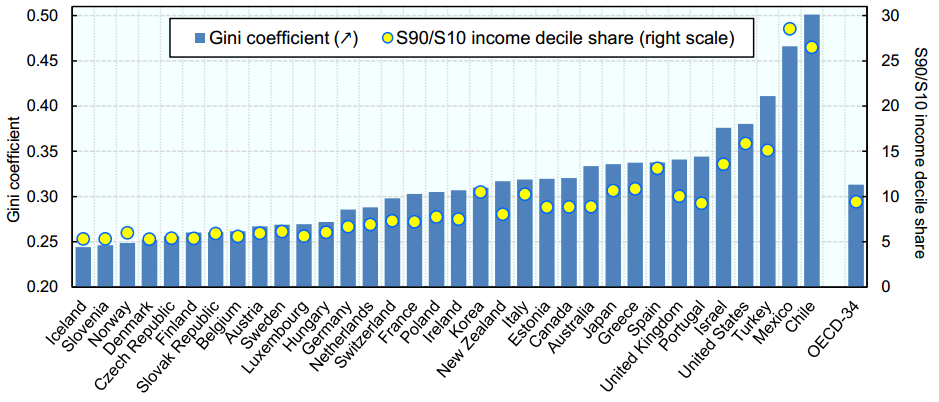
México tiene el segundo coeficiente de Gini más alto y, perché, dispone de una segregación muy alta en el ingreso anual de ricos y pobres. Nuestra tarea es crear un algoritmo predictivo preciso para estimar el nivel de ingresos anual de cada individuo en México. Los tramos de ingresos son los siguientes:
1. Menos de $ 40,000
2. $ 40 000 – 150 000
3. Più di $ 150 000
A continuación se muestra la información disponible para cada individuo:
1. Età, 2. Genere, 3. Calificación educativa más alta, 4. Trabajar en la industria, 5. Residencia en Metro / No metro
Necesitamos idear un algoritmo para dar una predicción precisa para un individuo que tiene los siguientes rasgos:
1. Età: 35 anni, 2, Genere: Maschile, 3. Calificación educativa más alta: Diplomado, 4. Industria: Manufactura, 5. Residencia: Metro
Solo hablaremos de bosque aleatorio para hacer esta predicción en este post.
El algoritmo de Random Forest
El bosque aleatorio es como un algoritmo de arranque con el modelo de árbol de decisión (CARRELLO). Diciamo che abbiamo 1000 observaciones en la población completa con 10 variabili. El bosque aleatorio intenta construir múltiples modelos CART con diferentes muestras y diferentes variables iniciales. Come esempio, se necesitará una muestra aleatoria de 100 osservazioni e 5 variables iniciales elegidas al azar para construir un modelo CART. Repetirá el procedimiento (Diciamo) 10 veces y posteriormente hará una predicción final en cada observación. El pronóstico final es una función de cada predicción. Esta predicción final puede ser simplemente la media de cada predicción.
Volver al estudio de caso
Disclaimer: los números de este post son ilustrativos
México dispone de una población de 118 MILLIMETRO. Digamos que el algoritmo Random Forest recoge 10k de observaciones con solo una variable (per semplificare) para construir cada modelo CART. Totale, estamos viendo el modelo de 5 CART que se está construyendo con diferentes variables. En un obstáculo de la vida real, tendrá más muestras de población y diferentes combinaciones de variables de entrada.
Bandas salariales:
Gruppo musicale 1: Menos de $ 40,000
Gruppo musicale 2: $ 40 000 – 150 000
Gruppo musicale 3: più di $ 150,000
A continuación se muestran los resultados de los 5 modelos CART diferentes.
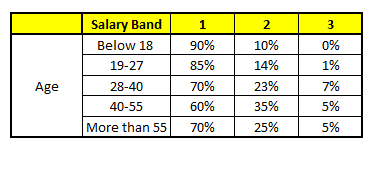
CARRITO 1: Edad variable
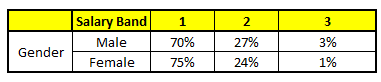
CARRITO 2: Género variable
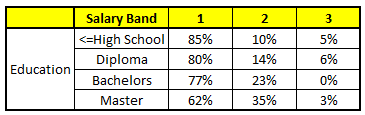
CARRITO 3: Educación variable
CARRITO 4: Residencia variable

CARRITO 5: Industria variable
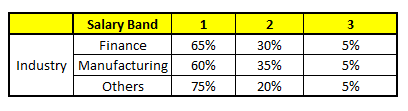
Usando estos 5 modelos CART, necesitamos llegar a un único conjunto de probabilidad para pertenecer a cada una de las clases salariales. Per semplificare, solo tomaremos una media de probabilidades en este estudio de caso. Aparte de la media simple, además consideramos el método de voto para llegar a el pronóstico final. Para llegar a el pronóstico final, ubiquemos el siguiente perfil en cada modelo CART:
1. Età: 35 anni, 2, Genere: Maschile, 3. Calificación educativa más alta: Diplomado, 4. Industria: Manufactura, 5. Residencia: Metro
Para cada uno de estos modelos CART, a continuación se muestra la distribución entre las bandas salariales:
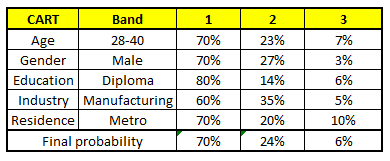
La probabilidad final es simplemente el promedio de la probabilidad en las mismas bandas salariales en diferentes modelos CART. Como puede ver en este análisis, C'è un 70% de posibilidades de que este individuo caiga en la clase 1 (meno di $ 40,000) y alrededor del 24% de posibilidades de que el individuo caiga en la clase 2.
Note finali
El bosque aleatorio proporciona predicciones mucho más precisas en comparación con los modelos simples CART / CHAID o regressione in molti scenari. Estos casos de forma general disponen un gran número de variables predictivas y un tamaño de muestra enorme. Esto se debe a que captura la varianza de varias variables de entrada al mismo tiempo y posibilita que un gran número de observaciones participen en el pronóstico. En algunos de los próximos posts, hablaremos más sobre el algoritmo con más detalle y hablaremos acerca de cómo construir un bosque aleatorio simple en R.





