Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati

Secondo gli esperti, il 80% dei dati mondiali è sotto forma di dati non strutturati (immagini, video, testo, eccetera.). Questi dati potrebbero essere generati da tweet / post sui social media, chiamate trascrizioni, recensioni di sondaggi o interviste, messaggi di testo sui blog, forum, notizia, eccetera.
È umanamente impossibile leggere tutto il testo sul web e trovare schemi. tuttavia, c'è sicuramente bisogno che l'azienda analizzi questi dati per intraprendere azioni migliori.
Uno di quei processi per ottenere conoscenza dai dati testuali è l'analisi del sentiment. Per ottenere i dati per l'analisi del sentiment, si può raschiare direttamente il contenuto dalle pagine web usando diverse tecniche di web scraping.
Se non conosci il web scraping, non esitate a consultare il mio articolo “Web scraping con Python: bellazuppa”.
Cos'è l'analisi del sentimento??
Analisi del sentimento (noto anche come opinion mining o emozione AI) è un sottocampo della PNL che misura l'inclinazione delle opinioni delle persone (positivo / negativo / neutro) all'interno di testo non strutturato.
L'analisi del sentiment può essere eseguita utilizzando due approcci: basato su regole, basato sull'apprendimento automatico.
Poche applicazioni della sentiment analysis
- Analisi di mercato
- Monitoraggio dei social media
- Analisi del feedback dei clienti: analisi dell'opinione o della reputazione del marchio
- Ricerca di mercato
Cos'è l'elaborazione del linguaggio naturale? (PNL)?
Il linguaggio naturale è il modo in cui noi, gli umani, comunichiamo tra di noi. Può essere vocale o di testo. La PNL è la manipolazione automatica del linguaggio naturale da parte del software. PNL è un termine di livello superiore ed è la combinazione di Comprensione del linguaggio naturale (NLU) e Generazione del linguaggio naturale (NLG).
PNL = NLU + NLG
Alcune delle librerie di elaborazione del linguaggio naturale di Python (PNL) figlio:
- Toolkit del linguaggio naturale (NLTK)
- TestoBlob
- SPAZIO
- Gensim
- CoreNLP
Spero di avere una comprensione di base dei termini Analisi del sentimento, PNL.
Questo articolo si concentra sull'approccio basato su regole all'analisi del sentiment..
Approccio basato su regole
Questo è un approccio pratico per analizzare il testo senza formazione o utilizzando modelli di apprendimento automatico. Il risultato di questo approccio è un insieme di regole in base alle quali il testo è etichettato come positivo. / negativo / neutro. Queste regole sono anche conosciute come lessici. Perciò, L'approccio basato su regole è denominato approccio basato sul lessico.
Gli approcci basati sul lessico ampiamente utilizzati sono TextBlob, VADER, SentiWordNet.
Fasi di pre-elaborazione dei dati:
- Pulizia del testo
- Tokenizzazione
- Arricchimento: tagging dei punti vendita
- Rimozione di parole irrilevanti
- Ottieni le parole radice
Prima di approfondire i passaggi precedenti, Consenti di importare i dati di testo da un file TXT.
Importare un file di testo utilizzando I panda leggono CSV funzione
# Installare e importare la libreria Pandas importa panda come pd # Creating a pandas dataframe from reviews.txt file data = pd.read_csv('recensioni.txt', settembre = 't') data.head()


Questo non sembra buono. Quindi, ora rilasceremo il “Innominato: 0 ″ utilizzando la casella di controllo df.drop funzione.
mydata = data.drop("Senza nome": 0', asse=1)
mydata.head()

Il nostro set di dati ha un totale di 240 osservazioni (recensioni).
passo 1: Pulisci il testo
In questo passaggio, dobbiamo rimuovere i caratteri speciali, numeri di testo. Possiamo usare il operazioni di espressione regolare Libreria Python.
# Define a function to clean the text def clean(testo): # Removes all special characters and numericals leaving the alphabets text = re.sub('[^A-Za-z]+', ' ', testo) testo di ritorno # Cleaning the text in the review column mydata['Recensioni pulite'] = mydata['recensione'].applicare(pulire) mydata.head()
Spiegazione: "Pulisci" è la funzione che prende il testo come input e lo restituisce senza punteggiatura o numeri. Lo applichiamo alla colonna 'recensione'’ e creiamo una nuova colonna 'Recensioni pulite'’ con testo pulito.

Fantastico, vedi l'immagine qui sopra, Tutti i caratteri speciali e i numeri vengono rimossi.
passo 2: Tokenizzazione
La tokenizzazione è il processo di divisione del testo in pezzi più piccoli chiamati token. Può essere fatto a livello di frase (tokenizzazione della frase) o a parole (tokenizzazione delle parole).
Eseguirò la tokenizzazione a livello di parola usando tokenizar nltk word_tokenize funzione ().
Nota: Poiché i nostri dati di testo sono un po' grandi, Illustrerò prima i passaggi 2-5 con piccole frasi di esempio.
Diciamo che abbiamo una preghiera “Questo è un articolo sull'analisi del sentimento.“. Può essere diviso in piccoli pezzi (record) come mostrato di seguito.

passo 3: Arricchimento: Etichettatura POS
Etichettare le parti del discorso (POS) è un processo di conversione di ogni token in una tupla che ha la forma (parola, etichetta). L'etichettatura POS è essenziale per preservare il contesto della parola ed è essenziale per arginare.
Questo può essere ottenuto usando nltk pos_tag funzione.
Di seguito sono riportati i tag POS della frase di esempio “Questo è un articolo sull'analisi delle opinioni”.
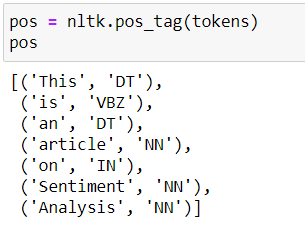
Vedere l'elenco delle possibili etichette di posizione. qui.
passo 4: rimozione di parole non significative
Le stopword inglesi sono parole che contengono pochissime informazioni utili. Dobbiamo rimuoverli come parte della preelaborazione del testo. nltk ha un elenco di stopword per ogni lingua.
Vedi le stopword inglesi.

Esempio di rimozione delle stopword:

Le parole vuote Questo, è, un, on vengono rimossi e la frase di uscita è "Analisi dell'opinione dell'articolo".
passo 5: ottenere le parole radice
Una radice è parte di una parola responsabile del suo significato lessicale. Le due tecniche popolari per ottenere le parole radice / radice sono Stemming e Lemmatization.
La differenza fondamentale è che Stemming spesso fornisce alcune parole radice senza senso, dato che taglia solo alcuni caratteri alla fine. La derivazione fornisce radici significative, tuttavia, richiede tag POS delle parole.
Esempio per illustrare la differenza tra Stemming e Lematization: Clicca qui per ricevere il codice

Se osserviamo l'esempio precedente, L'output di Stemming è Stem e l'output di Lemmatizatin è Lemma.
Con la parola guarda, lo stelo sguardo non ha senso. Considerando che, il motto Guarda è perfetto.
Ora abbiamo capito i passaggi 2-5 prendendo semplici esempi. Senza ulteriori indugi, torniamo al nostro vero problema.
Codice per i passaggi 2 un 4: tokenizzazione, Tagging POS, rimozione di parole non significative
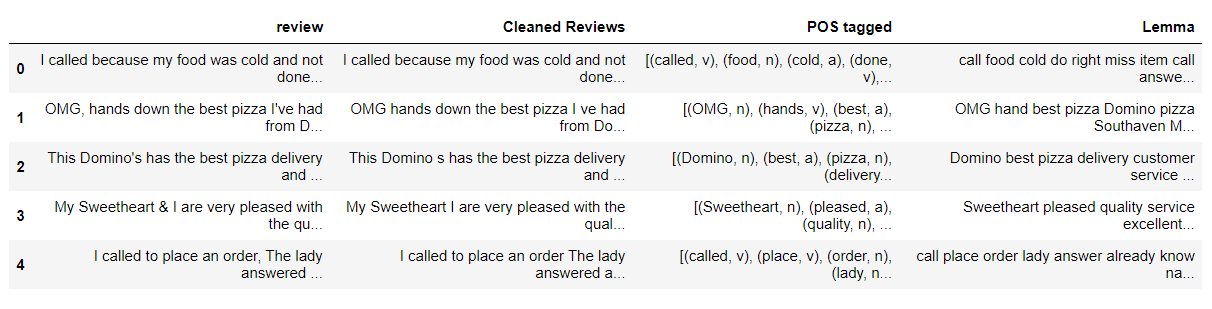
import nltk nltk.download('Punto') from nltk.tokenize import word_tokenize from nltk import pos_tag nltk.download('stopword') from nltk.corpus import stopwords nltk.download('wordnet') da nltk.corpus importa wordnet # POS tagger dictionary pos_dict = {'J':wordnet. ADJ, 'V':wordnet. VERBO, 'N':wordnet. SOSTANTIVO, 'R':wordnet. ADV} def token_stop_pos(testo): tag = pos_tag(word_tokenize(testo)) newlist = [] per parola, tag nei tag: se word.lower() non nel set(stopwords.parole('inglese')): newlist.append(tupla([parola, pos_dict.get(etichetta[0])])) return newlist mydata['POS taggato'] = mydata['Recensioni pulite'].applicare(token_stop_pos) mydata.head()
Spiegazione: token_stop_pos è la funzione che prende il testo ed esegue la tokenizzazione, rimuovi le parole vuote e tagga le parole nel tuo POS. Lo applichiamo alla colonna 'Recensioni pulite'’ e creiamo una nuova colonna per i dati "POS con tag".
Come menzionato prima, per ottenere il lemma preciso, WordNetLemmatizer richiede tag POS sotto forma di 'n', 'un', eccetera. Ma i tag POS ottenuti da pos_tag hanno la forma "NN", «ADJ», eccetera.
Per assegnare pos_tag ai tag wordnet, creiamo un dizionario pos_dict. Qualsiasi pos_tag che inizia con J viene mappato a wordnet. ADJ, qualsiasi pos_tag che inizia con R viene mappato a wordnet. ADV, e così via.
I nostri tag di interesse sono sostanziali, Aggettivo, Avverbio, Verbo. Qualsiasi cosa di questi quattro è assegnata a Nessuno.

Nella figura sopra, possiamo osservare che ogni parola nella colonna 'POS tagged’ viene assegnato al tuo POS da pos_dict.
Codice per il passaggio 5: ottenere le parole radice – Lematizzazione
from nltk.stem import WordNetLemmatizer wordnet_lemmatizer = WordNetLemmatizer() def lemmatize(pos_data): lemma_rew = " " per parola, pos in pos_data: se non pos: lemma = word lemma_rew = lemma_rew + " " + lemma else: lemma = wordnet_lemmatizer.lemmatize(parola, pos=pos) lemma_rew = lemma_rew + " " + lemma return lemma_rew mydata['Lemma'] = mydata['POS taggato'].applicare(lemmatize) mydata.head()
Spiegazione: lemmatize è una funzione che prende le tuple pos_tag e dà il Lemma per ogni parola in pos_tag basato sul posizione di quella parola. Lo applichiamo alla colonna 'TAgged POS’ e creiamo una colonna 'Lema’ per memorizzare l'output.
sì, dopo un lungo viaggio, abbiamo finito con la pre-elaborazione del testo.
Ora, prenditi un minuto per guardare le colonne "recensione", 'Motto’ e osservare come viene elaborato il testo.
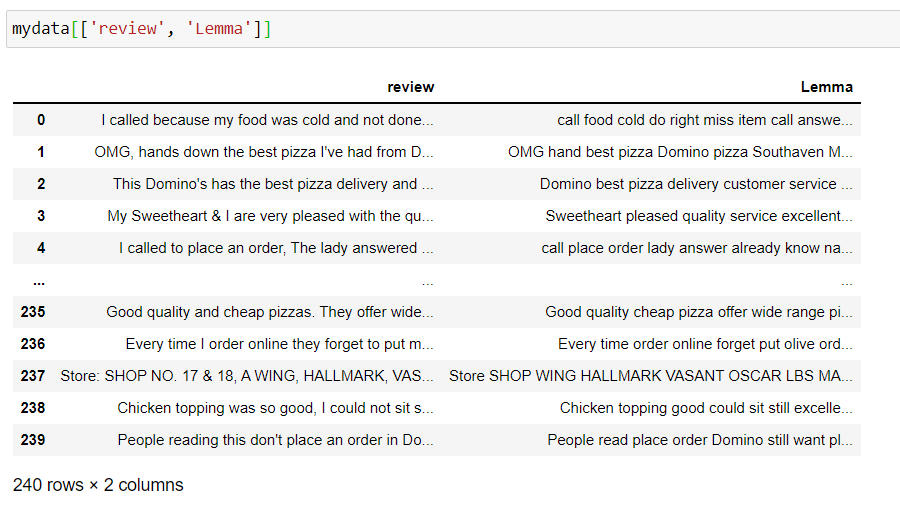
Quando abbiamo finito con la pre-elaborazione dei dati, i nostri dati finali sembrano puliti. Prenditi una breve pausa e torna per continuare con il vero compito.
Analisi del sentiment con TextBlob:
TextBlob è una libreria Python per l'elaborazione di dati testuali. Fornisce un'API coerente per immergersi nelle attività comuni di elaborazione del linguaggio naturale (PNL), come l'etichettatura di parte del discorso, l'estrazione di frasi nominali, analisi del sentiment e altro ancora.
Le due misure utilizzate per analizzare il sentiment sono:
- Polarità: parla di quanto sia positiva o negativa l'opinione.
- Soggettività: parla di come sia soggettiva l'opinione.
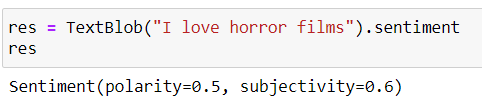
TestoBlob (testo) .il sentimento ci dà i valori della Polarità, Soggettività.
La polarità varia da -1 un 1 (1 è più positivo, 0 è neutro, -1 è più negativo)
La soggettività varia da 0 un 1 (0 è molto obiettivo e 1 molto soggettivo)
Codice Python:
da textblob importa TextBlob # function to calculate subjectivity def getSubjectivity(recensione): restituire TextBlob(recensione).sentiment.soggettività # function to calculate polarity def getPolarity(recensione): restituire TextBlob(recensione).sentiment.polarità # function to analyze the reviews def analysis(punto): se punteggio < 0: return 'Negative' elif score == 0: return 'Neutral' else: restituisci 'Positivo'
Spiegazione: funzioni create per ottenere valori di polarità, soggettività ed etichettare la recensione in base al punteggio di polarità.
Creare un nuovo framework di dati con la revisione, Colonne motto e applicare le funzioni di cui sopra
fin_data = pd. DataFrame(mydata[['recensione', 'Lemma']])
# fin_data[«Soggettività»] = fin_data['Lemma'].applicare(getSoggettività) fin_data['Polarità'] = fin_data['Lemma'].applicare(getPolarità) fin_data['Analisi'] = fin_data['Polarità'].applicare(analisi) fin_data.head()
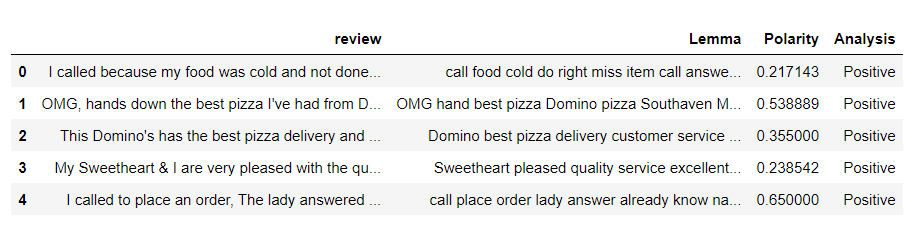
Conta il numero di recensioni positive, negativo e neutro.
tb_counts = fin_data. Analysis.value_counts() tb_counts
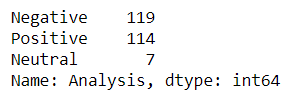
Analisi del sentiment con VADER
VADER è l'acronimo di Valence Aware Dictionary and Sentiment Reasoner. Il sentimento di Vader non dice solo se l'affermazione è positiva o negativa insieme all'intensità dell'emozione..

La somma delle post-intensità, negativo, neu da 1. Il composto varia da -1 un 1 ed è la metrica utilizzata per disegnare il sentiment complessivo.
positivo se composto> = 0.5
neutro se -0,5 <composto <0,5
negativo se -0,5> = composto
Codice Python:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer analyzer = SentimentIntensityAnalyzer() # function to calculate vader sentiment def vadersentimentanalysis(recensione): vs = analizzatore.polarity_scores(recensione) ritorno vs['composto'] fin_data['Vader Sentiment'] = fin_data['Lemma'].applicare(vadersentimentanalysis) # function to analyse def vader_analysis(composto): se composto >= 0.5: return 'Positive' elif compound <= -0.5 : return 'Negative' else: return 'Neutral' fin_data['Analisi di Vader'] = fin_data['Vader Sentiment'].applicare(vader_analysis) fin_data.head()
Spiegazione: Funzionalità create per ottenere punteggi Vader e recensioni di tag in base a punteggi compositi
Conta il numero di recensioni positive, negativo e neutro.
vader_counts = fin_data['Analisi di Vader'].value_counts() vader_counts
Analisi del sentiment con SentiWordNet
SentiWordNet utilizza il database WordNet. È importante ottenere il POS, motto di ogni parola. Quindi useremo il motto, POS per ottenere i set di sinonimi (synset). Prossimo, otteniamo i punteggi oggettivi, negativo e positivo per tutti i possibili sintetizzatori o il primo sintetizzatore e etichettiamo il testo.
se punteggio positivo> punteggio negativo, la sensazione è positiva
se punteggio positivo <punteggio negativo, la sensazione è negativa
se punteggio positivo = punteggio negativo, la sensazione è neutra
Codice Python:
nltk.download('sentiwordnet')
from nltk.corpus import sentiwordnet as swn
def sentiwordnetanalysis(pos_data):
sentimento = 0
tokens_count = 0
per parola, pos in pos_data:
se non pos:
continue
lemma = wordnet_lemmatizer.lemmatize(parola, pos=pos)
se non lemma:
continue
synsets = wordnet.synsets(lemma, pos=pos)
se non synset:
Continua
# Prendi il primo senso, the most common
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentiment += swn_synset.pos_score() - swn_synset.neg_score()
tokens_count += 1
# Stampa(swn_synset.pos_score(),swn_synset.neg_score(),swn_synset.obj_score())
se non tokens_count:
Restituzione 0
se il sentimento>0:
Restituzione "Positivo"
if sentiment==0:
Restituzione "Neutro"
altro:
Restituzione "Negativo"
fin_data["Analisi SWN"] = mydata['POS taggato'].applicare(sentiwordnetanalysis)
fin_data.head()
Spiegazione: Creamos una función para obtener los puntajes positivos y negativos para la primera palabra del synset y luego etiquetar el texto calculando el sentimiento como la diferencia de puntajes positivos y negativos.
Conta il numero di recensioni positive, negativo e neutro.
swn_counts= fin_data["Analisi SWN"].value_counts() swn_counts
Fino a questo punto, abbiamo visto l'implementazione della sentiment analysis utilizzando alcune delle tecniche popolari basate sul lessico. Ora fai rapidamente una visualizzazione e confronta i risultati.
Rappresentazione visiva dei risultati TextBlob, VADER, SentiWordNet
Tracceremo il conteggio delle recensioni positive, negativo e neutro per tutte e tre le tecniche.
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15,7))
plt.sottotrama(1,3,1)
plt.titolo("Risultati TextBlob")
plt.pie(tb_counts.valori, etichette = tb_counts.index, esplodere = (0, 0, 0.25), autopct="%1.1F%%", shadow=Falso)
plt.sottotrama(1,3,2)
plt.titolo("Risultati VADER")
plt.pie(vader_counts.valori, etichette = vader_counts.index, esplodere = (0, 0, 0.25), autopct="%1.1F%%", shadow=Falso)
plt.sottotrama(1,3,3)
plt.titolo("Risultati di SentiWordNet")
plt.pie(swn_counts.valori, etichette = swn_counts.index, esplodere = (0, 0, 0.25), autopct="%1.1F%%", shadow=Falso)
Se guardiamo l'immagine qui sopra, I risultati di TextBLOB e Sentiwordnet hanno un aspetto un po' vicino, mentre i risultati VADER mostrano grandi variazioni.
Note finali:
Congratulazioni 🎉 a noi. Alla fine di questo articolo, Abbiamo appreso le varie fasi della preelaborazione dei dati e i diversi approcci lessicali all'analisi del sentiment. Confrontiamo i risultati di TextBlob, VADER, SentiWordNet utilizzando i grafici a torta.
Riferimenti:
Analisi del sentiment di VADER
Guarda il taccuino completo di Jupyter qui ospitato su GitHub.
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





