Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
è stata una piattaforma per i clienti per dare feedback alle aziende in base alla loro soddisfazione. Le recensioni dei clienti sono la fonte affidabile mondiale di contenuti autentici per gli altri utenti.. Il feedback dei clienti funge da strumento di convalida di terze parti per creare fiducia nel marchio dell'utente.. Per comprendere questi feedback dei clienti su un'entità, l'analisi del sentiment sta diventando uno strumento di potenziamento per qualsiasi organizzazione.
L'analisi del sentiment implica l'esame di conversazioni online come i tweet, post di blog o commenti su particolari servizi o argomenti e segregare le opinioni degli utenti (positivo, negativo e neutro), consentendo alle aziende di identificare il sentimento dei clienti nei confronti dei prodotti. Aiuta le aziende con un impulso profondo su come sono realmente i clienti “Tatto” sul tuo marchio ed elaborare grandi quantità di dati in modo efficiente ed economico. Analizzando automaticamente il feedback dei clienti, dalle risposte ai sondaggi alle conversazioni sui social media, i marchi possono ascoltare attentamente i propri clienti e personalizzare prodotti e servizi per soddisfare le loro esigenze.
L'analisi del sentiment può essere classificata come dettagliata, rilevamento delle emozioni, Analisi del sentiment basata sull'aspetto e analisi delle intenzioni. L'analisi dettagliata del sentiment affronta la polarità dell'interpretazione nella revisione, mentre il rilevamento delle emozioni implica l'espressione emotiva dell'utente su un prodotto.
L'analisi del sentiment basata sugli aspetti è una varietà di analisi del sentiment che aiuta a migliorare il business conoscendo le caratteristiche del tuo prodotto che devono essere migliorate in base al feedback dei clienti per rendere il tuo prodotto un best seller.. ABSA identifica gli aspetti nella recensione data su un prodotto e trova anche se l'aspetto menzionato nella recensione appartiene a quale tipo di sentimento.
In questo articolo, condurremo l'ABSA utilizzando il laptop e il set di dati del ristorante di SemEval 2014, così come in set di dati multilingue come il set di dati hindi su prodotti come i laptop, telefoni, ristoranti e hotel.
Pretrattamento dei dati
Tokenizzazione: La tokenizzazione è la divisione del paragrafo di testo in blocchi più piccoli, come frasi (tokenizzazione della frase) o parole (tokenizzazione delle parole). Il principale svantaggio della tokenizzazione delle parole sono le parole senza vocabolario (OOV), per evitare OOV e anche per estrarre informazioni dalla tokenizzazione della frase di testo utilizzata in questa analisi.
Rimuovi le parole vuote: Dopo la tokenizzazione, le stopword vengono identificate e rimosse dai tweet. Le stopword sono le parole più comuni in una lingua che potrebbe non aggiungere molte informazioni alla frase o al documento.. Queste parole vengono filtrate per ridurre al minimo il rumore e migliorare la qualità dei dati di testo per una migliore classificazione.. La libreria NLP contiene una raccolta di stopword per ogni lingua del testo in NLTK. Le parole nel testo vengono confrontate con questo elenco di stopword, le parole di corrispondenza vengono rimosse per migliorare la qualità dei dati e anche per estrarre facilmente le parole dei sentimenti dai tweet.
Rimuovi punteggiatura e carattere: Dopo l'espansione delle contrazioni, i caratteri speciali e la punteggiatura vengono rimossi dalla funzione regex. Il motivo principale per farlo è perché spesso la punteggiatura o i caratteri speciali non hanno molta importanza quando si analizza il testo e lo si utilizza per estrarre funzionalità o informazioni basate su NLP e ML..
Sostituzione della negazione con contrari: La sostituzione di parole negative con contrari riduce la dimensionalità del conteggio delle parole della matrice del documento, quindi è utile comprimere il vocabolario senza perdere il suo significato per risparmiare memoria.
from nltk.corpus import wordnet class AntonymReplacer(oggetto): def sostituire(se stesso, parola, pos=Nessuno): contrari = insieme() per Syn in Wordnet.Synsets(parola, pos=pos): per lemma in syn.lemmas(): per antonimo in lemma.antonyms(): antonyms.add(antonym.name()) se len(Contrari) == 1: ritorno antonyms.pop() altro: return None def replace_negations(se stesso, spedito): io, l = 0, len(spedito) parole = [] mentre io < io: word = inviato[io] if word == 'not' e i+1 < io: ant = self.replace(spedito[i+1]) se formica: words.append(Formica) i += 2 continue words.append(parola) i += 1 parole di ritorno
Correzione ortografica: Le parole con più caratteri ripetuti e ortografia errata che si verificano a causa di errori di digitazione umani devono essere rimosse, in quanto non hanno alcuna importanza in generale. Ad esempio, parole come finallyyy, esattamenteyy, ecc. sono voci errate, tuttavia, deve essere corretto per un uso successivo.
Lematizzazione: La lematización es la técnica de preprocesamiento de texto más común utilizada para la standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de palabras. La lemmatizzazione di una parola converte la parola nella sua forma di base significativa osservando l'analisi morfologica di ogni parola. La lemmatizzazione è anche simile alla lemmatizzazione, pero la primera no tiene en cuenta el contexto de la palabra en la oración y solo elimina el sufijo en las palabras.
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
antreplacer = AntonymReplacer()
def clean_text(testo):
#Lemmatizzazione dei testi
# removing aphostrophe words
text = text.lower() se pd.notnull(testo) else text
text = re.sub(R"Quello", "cos'è ",str(testo))
testo = re.sub(R"'s", " ", str(testo))
testo = re.sub(R"Ho", " Avere ", str(testo))
testo = re.sub(R"Non", "non può ", str(testo))
testo = re.sub(r'ain't', 'non è', str(testo))
testo = re.sub(r'won't', 'non lo farà', str(testo))
testo = re.sub(R"n't", " non ", str(testo))
testo = re.sub(R"Sono", "Io sono ", str(testo))
testo = re.sub(R"'re", " sono ", str(testo))
testo = re.sub(R"'d", " voler ", str(testo))
testo = re.sub(R"'ll", " volere ", str(testo))
testo = re.sub(R"«scuse", " scusa ", str(testo))
testo = re.sub('W', ' ', str(testo))
testo = re.sub('s+', ' ', str(testo))
# Remove punctuations and numbers
text = re.sub('[^ a-zA-Z]', ' ', str(testo))
# Single character removal
text = re.sub(R"s+[a-zA-Z]s+", ' ', str(testo))
text=lemmatizer.lemmatize(testo)
# replacing negation words with antonyms
text=antreplacer.replace(testo)
# Removing multiple spaces
text = re.sub(r's+', ' ', str(testo))
text = text.strip(' ')
testo di ritorno
Modelos de clasificador |

L'incorporamento è il metodo per rappresentare le parole nella frase come vettori. La tecnica di incorporamento che useremo sarà l'incorporamento GloVe, costruzione di matrici di co-occorrenza di parole. Le frasi inglesi vengono addestrate con intarsi GloVe precedentemente addestrati e gli intarsi per le frasi hindi sono addestrati su misura con 13 milioni di dati del corpus hindi.
def get_word2vec_embedding_matrix(modello):
embedding_matrix = np.zeros((vocab_size,300))
per parola, i in tokenizer.word_index.items():
Tentativo:
embedding_vector = modello[parola]
tranne KeyError:
embedding_vector = None
if embedding_vector is not None:
embedding_matrix[io]=embedding_vector
return embedding_matrix
Dopo la frase le parole diventano vettori con l'incorporamento di GloVe, I modelli LSTM e CNN bidirezionali vengono applicati sul livello di codifica per addestrare e prevedere i termini di aspetto e i termini di sentimento, rispettivamente. Il 1000 I termini di aspetto più comunemente usati sono identificati nel set di dati e il modello Bi-LSTM è addestrato e classificato tra queste classi di aspetto. I termini di aspetto previsti sono etichettati BIO. Il sentiment del termine dell'aspetto trovato è previsto utilizzando il modello CNN per classificare la recensione come positiva., negativo e neutro.
embed_dim = 128 lstm_out = 196 modello = Sequenziale() modello.aggiungi(Incorporamento(10000, embed_dim,input_length = 28)) modello.aggiungi(Bidirezionale(LSTM(lstm_out,return_sequences=Vero))) modello.aggiungi(LSTM(lstm_out, abbandono=0.2, recurrent_dropout=0.2)) modello.aggiungi(Attenzione()) modello.aggiungi(Appiattire()) modello.aggiungi(Ritirarsi(0.3)) modello.aggiungi(Denso(1000, attivazione='softmax')) modello.compila(perdita="categorical_crossentropy", ottimizzatore="Adamo", metriche=['precisione']) modello.riepilogo()

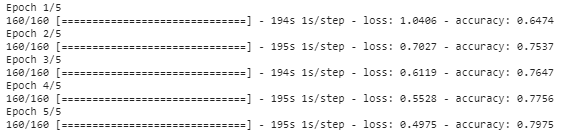
oggetto_storia = modello.fit(trenoX, trenoY, epoche=5,batch_size=8)
Riepilogo
In questo articolo, abbiamo applicato varie tecniche di pre-elaborazione alle revisioni del testo e le parole vengono convertite in rappresentazioni vettoriali utilizzando l'incorporamento GloVe. Il livello incorporato viene aggiunto con il livello LSTM bidirezionale per trovare i termini di aspetto nella frase e l'attenzione di Bahdanau viene applicata per trovare l'associazione tra il bersaglio e le parole di contesto. Trova la polarità del sentiment per ogni termine di aspetto trovato nel modello sopra e previsto utilizzando il modello CNN per classificare il termine di aspetto come positivo., negativo o neutro. I termini di aspetto previsti dalla frase sono contrassegnati con BIO tagging, vale a dire, Inizio, intermedio o al di fuori del termine d'aspetto.
Il codice completo per questo mini-progetto è disponibile qui.
Note finali
Spero che ti sia piaciuto leggere questo articolo.
Buon apprendimento!!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





