Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Python è un linguaggio versatile. Utilizzato per scopi generali di programmazione e sviluppo, e anche per compiti complessi come l'apprendimento automatico, scienza dei dati e analisi dei dati. Non solo è facile da imparare, ha anche delle meravigliose librerie, che lo rende il linguaggio di programmazione di prima scelta per molte persone.
In questo articolo, vedremo uno di quei casi d'uso di Python. Useremo Python per analizzare le prestazioni del giocatore di cricket indiano MS Dhoni nella tua carriera internazionale di un giorno (ODI).

Set di dati
Se hai familiarità con il concetto di web scraping, puoi estrarre i dati da questo ESPN Cricinfo link. Se non conosci il web scraping, Non preoccuparti! Puoi scaricare i dati direttamente da qui. I dati sono disponibili come file Excel per il download.
Una volta che hai il set di dati con te, dovrai caricarlo in Python. Puoi usare il frammento di codice seguente per caricare il set di dati in Python:
# importazione di librerie e pacchetti essenziali
importa panda come pd
importa numpy come np
data e ora di importazione
importa matplotlib.pyplot come plt
import seaborn come sns
# leggendo il set di dati
df = pd.read_excel('MS_Dhoni_ODI_record.xlsx')
Una volta che il set di dati è stato letto, dobbiamo guardare l'inizio e la fine del set di dati per assicurarci che sia importato correttamente. L'intestazione del set di dati dovrebbe essere simile a questa:
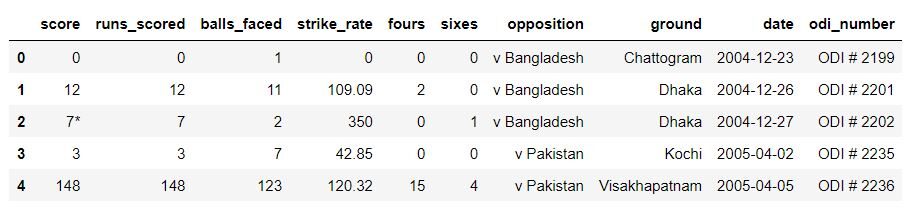
Se i dati vengono caricati correttamente, possiamo andare al passaggio successivo, pulizia e preparazione dei dati.
Pulizia e preparazione dei dati
Questi dati sono stati estratti da una pagina web, quindi non sono molto pulite. Inizieremo rimuovendo il primo 2 caratteri dalla stringa di opposizione perché non è necessario.
# rimuovendo il primo 2 caratteri nella stringa di opposizione df['opposizione'] = df['opposizione'].applicare(lambda x: X[2:])
Prossimo, creeremo una colonna per l'anno in cui il gioco è stato giocato. Assicurati che la colonna della data sia presente nel formato DateTime nel tuo DataFrame. Altrimenti, utilice pd.to_datetime () per convertirlo in formato DateTime.
# creazione di una funzionalità per l'anno della partita df['anno'] = df['Data'].dt.year.astype(int)
Creeremo anche una colonna che indica se Dhoni non era in quella voce o no.
# creando una caratteristica per non essere fuori
df['punto'] = df['punto'].applicare(str)
df['non fuori'] = np.dove(df['punto'].str.endswith('*'), 1, 0)
Ora rimuoveremo la colonna del numero ODI perché non è necessario.
# eliminando la funzione odi_number perché non aggiunge alcun valore all'analisi df.drop(colonne="odi_number", inplace=Vero)
Rimuoveremo anche tutte le partite dai nostri record in cui Dhoni non ha raggiunto e memorizzeremo queste informazioni in un nuovo DataFrame.
# abbandonare quegli inning in cui Dhoni non ha battuto e archiviare in un nuovo DataFrame df_new = df.loc[((df['punto'] != 'DNB') & (df['punto'] != 'TDNB')), 'runs_scored':]
Finalmente, ripareremo i tipi di dati di tutte le colonne presenti nel nostro nuovo DataFrame.
# correzione dei tipi di dati delle colonne numeriche df_new['runs_scored'] = df_new['runs_scored'].come tipo(int) df_new['palle_di fronte'] = df_new['palle_di fronte'].come tipo(int) df_new['strike_rate'] = df_new['strike_rate'].come tipo(galleggiante) df_new["quattro"] = df_new["quattro"].come tipo(int) df_new['sei'] = df_new['sei'].come tipo(int)
Statistiche di gara
Daremo un'occhiata al statistiche descrittive della carriera ODI di MS Dhoni. Puoi usare il seguente codice per questo:
first_match_date = df['Data'].dt.data.min().strftime('%B %d, %E') # prima partita
Stampa("Prima partita":', first_match_date)
last_match_date = df['Data'].dt.data.max().strftime('%B %d, %E') # ultima partita
Stampa('nUltima partita:', last_match_date)
number_of_matches = df.shape[0] # numero di partite giocate in carriera
Stampa('nNumero di partite giocate:', numero_di_corrispondenze)
number_of_inns = df_new.shape[0] # numero di inning
Stampa('nNumero di inning giocati:', numero_di_locande)
not_outs = df_new['non fuori'].somma() # numero di non eliminati in carriera
Stampa('nNot outs:', not_outs)
run_scored = df_new['runs_scored'].somma() # punti segnati in carriera
Stampa('nRun segnati in carriera:', run_scored)
ball_faced = df_new['palle_di fronte'].somma() # palloni affrontati in carriera
Stampa('nPalle affrontate in carriera:', ball_faced)
carriera_sr = (run_scored / ball_faced)*100 # tasso di sciopero in carriera
Stampa('nTasso di sciopero di carriera: {:.2F}'.formato(carriera_sr))
career_avg = (run_scored / (numero_di_locande - not_outs)) # media di carriera
Stampa('nMedia di carriera: {:.2F}'.formato(career_avg))
high_score_date = df_new.loc[df_new.runs_scored == df_new.runs_scored.max(), 'Data'].valori[0]
punteggio_più alto = df.loc[df.date == data_punteggio_più alto, 'punto'].valori[0] # punteggio più alto
Stampa('nPunteggio più alto in carriera:', punteggio più alto)
centinaia = df_new.loc[df_new['runs_scored'] >= 100].forma[0] # numero di 100s
Stampa('nNumero di 100s:', centinaia)
anni cinquanta = df_new.loc[(df_new['runs_scored']>=50)&(df_new['runs_scored']<100)].forma[0] #numero di 50s
Stampa('nNumero di 50s:', anni Cinquanta)
quattro = df_new["quattro"].somma() # numero di quattro in carriera
Stampa('nNumero di 4s:', a quattro zampe)
sei = df_new['sei'].somma() # numero di sei in carriera
Stampa('nNumero di 6s:', sei)
L'output dovrebbe essere simile a questo:
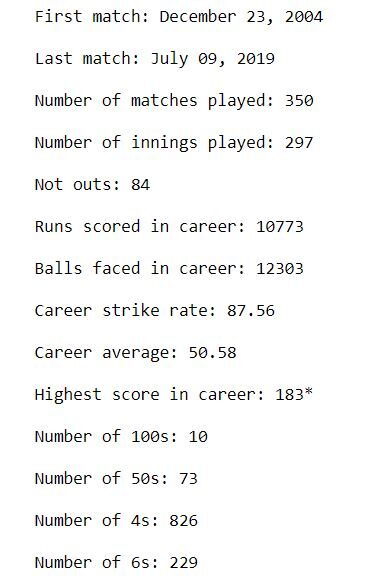
Questo ci dà una buona idea della carriera complessiva di MS Dhoni. Ho iniziato a giocare in 2004, e l'ultima volta ha suonato un ODI in 2019. In una carriera di più di 15 anni, ha segnato 10 cento e una quantità impressionante di 73 cinquanta. Ha segnato più di 10,000 carriere nella sua carriera con una media di 50.6 e un tasso di sciopero di 87.6. Il tuo punteggio più alto è 183 *.
Ora faremo un'analisi più esaustiva delle loro prestazioni contro squadre diverse. Vedremo anche la loro esibizione anno dopo anno. Ci avvarremo dell'aiuto delle visualizzazioni per questo.
Analisi
Primo, vedremo quanti partite che hai giocato contro avversari diversi. È possibile utilizzare il seguente codice per questo scopo:
# numero di partite giocate contro diverse avversarie df['opposizione'].value_counts().complotto(tipo='bar', titolo="Numero di partite contro diverse avversarie", figsize=(8, 5));
L'output dovrebbe essere simile a questo:
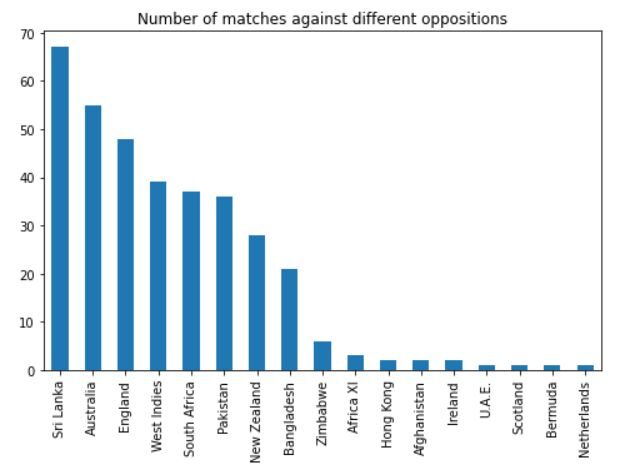
Possiamo vedere che ha giocato la maggior parte delle sue partite contro lo Sri Lanka, Australia, Inghilterra, Indie occidentali, Sudafrica e Pakistan.
Vediamo quanti carriere che hai segnato contro diverse avversarie. Puoi utilizzare il seguente frammento di codice per generare il risultato:
run_scored_by_opposition = pd.DataFrame(df_new.groupby('opposizione')['runs_scored'].somma())
run_scored_by_opposition.plot(tipo='bar', titolo="Punti segnati contro diverse avversarie", figsize=(8, 5))
plt.xlabel(Nessuno);
L'output sarà simile a questo:
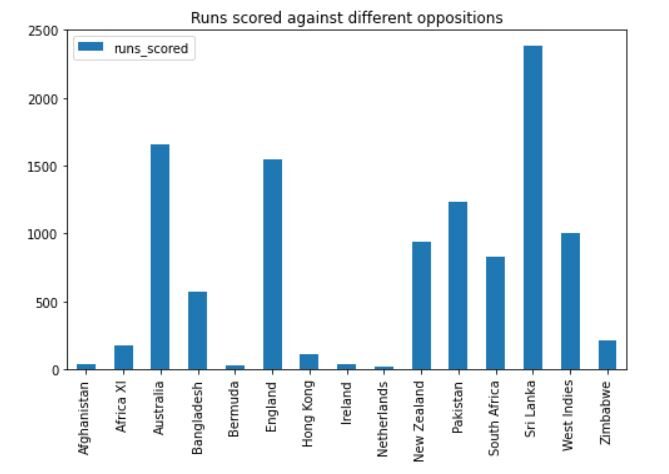
Possiamo vedere che Dhoni ha segnato il maggior numero di punti contro lo Sri Lanka, seguito dall'Australia, Inghilterra e Pakistan. Ha anche giocato molte partite contro queste squadre, quindi ha senso.
Per avere un quadro più chiaro, diamo un'occhiata al tuo media battuta contro ogni squadra. Il seguente frammento di codice ci aiuterà a ottenere il risultato desiderato:
innings_by_opposition = pd.DataFrame(df_new.groupby('opposizione')['Data'].contare())
not_outs_by_opposition = pd.DataFrame(df_new.groupby('opposizione')['non fuori'].somma())
temp = run_scored_by_opposition.merge(innings_by_opposition, left_index=Vero, right_index=Vero)
medium_by_opposition = temp.merge(not_outs_by_opposition, left_index=Vero, right_index=Vero)
mean_by_opposition.rename(colonne = {'Data': 'inning'}, inplace=Vero)
media_per_opposizione['eff_num_of_inns'] = media_per_opposizione['inning'] - media_per_opposizione['non fuori']
media_per_opposizione['media'] = media_per_opposizione['runs_scored'] / media_per_opposizione['eff_num_of_inns']
media_per_opposizione.sostituisci(ad esempio inf, np.nan, inplace=Vero)
major_nations = ['Australia', 'Inghilterra', 'Nuova Zelanda', 'Pakistan', 'Sud Africa', 'Sri Lanka', 'Indie occidentali']
Per generare il grafico, usa lo snippet di codice qui sotto:
plt.figure(dimensione del fico = (8, 5))
plt.trama(media_per_opposizione.loc[major_nations, 'media'].valori, marcatore="oh")
plt.trama([career_avg]*len(major_nations), '--')
plt.titolo('Media contro squadre importanti')
plt.xticks(gamma(0, 7), major_nations)
plt.ylim(20, 70)
plt.legend(["Media contro l'opposizione", "Media di carriera"]);
L'output sarà simile a questo:
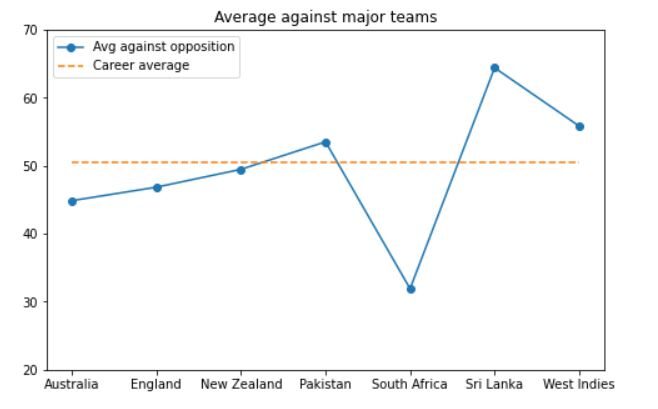
Come possiamo vedere, Dhoni si è comportato notevolmente contro squadre difficili come l'Australia, Inghilterra e Sri Lanka. La sua media contro queste squadre è vicina alla sua media in carriera o leggermente superiore.. L'unica squadra contro cui non ha giocato bene è il Sudafrica.
Vediamo ora le loro statistiche di anno in anno. Inizieremo guardando quante partite hai giocato ogni anno dopo il suo debutto. Il codice per questo sarà:
df['anno'].value_counts().sort_index().complotto(tipo='bar', titolo="Partite giocate per anno", figsize=(8, 5)) plt.xticks(rotazione=0);
La trama sarà simile a questa:
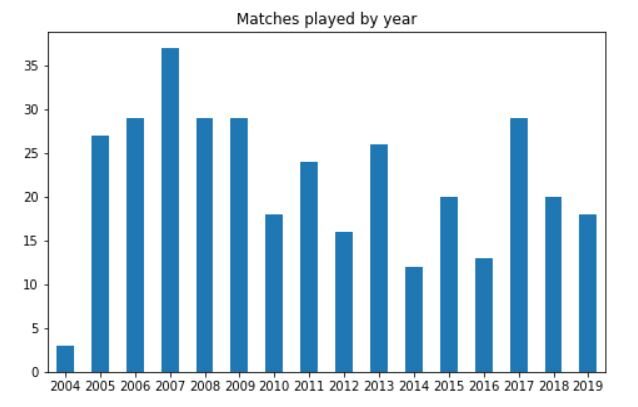
Lo possiamo vedere in 2012, 2014 e 2016, Dhoni ha giocato pochissime partite ODI per l'India. Generalmente, dopo 2005-2009, il numero medio di partite giocate è leggermente diminuito.
Dovremmo anche vedere quanti carriere che ha segnato ogni anno. Il codice per questo sarà:
df_new.groupby('anno')['runs_scored'].somma().complotto(tipo='linea', marcatore="oh", titolo="Run segnati per anno", figsize=(8, 5))
anni = df['anno'].unico().elencare()
plt.xticks(anni)
plt.xlabel(Nessuno);
L'output dovrebbe essere simile a questo:
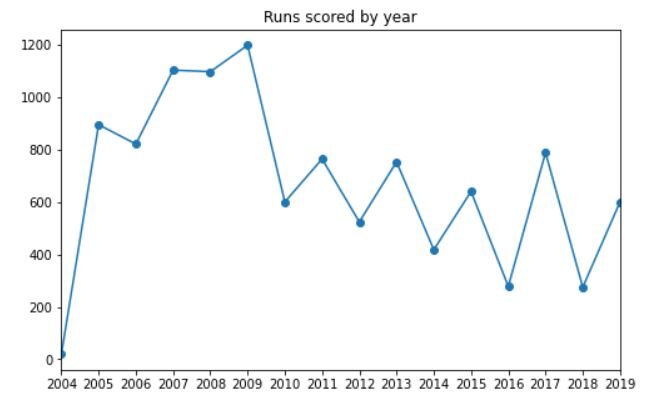
Puoi vedere chiaramente che Dhoni ha segnato il maggior numero di punti dell'anno 2009, seguito da 2007 e 2008. Il numero di corse ha iniziato a diminuire dopo 2010 (perché anche il numero di partite giocate ha iniziato a diminuire).
Finalmente, vediamo il suo Progressione media di battuta in carriera per inning. Questi sono dati di serie temporali e sono stati tracciati in un diagramma a linee. Il codice per questo sarà:
df_new.reset_index(drop=Vero, inplace=Vero) career_average = pd.DataFrame() carriera_media['runs_scored_in_carriera'] = df_new['runs_scored'].cumsum() carriera_media['inning'] = df_new.index.tolist() carriera_media['inning'] = media_carriera['inning'].applicare(lambda x: x+1) carriera_media['non_outs_in_carriera'] = df_new['non fuori'].cumsum() carriera_media['eff_num_of_inns'] = media_carriera['inning'] - carriera_media['non_outs_in_carriera'] carriera_media['media'] = media_carriera['runs_scored_in_carriera'] / carriera_media['eff_num_of_inns']
Lo snippet di codice per la trama sarà:
plt.figure(dimensione del fico = (8, 5))
plt.trama(carriera_media['media'])
plt.trama([career_avg]*carriera_media.forma[0], '--')
plt.titolo("Progressione media di carriera per inning")
plt.xlabel('Numero di inning')
plt.legend(['Progressione media', "Media di carriera"]);
Il grafico di output sarà simile a questo:
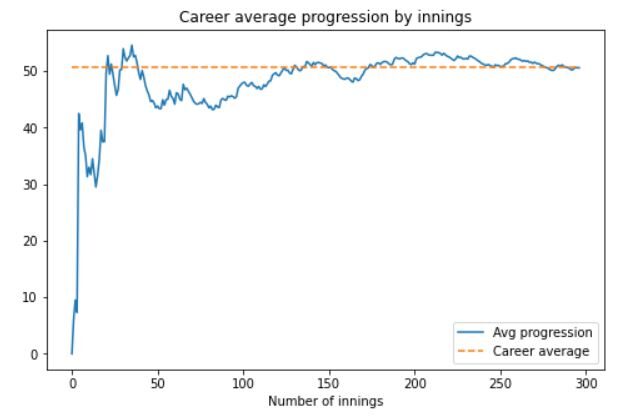
Possiamo vedere che dopo un avvio lento e un calo delle prestazioni sul numero di input 50, La prestazione di Dhoni ha recuperato sostanzialmente. Verso la fine della sua carriera, costantemente mediato sopra 50.
Nota finale
In questo articolo, analizziamo le prestazioni in battuta del giocatore di cricket indiano MS Dhoni. Guardiamo le statistiche generali della tua carriera, le tue prestazioni contro avversari diversi e le tue prestazioni anno dopo anno.
Questo articolo è stato scritto da Vishesh Arora. Puoi connetterti con me su LinkedIn.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





