Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
GitHub è una delle piattaforme di gestione del codice sorgente e di controllo della versione più popolari. È anche uno dei più grandi siti di social media per programmatori. Gli sviluppatori di software lo utilizzano per mostrare le proprie competenze a reclutatori e responsabili delle assunzioni. Quando si analizzano i repository su GitHub, possiamo ottenere informazioni preziose come il comportamento degli utenti, cosa rende popolare un repository o quali tecnologie sono di tendenza tra gli sviluppatori oggi, e altro ancora.
Puoi trovare il codice completo utilizzato nell'articolo qui.
ho usato il "Repository GitHub 2020"’ Set di dati Kaggle, visto che è più recente.
Implementazione
Andiamo idiota questo è iniziato importando le librerie necessarie e leggendo i dati di input,
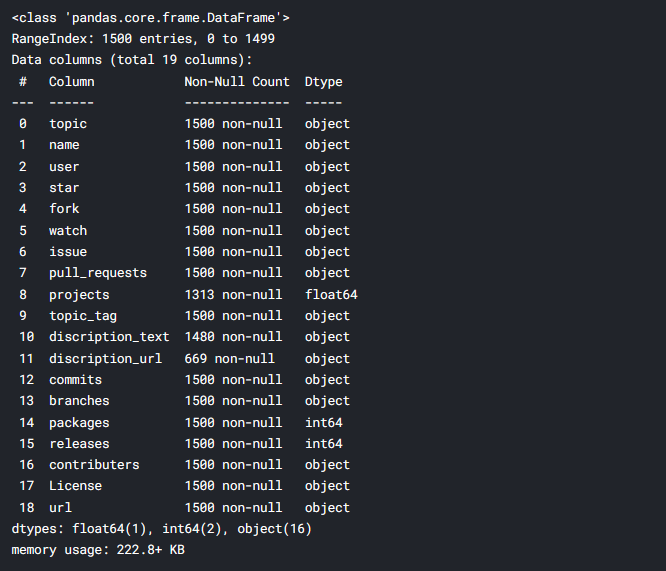
Il set di dati contiene 19 colonne, di cui ho scelto 11 colonne basate sulle terminologie GitHub più popolari e quelle pertinenti al contesto di questa discussione. Puoi vedere che ci sono errori di battitura nei nomi delle colonne, Li ho rinominati per chiarezza.
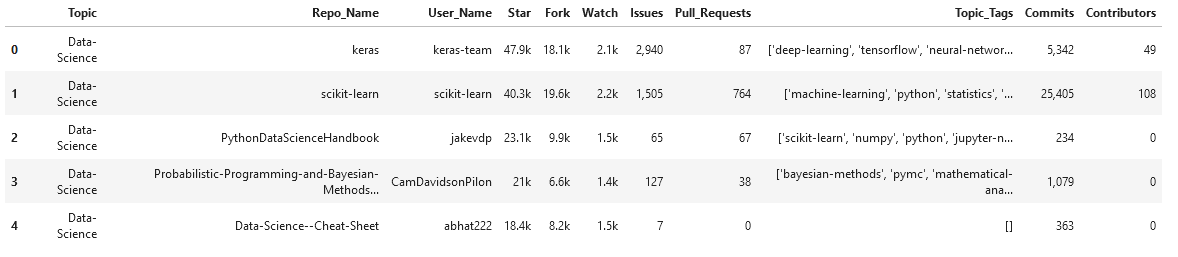
Un breve riassunto sulle colonne dei dati,
- Tema – Un tag che descrive il campo o il dominio del repository.
- Nome_repo – Nome del repository (nome breve del repository)
- Nome utente – Nome del proprietario del repository
- Stella – Numero di stelle ricevute da un repository
- Forchetta – Numero di volte in cui un repository è stato biforcato
- Aspetto – Numero di utenti che guardano il repository
- Domande – Numero di problemi aperti
- Pull_Requests – Richieste pull totali generate
- Topic_Tags – Elenco dei tag argomento aggiunti a quel repository dall'utente
- Compromessi – Numero totale di conferme effettuate
- Collaboratori – Numero di persone che contribuiscono al repository
Scopri come Stella, Forchetta, e Aspetto le colonne contengono 'Kansas per indicare migliaia, quindi convertiamoli in multipli di 1000. Cosa c'è di più, sostituendo il ',’(virgole) del Domande e Compromessi colonne.
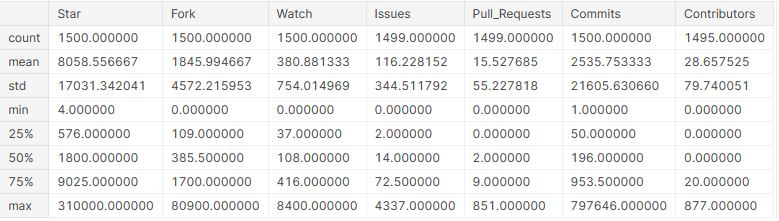
Ora che le colonne sono numeriche, possiamo ottenere da loro informazioni statistiche di base.
# visualizzare i dettagli statistici di base sulle colonne github_df.describe()
1. Analisi dei principali repository in base alla loro popolarità
Cosa rende popolare un repository GitHub? A questa domanda si può rispondere con 3 metrica: stella, orologio e forchetta.
- Stella: quando a un utente piace il tuo repository o vuole mostrare un po' di apprezzamento, lo segna con una stella.
- Orologio: quando un utente vuole essere informato di tutte le attività in un repository, lo vede.
- Forchetta: quando un utente vuole una copia del repository o intende dare un contributo, la forchetta.
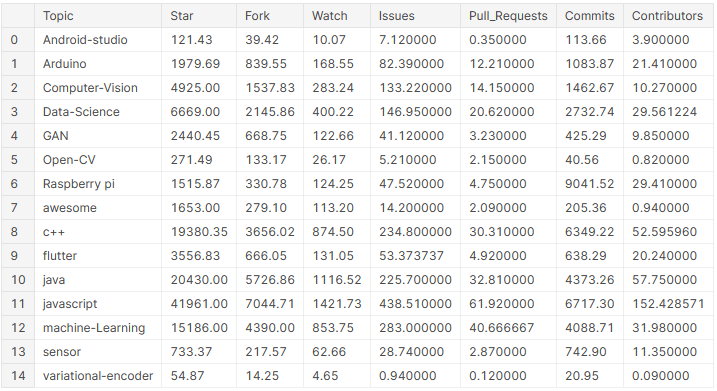
# creare un dataframe con i valori medi delle colonne su tutti gli argomenti
pop_mean_df = github_df.groupby('Argomento').Significare().reset_index()
pop_mean_df
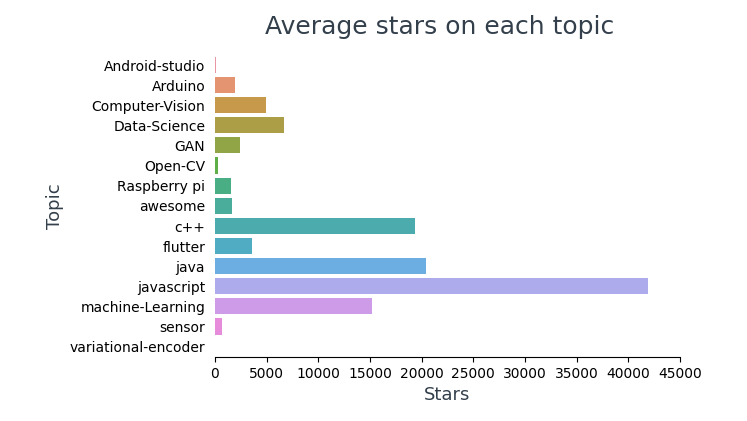
1.1 Analisi delle stelle
Visualizza il numero medio di stelle in ogni argomento,
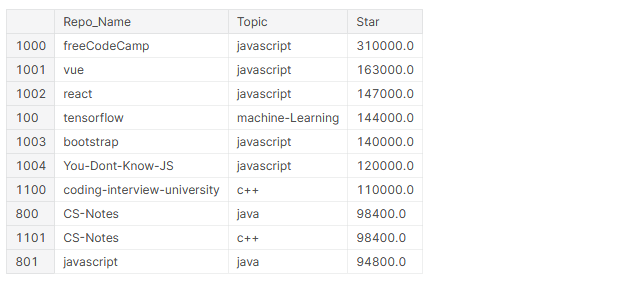
# superiore 10 repository più stellati github_df.nlargest(n=10, colonne="Stella")[['Nome_repo','Argomento','Stella']]
# Consiglio rapido: '33[1m' stampa una stringa in grassetto e '33'[0lo ristampa normalmente.
Stampa('Il repository più speciale è {}{}{} nell'argomento {}{}{} insieme a {}{}{} stelle'.
formato('33[1m',github_df.iloc[github_df['Stella'].idxmax ()]['Nome_repo'], '33[0m',
'33[1m',github_df.iloc[github_df['Stella'].idxmax ()]['Argomento'], '33[0m',
'33[1m',github_df.iloc[github_df['Stella'].idxmax ()]['Stella'], '33[0m'))

In cima 10 i repository più stellati, 4 sono strutture (Visto, Reagire, TensorFlow, BootStrap) e 6 di questi riguardano JavaScript.
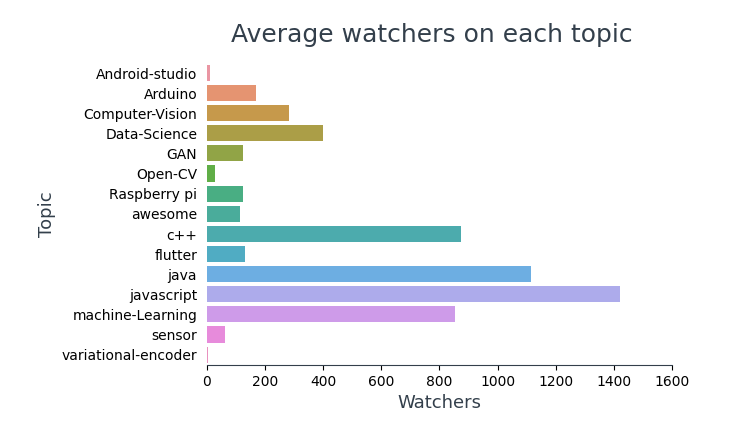
1.2 Analisi dell'orologio
Visualizzazione del numero medio di osservatori su ciascun argomento,
Nota: Il codice per il grafico sopra è lo stesso delle "Stelle medie su ciascun argomento" ad eccezione dei nomi delle colonne. Non ho aggiunto lo stesso per evitare ridondanza.
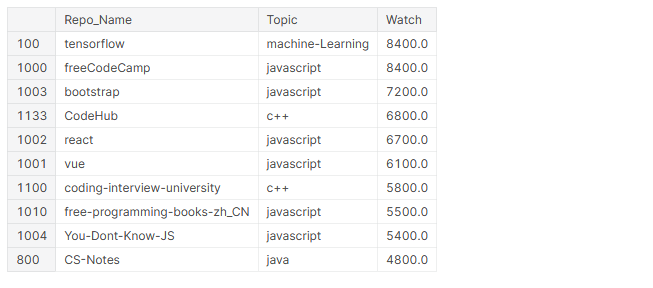
# superiore 10 i repository più visti github_df.nlargest(n=10, colonne="Orologio")[['Nome_repo','Argomento','Orologio']]
Stampa('Il repository più visto è {}{}{} nell'argomento {}{}'.
formato('33[1m',github_df.iloc[github_df['Orologio'].idxmax()]['Nome_repo'],
'33[0m','33[1m',github_df.iloc[github_df['Orologio'].idxmax()]['Argomento']))

Nel 10 repository più visti, 4 strutture figlio (TensorFlow, BootStrap, Reagire, Visto), 6 riguardano JavaScript e 5 di essi contengono contenuti didattici per programmatori.
1.3 Analisi della forcella
Visualizza il numero medio di fork in ogni argomento,
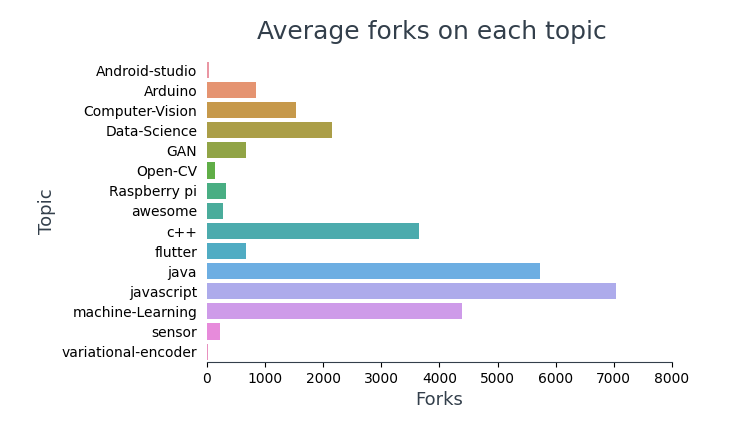
# superiore 10 la maggior parte dei repository biforcuti github_df.nlargest(n=10, colonne="Forchetta")[['Nome_repo','Argomento','Forchetta']]
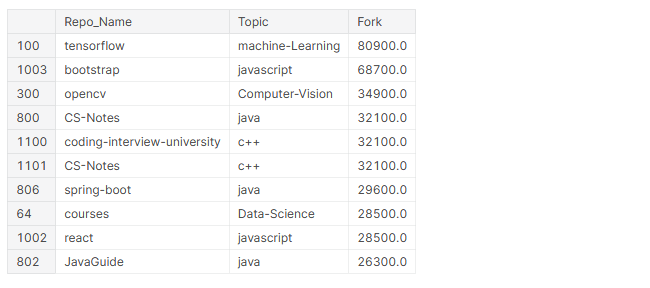
Stampa('La maggior parte dei repository forked è {}{}{} nell'argomento {}{}'.
formato('33[1m',github_df.iloc[github_df['Forchetta'].idxmax()]['Nome_repo'],'33[0m',
'33[1m',github_df.iloc[github_df['Forchetta'].idxmax()]['Argomento']))

In cima 10 più repository biforcuti, 4 strutture figlio (TensorFlow, bootstrap, stivale a molla, reagire) e 5 di essi contengono contenuti didattici per programmatori.
1.4 relazione stellare, tornante e guarda
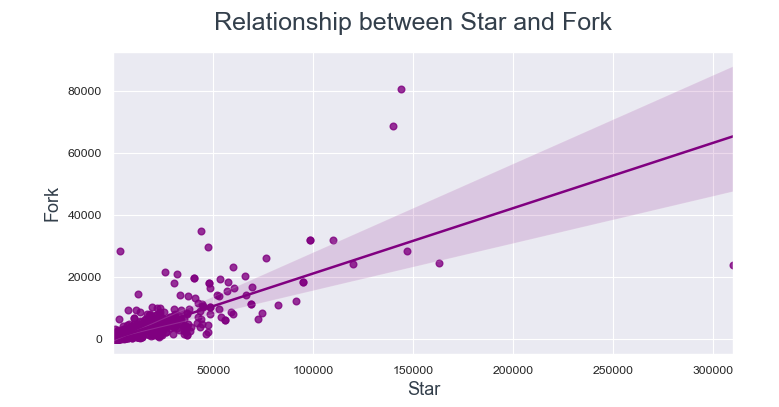
Spesso, gli utenti effettuano un fork di un repository quando vogliono contribuire ad esso. Quindi, Esploriamo la relazione tra la forcella della stella e la forcella dell'orologio.
# imposta la dimensione della figura e dpi
Fig, ax = plt.sottotrame(figsize=(8,4), dpi=100)
# imposta il tema marino per le griglie di sfondo
sns.set_theme('carta')
# tracciare i dati
sns.regplot(data=github_df, x='Guarda', y='Forchetta', colore="viola");
# imposta le etichette e il titolo degli assi x e y
ax.set_xlabel('Orologio', dimensione del carattere=13, colore="#333F4B")
ax.set_ylabel('Forchetta', dimensione del carattere=13, colore="#333F4B")
fig.sottotitolo("Relazione tra orologio e forcella",dimensione del carattere = 18, colore="#333F4B")
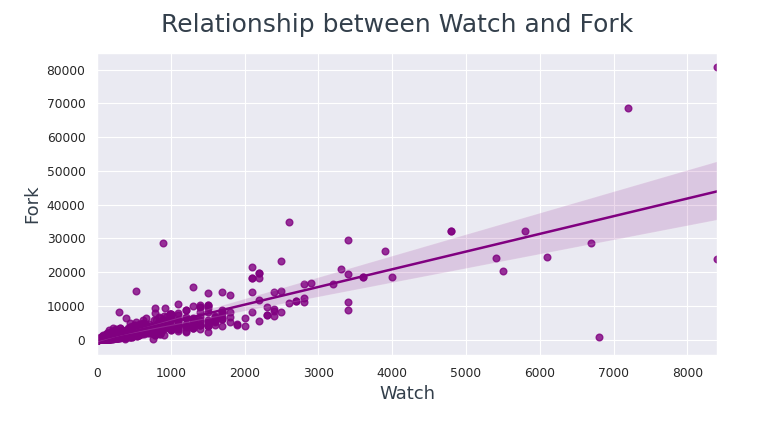
I punti dati sono molto più vicini alla linea di regressione tra Watch e Fork rispetto a Star e Fork.
Da questo possiamo concludere, se un utente sta visualizzando un repository, è più probabile che lo forzi.
2. Analisi degli utenti con più repository
Diamo un'occhiata agli utenti che hanno i repository più popolari.
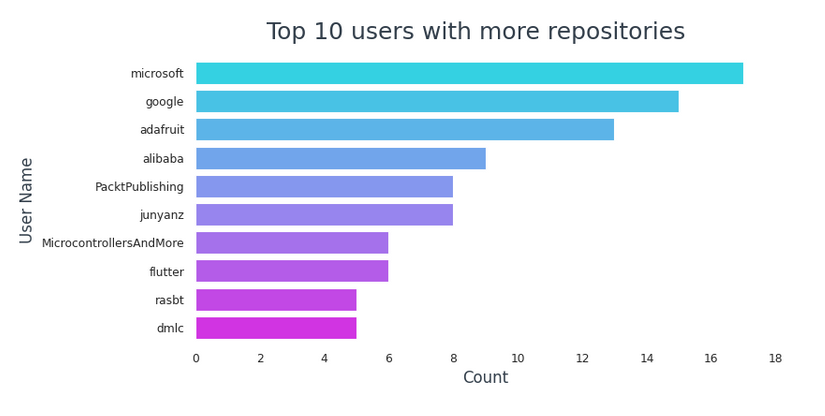
In cima 10 utenti con più repository,
- Microsoft è in cima alla lista con 17 repository.
- Google continua con 15 repository.
- 6 di loro sono società o di proprietà di una società (Microsoft, Google, Adafruit, Alibaba, PacktPublishing, svolazzare)
- 3 sono utenti individuali (junyanz, rasbt, Microcontrollori e altro)
3. Comprensione delle attività di contributo nei repository
GitHub è famoso per il suo grafico dei contributi.
Questo grafico è un record di tutti i contributi che un utente ha fatto. Ogni volta che un utente fa una conferma, aprire un problema o proporre una richiesta pull, è considerato un contributo. Ci sono quattro colonne relative ai contributi nel nostro set di dati, I problemi, Pull_Requests, si impegna, Collaboratori. Vediamo se c'è una vera relazione tra loro.
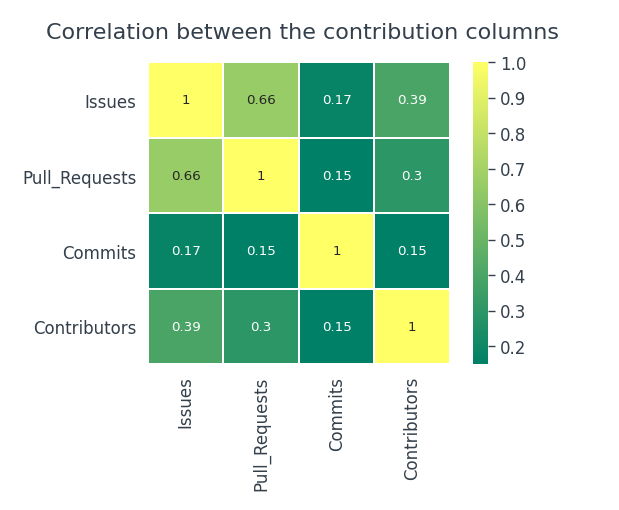
Il numero di conferme non dipende da nessun problema, pull richieste o contributori. Esiste una relazione moderatamente positiva tra problemi e richieste pull.
Esploriamo il 100 repository più popolari e vediamo se è lo stesso,
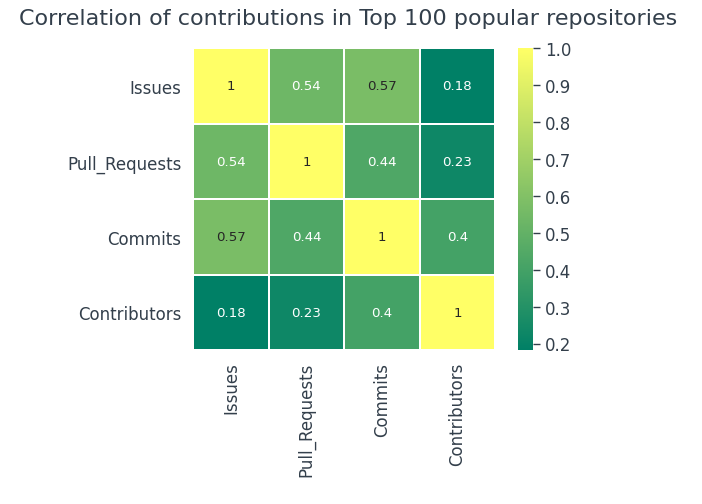
È quasi lo stesso in 100 repository più popolari rispetto al set di dati generale.
Troviamo utenti con più repository,
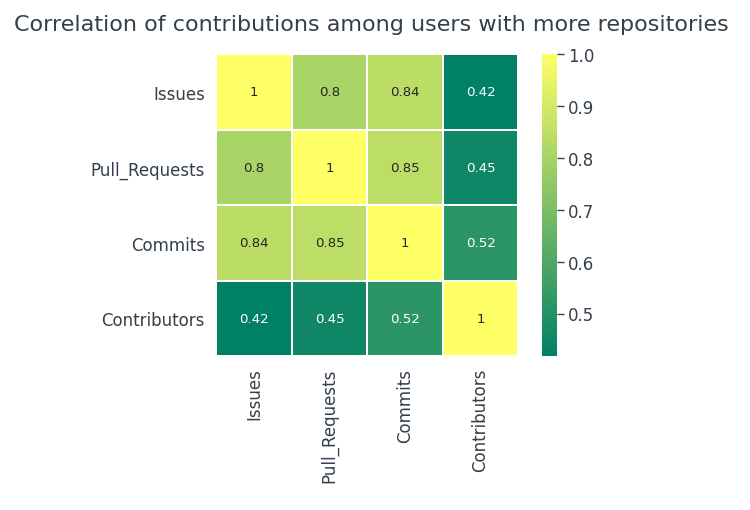
Sorprendentemente, gli utenti con più repository tendono ad essere più attivi. Esiste una correlazione positiva abbastanza forte tra
- Conferma ed estrai le richieste
- Compromessi e problemi
- Pull richieste e problemi
Per quanto riguarda i contributi,
- Non esiste una reale relazione tra le attività di contribuzione nel set di dati complessivo.
- Non vi è inoltre alcuna correlazione tra i contributi nel 100 repository più popolari.
- Se gli utenti tendono ad avere più repository, allora le possibilità di contribuzione sono molto più alte.
4. Analisi dei tag degli argomenti
La colonna topic_tags è composta da elenchi. Per trovare tag popolari, convertire l'intera colonna in un elenco di elenchi e contare l'occorrenza di ciascuna etichetta. Con quello, possiamo visualizzare alcuni dei tag argomento più popolari e vedere quali argomenti tendono a essere taggati di più.
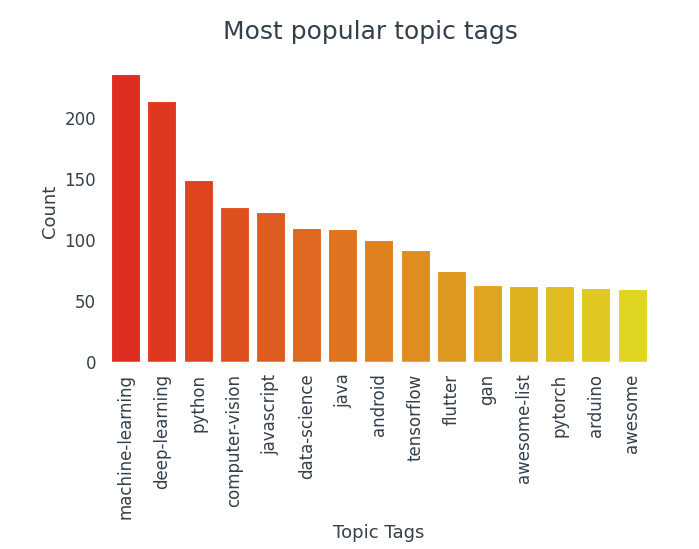
del 15 tag più popolari, 10 appartengono al mondo della scienza dei dati.
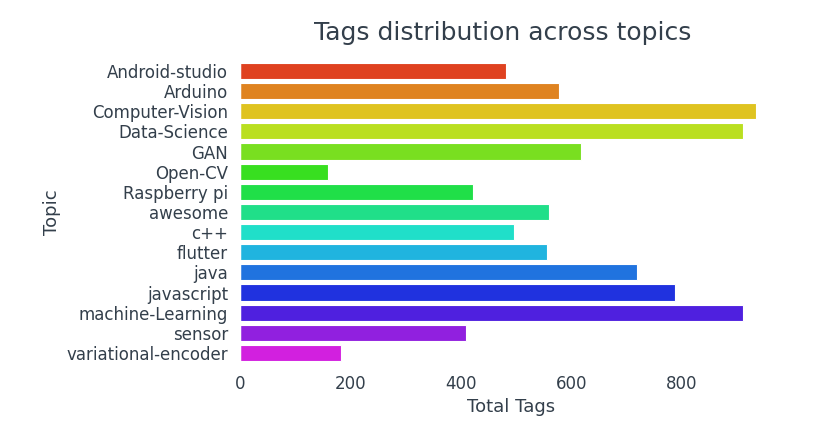
Repository con temi di Visione artificiale, Data Science e Machine Learning tendono ad essere più etichettate.
Concludiamo con una nuvola di parole di topic_tags,
Inferenza:
- Tra i 10 repository più importanti, visto e biforcuto, 4 strutture figlio.
- Tensorflow è il repository più guardato e forkato.
- Se un utente sta guardando un repository, è più probabile che lo forzi.
- Microsoft e Google tendono ad essere utenti con repository più popolari.
- In cima 10 utenti con i repository più popolari, 6 di loro sono aziende.
- Non esiste una reale relazione tra le attività di contribuzione (i problemi, pull richieste, conferme).
- I tag più utilizzati sono Machine Learning, Apprendimento profondo, Pitone, Visione computerizzata, JavaScript.
- Repository con temi di Visione artificiale, La scienza dei dati e l'apprendimento automatico hanno più etichette.
Se avessimo analizzato i dati di dieci anni fa, queste tendenze sarebbero state completamente diverse. È come se la scienza dei dati avesse visto una crescita mostruosa negli ultimi anni!!
Grazie per aver guardato fino qui! mi piacerebbe connettermi LinkedIn
Fatemi sapere nella sezione commenti se avete dubbi, commento o critica. Buona giornata!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





