Panoramica
- Comprender la arquitectura de Apache AlveareHive è una piattaforma di social media decentralizzata che consente ai suoi utenti di condividere contenuti e connettersi con gli altri senza l'intervento di un'autorità centrale. Utilizza la tecnologia blockchain per garantire la sicurezza e la proprietà dei dati. A differenza di altri social network, Hive consente agli utenti di monetizzare i propri contenuti attraverso ricompense in criptovalute, che incoraggia la creazione e lo scambio attivo di informazioni.... y su funcionamiento.
- Impareremo a eseguire alcune operazioni di base in Apache Hive.
introduzione
La maggior parte dei data scientist utilizza le query SQL per esplorare i dati e ottenere approfondimenti da essi.. Ora, poiché il volume dei dati sta crescendo a un ritmo così alto, abbiamo bisogno di nuovi strumenti dedicati per gestire grandi volumi di dati.
Inizialmente, Hadoop è emerso ed è diventato uno degli strumenti più popolari per l'elaborazione e l'archiviazione di big data. Ma gli sviluppatori hanno dovuto scrivere un codice di riduzione delle mappe complesso per lavorare con Hadoop. Questo è l'Apache Hive di Facebook che è venuto a salvare. È un altro strumento progettato per funzionare con Hadoop. Possiamo scrivere query di tipo SQL nell'hive e nel backend le converte in lavori di riduzione della mappa.

In questo articolo, vedremo l'architettura dell'alveare e il suo funzionamento. También aprenderemos cómo realizar operaciones simples como crear una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... y una tabla, caricare dati, modificare la tabella.
Sommario
- Cos'è Apache Hive??
- Arquitectura Apache Hive
- Lavoro Apache Hive
- Tipi di dati in Apache Hive
- Crea ed elimina database
- Crea e rilascia tabella
- Carica i dati nella tabella
- Modifica tabella
- Vantaggio / Svantaggi di Hive
Cos'è Apache Hive??
![]()
Apache Hive è un sistema di archiviazione dati sviluppato da Facebook per elaborare una grande quantità di dati di struttura in Hadoop. Sappiamo che per elaborare i dati utilizzando Hadoop, dobbiamo correggere complesse funzioni di riduzione della mappa, che non è un compito facile per la maggior parte degli sviluppatori. Hive rende questo lavoro molto facile per noi.
Usa un linguaggio di script chiamato HiveQL che è quasi simile a SQL. Quindi, dobbiamo solo scrivere comandi simili a SQL e nel backend Hive li convertirà automaticamente in lavori di riduzione della mappa.
Arquitectura Apache Hive
Diamo un'occhiata al seguente diagramma che mostra l'architettura.
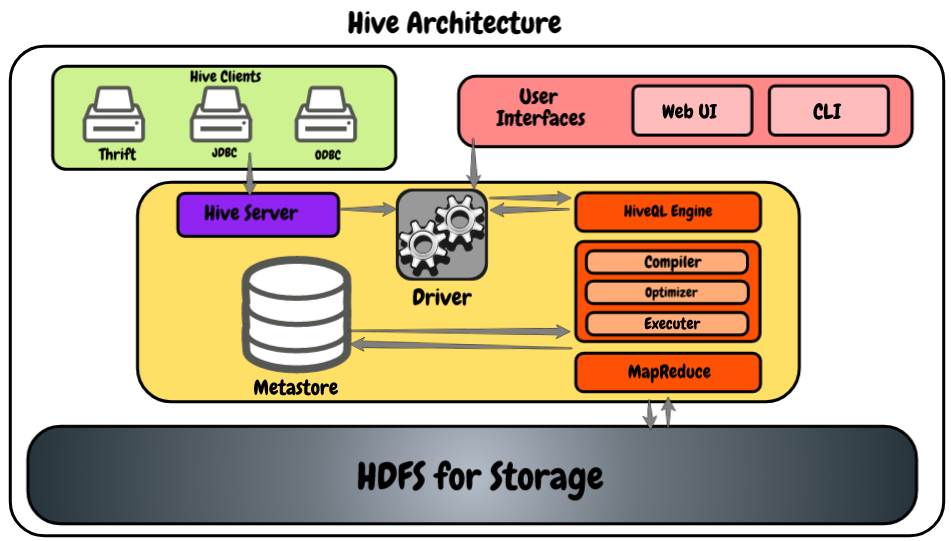
- Clienti Hive: Ci consente di scrivere applicazioni Hive utilizzando diversi tipi di client, come server di salvataggio, il driver JDBC per applicazioni Java e Hive, ed è anche compatibile con le applicazioni che utilizzano il protocollo ODBC.
- Servizi dell'alveare: Come sviluppatore, se vogliamo elaborare dei dati, dobbiamo usare i servizi hive come hive CLI (Interfaccia a riga di comando). Oltre a quell'alveare, fornisce anche un'interfaccia basata sul web per eseguire le applicazioni hive.
- Autista dell'alveare: È in grado di ricevere query da più risorse come l'usato, JDBC e ODBS utilizzando il server hive e direttamente da hive CLI e interfaccia utente basata sul Web. Dopo aver ricevuto richieste, li trasferisce al compilatore.
- Motore HiveQL: Riceve la query dal compilatore e converte la query di tipo SQL per mappare i lavori di riduzione.
- Meta negozio: Qui Hive memorizza le meta informazioni sui database come schema della tabella, i tipi di dati delle colonne, la ubicación en el HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni.., eccetera.
- HDFS: Es simplemente el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... de Hadoop que se utiliza para almacenar los datos. Consiglio vivamente di leggere questo articolo per saperne di più su HDFS: Introduzione all'ecosistema Hadoop
Lavoro Apache Hive
Ora, Diamo un'occhiata a come funziona Hive sul framework Hadoop.
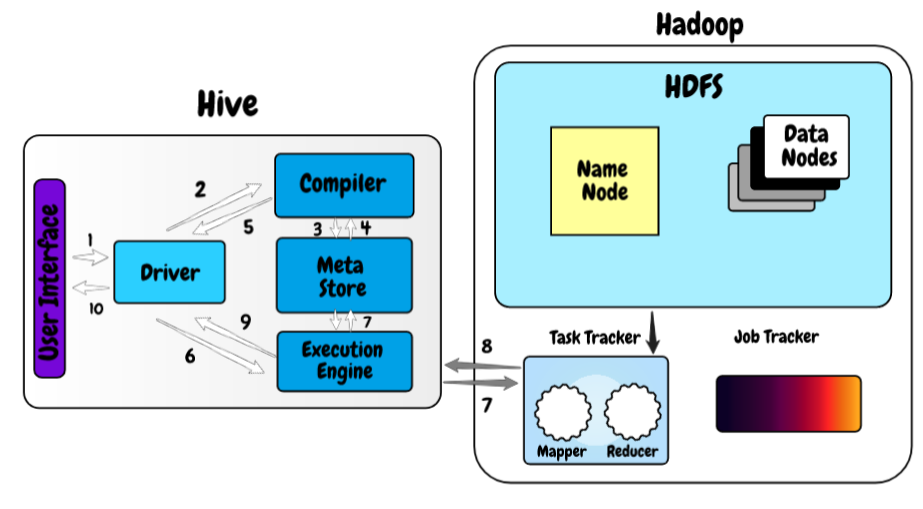
- Nel primo passo, scriviamo la query utilizzando l'interfaccia web o l'interfaccia a riga di comando dell'alveare. Lo invia al controller per eseguire la query.
- Nel prossimo passo, il controller invia la query ricevuta al compilatore dove il compilatore controlla la sintassi.
- E una volta eseguito il controllo della sintassi, richiedi i metadati dal meta store.
- Ora, i metadati forniscono informazioni come il database, tavole, tipi di dati di colonna in risposta alla query del compilatore.
- Il compilatore controlla nuovamente tutti i requisiti ricevuti dal meta store e invia il piano di esecuzione al controller.
- Ora, il controller invia il piano di esecuzione al motore di processo HiveQL, dove il motore converte la query nel lavoro di riduzione della mappa.
- Una volta che la query diventa il lavoro di riduzione della mappa, invia le informazioni sull'attività ad Hadoop dove inizia l'elaborazione della query e, allo stesso tempo, aggiorna i metadati sul lavoro di riduzione della mappa nel meta store.
- Una volta terminata la lavorazione, il runtime riceve i risultati della query.
- Il runtime trasferisce i risultati al controller e, Finalmente, li invia all'interfaccia utente di hive da dove possiamo vedere i risultati.
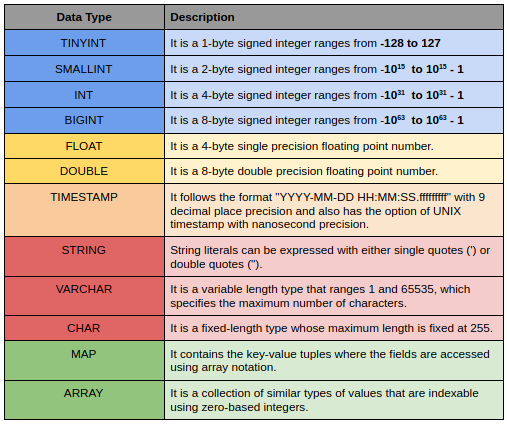
Tipi di dati in Apache Hive
I tipi di dati Hive sono suddivisi nei seguenti elementi 5 diverse categorie:
- tipo numerico: TINYINT, SMALLINT, INT, BIGINT
- Tipi di data / ora: ORA, DATA, ROTTURA
- Tipi di corde: CORDA, VARCHAR, CHAR
- tipi complessi: STRUTTURA, CARTA GEOGRAFICA, UNIONE, VETTORE
- Vari tipi: BOOLEO, BINARIO
Ecco una piccola descrizione di alcuni di loro.
Crea ed elimina database
La creazione e l'eliminazione di un database è molto semplice e simile a SQL. Dobbiamo assegnare un nome univoco a ciascuno dei database dell'alveare. Se il database esiste già, mostrerà un avviso e per sopprimere questo avviso puoi aggiungere le parole chiave SE NON ESISTE dopo la parola chiave del database.
CREA DATABASE <<nome del database>> ;
Anche l'eliminazione di un database è molto semplice, devi solo scrivere a eliminare il database e il nome del database essere abbandonato. Se provi a eliminare il database che non esiste, ti darà l'errore SemanticException.
DROP DATABASE <<nome del database>> ;
Crea tabella
Usiamo l'istruzione create table per creare una tabella e la sintassi completa è la seguente.
CREA TABELLA SE NON ESISTE <<nome del database.>><<nome_tabella>>
(nome_colonna_1 tipo_dati_1,
nome_colonna_2 tipo_dati_2,
.
.
nome_colonna_n tipo_dati_n)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY 't'
LINES TERMINATED BY 'n'
STORED AS TEXTFILE;
Se si sta già utilizzando il database, non è necessario digitare nome_tabella_nombre_base_datos. Quindi, È possibile digitare solo il nome della tabella. Nel caso dei Big Data, il più delle volte importiamo i dati da file esterni in modo che qui possiamo predefinire il delimitatore utilizzato nel file, terminatore di linea e possiamo anche definire come vogliamo memorizzare la tabella.
Ci sono 2 diversi tipi di tavoli alveare Tavoli interni ed esterni. Dai un'occhiata a questo articolo per saperne di più sul concetto: Tipi di tabella in Apache Hive: una rapida panoramica
Carica i dati nella tabella
Ora, le tabelle sono state create. È ora di caricare i dati al suo interno. Possiamo caricare i dati da qualsiasi file locale sul nostro sistema utilizzando la seguente sintassi.
CARICARE I DATI INPATH LOCALE <<percorso del file sul tuo sistema locale>>
IN TABELLA
<<nome del database.>><<nome_tabella>> ;
Quando lavoriamo con una grande quantità di dati, esiste la possibilità di avere tipi di dati non corrispondenti in alcune righe. Quindi, l'alveare non genererà alcun errore, invece riempirà invece i valori null. Questa è una funzione molto utile, poiché il caricamento di file di big data nell'alveare è un processo costoso e non vogliamo caricare l'intero set di dati solo perché abbiamo pochi file.
Modifica tabella
Nell'alveare, possiamo apportare diverse modifiche alle tabelle esistenti, Come rinominare le tabelle, Aggiungere altre colonne alla tabella. I comandi per modificare la tabella sono molto simili ai comandi SQL.
Ecco la sintassi per rinominare la tabella:
ALTERA TABELLA <<nome_tabella>> RINOMINA IN <<new_name>> ;
Sintassi per l'aggiunta di altre colonne nella tabella:
## to add more columns
ALTER TABLE <<nome_tabella>> AGGIUNGERE COLONNE
(new_column_name_1 data_type_1,
new_column_name_2 data_type_2,
.
.
new_column_name_n data_type_n) ;
Vantaggio / svantaggi di Apache Hive
- Utilizza SQL come linguaggio di query già familiare alla maggior parte degli sviluppatori, quindi ne facilita l'uso.
- È altamente scalabile, È possibile utilizzarlo per elaborare dati di qualsiasi dimensione.
- Supporta più database come MySQL, Derby, Postgres e Oracle per il tuo archivio di metadati.
- Supporta più formati di dati e consente anche l'indicizzazione, partizione e gruppo per ottimizzare le query.
- Può gestire solo dati freddi ed è inutile quando si tratta di elaborazione dati in tempo reale.
- È relativamente più lento di alcuni dei suoi concorrenti. Se il tuo caso d'uso riguarda principalmente l'elaborazione in batch, L'alveare va bene.
Note finali
In questo articolo, Abbiamo visto l'architettura di Apache Hive e come funziona e alcune delle operazioni di base per iniziare. Nel prossimo articolo di questa serie, veremos algunos de los conceptos más complejos e importantes de partición y raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. en una colmena.
Se hai domande relative a questo articolo, fammi sapere nella sezione commenti qui sotto.





