Panoramica
- L'ingegneria delle funzionalità in PNL riguarda la comprensione del contesto del testo.
- In questo blog, esamineremo alcune delle caratteristiche ingegneristiche comuni nella PNL.
- Confronteremo i risultati di un'attività di classificazione con e senza eseguire l'ingegneria delle funzionalità.
Sommario
- introduzione
- Panoramica delle attività di PNL
- Elenco delle funzionalità con codice
- Implementazione
- Confronto dei risultati con e senza ingegneria delle funzioni
- conclusione
introduzione
“Se lui 80 la percentuale del nostro lavoro è la preparazione dei dati, garantire la qualità dei dati è il compito importante di un team di machine learning”. – Andrea Nga

L'ingegneria delle funzioni è uno dei passaggi più importanti nell'apprendimento automatico. È il processo di utilizzo della conoscenza del dominio dei dati per creare caratteristiche che fanno funzionare gli algoritmi di apprendimento automatico.. Pensa all'algoritmo di apprendimento automatico come a un bambino che impara; più accurate sono le informazioni fornite, più sapranno interpretare bene le informazioni. Concentrarci prima sui nostri dati ci darà risultati migliori rispetto a concentrarci solo sui modelli. L'ingegneria delle funzionalità ci aiuta a creare dati migliori che aiutano il modello a comprenderli bene e a fornire risultati ragionevoli.
La PNL è un sottocampo dell'intelligenza artificiale in cui comprendiamo l'interazione umana con le macchine usando linguaggi naturali. Per capire un linguaggio naturale, è necessario capire come si scrive una frase, come esprimiamo i nostri pensieri usando parole diverse, segni, personaggi speciali, eccetera., fondamentalmente dobbiamo capire il contesto della frase per interpretarne il significato.
Se possiamo usare questi contesti come caratteristiche e inserirli nel nostro modello, allora il modello potrà capire meglio la frase. Alcune delle caratteristiche comuni che possiamo estrarre da una frase sono il numero di parole, il numero di parole maiuscole, il numero del punteggio, il numero di parole uniche, il numero di parole vuote, la lunghezza media della frase, eccetera. Possiamo definire queste caratteristiche in base al nostro set di dati che stiamo utilizzando. In questo blog, useremo un set di dati di Twitter in modo da poter aggiungere alcune altre caratteristiche come il numero di hashtag, la quantità di menzioni, eccetera. Li discuteremo in dettaglio nelle sezioni successive..
Panoramica delle attività di PNL
Comprendere il compito dell'ingegneria delle funzioni in PNL, lo implementeremo in un set di dati di Twitter. Noi useremo Set di dati sulle notizie false sul COVID-19. Il compito è classificare il tweet come Impostore oh Vero. Il set di dati è diviso in train, validazione e test set. Di seguito la distribuzione,
| Spezzare | Vero | Impostore | Totale |
| Treno | 3360 | 3060 | 6420 |
| Convalida | 1120 | 1020 | 2140 |
| Test | 1120 | 1020 | 2140 |
Elenco delle caratteristiche
Elencherò un totale di 15 caratteristiche che possiamo usare per il set di dati di cui sopra, il numero di funzionalità dipende totalmente dal tipo di set di dati che stai utilizzando.
1. Numero di caratteri
Conta il numero di caratteri presenti in un tweet.
def count_chars(testo):
tornare indietro(testo)
2. Numero di parole
Conta il numero di parole presenti in un tweet.
def count_words(testo):
tornare indietro(text.split())
3. Numero lettere maiuscole
Conta il numero di caratteri maiuscoli presenti in un tweet.
def count_capital_chars(testo):
conteggio=0
per io nel testo:
se io.i supper():
conteggio+=1
conteggio dei resi
4. Numero di parole maiuscole
Conta il numero di parole maiuscole presenti in un tweet.
def count_capital_words(testo):
restituire la somma(carta geografica(str.isupper,text.split()))
5. Conta il numero di punteggi
In questa funzione, restituiamo un dizionario di 32 segni di punteggiatura con i conteggi, che possono essere utilizzati come funzionalità indipendenti, di cui parlerò nella prossima sezione.
def count_punctuations(testo):
punteggiatura="!"#$%&"()*+,-./:;<=>[e-mail protetta][]^_`{|}~'
d=dict()
per io in punteggiatura:
D[str(io)+' contare']=conta.testo(io)
ritorno d
6. Numero di parole tra virgolette
Il numero di parole tra virgolette singole e virgolette doppie.
def count_words_in_quotes(testo):
x = re.trovare("'.'|"."", testo)
conteggio=0
se x è Nessuno:
Restituzione 0
altro:
per io in x:
t=i[1:-1]
conta+=conta_parole
conteggio dei resi
7. Numero di frasi
Conta il numero di frasi in un tweet.
def count_sent(testo):
tornare indietro(nltk.sent_tokenize(testo))
8. Conta il numero di parole uniche.
Conta il numero di parole uniche in un tweet.
def count_unique_words(testo):
tornare indietro(set(text.split()))
9. Conteggio hashtag
Dal momento che stiamo utilizzando il set di dati di Twitter, possiamo contare il numero di volte in cui gli utenti hanno utilizzato l'hashtag.
def count_htags(testo):
x = re.trovare(R'(#w[A-Za-z0-9]*)', testo)
tornare indietro(X)
10. Menzione conteggio
e Twitter, la maggior parte delle volte le persone rispondono o menzionano qualcuno nei loro tweet, anche il conteggio del numero di menzioni può essere trattato come una caratteristica.
def count_menzioni(testo):
x = re.trovare(R'(@w[A-Za-z0-9]*)', testo)
tornare indietro(X)
11. Conteggio parole vuote
Qui conteremo il numero di stopword usate in un tweet.
def count_stopwords(testo):
stop_words = set(stopwords.parole('inglese'))
word_tokens = word_tokenize(testo)
stopwords_x = [w per w in word_tokens se w in stop_words]
tornare indietro(stopwords_x)
12. Calcola la lunghezza media delle parole
Questo può essere calcolato dividendo il numero di caratteri per il numero di parole.
df['avg_wordlength'] = df['char_count']/df['conta_parole']
13. Calcolo della lunghezza media delle frasi
Questo può essere calcolato dividendo il conteggio delle parole per il conteggio delle frasi.
df['media_sentlength'] = df['conta_parole']/df['sent_count']
14. parole uniche vs funzione di conteggio delle parole
Questa caratteristica è fondamentalmente il rapporto tra parole uniche e un numero totale di parole.
df['unique_vs_words'] = df['unique_word_count']/df['conta_parole']
15. Interrompi conteggio parole e funzione conteggio parole
Questa caratteristica è anche la relazione tra il numero di stopword e il numero totale di parole.
df['stopwords_vs_words'] = df['stopword_count']/df['conta_parole']
Implementazione
Puoi scaricare il set di dati da qui. Dopo il download, possiamo iniziare a implementare tutte le funzioni che abbiamo definito sopra. Ci concentreremo maggiormente sull'ingegneria delle funzioni, per questo manterremo l'approccio semplice, utilizzando TF-IDF e semplice pre-elaborazione. Tutto il codice sarà disponibile nel mio repository GitHub https://github.com/ahmadkhan242/Feature-Engineering-in-NLP.
-
Lettura del treno, validazione e test suite con panda.
treno = pd.read_csv("treno.csv") val = pd.read_csv("validation.csv") test = pd.read_csv(testWithLabel.csv") # Per questo compito combineremo il set di dati di treno e convalida e quindi utilizzeremo # semplice test del treno diviso da sklern. df = pd.concat([treno, valore]) df.head()
-
Applicare l'estrazione delle caratteristiche precedentemente definita sul treno e sul set di prova.
df['char_count'] = df["tweet"].applicare(lambda x:count_chars(X)) df['conta_parole'] = df["tweet"].applicare(lambda x:conta_parole(X)) df['sent_count'] = df["tweet"].applicare(lambda x:count_sent(X)) df['capital_char_count'] = df["tweet"].applicare(lambda x:count_capital_chars(X)) df['capital_word_count'] = df["tweet"].applicare(lambda x:conta_parole_maiuscole(X)) df['quoted_word_count'] = df["tweet"].applicare(lambda x:conta_parole_tra_citazioni(X)) df['stopword_count'] = df["tweet"].applicare(lambda x:count_stopwords(X)) df['unique_word_count'] = df["tweet"].applicare(lambda x:count_unique_words(X)) df['htag_count'] = df["tweet"].applicare(lambda x:count_htags(X)) df['menzione_conteggio'] = df["tweet"].applicare(lambda x:count_menzioni(X)) df['punct_count'] = df["tweet"].applicare(lambda x:count_punctuations(X)) df['avg_wordlength'] = df['char_count']/df['conta_parole'] df['media_sentlength'] = df['conta_parole']/df['sent_count'] df['unique_vs_words'] = df['unique_word_count']/df['conta_parole'] df['stopwords_vs_words'] = df['stopword_count']/df['conta_parole'] # ANALOGAMENTE PUOI APPLICARLI SU TEST SET
-
aggiunta di alcune funzionalità aggiuntive utilizzando il conteggio del punteggio
Creeremo un DataFrame dal dizionario restituito dalla funzione "punct_count" e poi lo fonderemo con il set di dati principale.
df_punct = pd.DataFrame(elenco(df.punct_count)) test_punct = pd.DataFrame(elenco(test.punct_count)) # Unire la punteggiatura DataFrame con DataFrame principale df = pd.merge(df, df_punct, left_index=Vero, right_index=Vero) test = pd.merge(test, test_punct,left_index=Vero, right_index=Vero)
# possiamo lasciar perdere "punt_count" colonna sia da df che da test DataFrame df.drop(colonne=['punct_count'],inplace=Vero) test.drop(colonne=['punct_count'],inplace=Vero) df.colonne
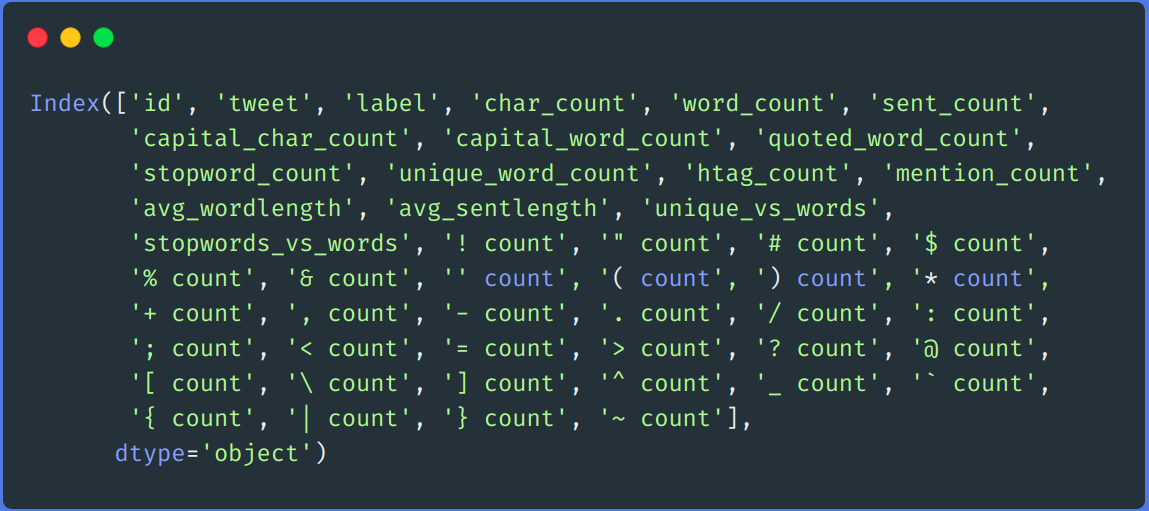
-
ritrattamento
Eseguiamo un semplice passaggio prima della lavorazione, come rimuovere i collegamenti, rimuovi nome utente, numeri, doppio spazio, punteggiatura, minuscolo, eccetera.
def remove_links(tweet): '''Prende una stringa e rimuove i collegamenti web da essa''' tweet = re.sub(r'httpS+', '', tweet) # rimuovere i collegamenti http tweet = re.sub(r'bit.ly/S+', '', tweet) # rempve bitly link tweet = tweet.striscia('https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/ ') # rimuovere [link] ritorna tweet def remove_users(tweet): '''Prende una stringa e rimuove retweet e @informazioni utente''' tweet = re.sub('([e-mail protetta][A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # rimuovi retweet tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # rimuovere tweeted a ritorna tweet mia_punteggiatura = '!"$%&'()*+,-./:;<=>?[]^_`{|}~•@' def preprocesso(spedito): inviato = remove_users(spedito) inviato = remove_links(spedito) inviato = inviato.inferiore() # minuscolo inviato = re.sub('['+mia_punteggiatura + ']+', ' ', spedito) # punteggiatura a strisce inviato = re.sub('s+', ' ', spedito) #rimuovi la doppia spaziatura inviato = re.sub('([0-9]+)', '', spedito) # rimuovi i numeri sent_token_list = [parola per parola in sent.split(' ')] inviato=" ".aderire(sent_token_list) ritorno inviato df['twittare'] = df['twittare'].applicare(lambda x: preprocesso(X)) test['twittare'] = prova['twittare'].applicare(lambda x: preprocesso(X))
-
Codifica del testo
Codificheremo i nostri dati di testo utilizzando TF-IDF. Per prima cosa installiamo la trasformazione sulla nostra colonna tweet del treno e sul set di test e poi la uniamo con tutte le colonne delle funzioni.
vectorizer = TfidfVectorizer() train_tf_idf_features = vectorizer.fit_transform(df['twittare']).toarray() test_tf_idf_features = vectorizer.transform(test['twittare']).toarray() # Conversione dell'elenco sopra in DataFrame train_tf_idf = pd.DataFrame(train_tf_idf_features) test_tf_idf = pd.DataFrame(test_tf_idf_features) # Separare le etichette dei treni e dei test da tutte le caratteristiche train_Y = df['etichetta'] test_Y = test['etichetta'] #Elenco di tutte le funzionalità caratteristiche = ['char_count', 'conta_parole', 'sent_count', 'capital_char_count', 'capital_word_count', 'quoted_word_count', 'stopword_count', 'unique_word_count', 'htag_count', 'menzione_conteggio', 'avg_wordlength', 'media_sentlength', 'unique_vs_words', 'stopwords_vs_words', '! contare', '" contare', '# contare', '$ conteggio', '% contare', '& contare', '' contare', '( contare', ') contare', '* contare', '+ conta', ', contare', '- contare', '. contare', '/ contare', ': contare', '; contare', '< contare', '= contare', '> contare', '? contare', '@ contare', '[ contare', ' contare', '] contare', '^ contare', '_ contare', '`contare', '{ contare', '| contare', '} contare', '~ contare'] # Finalmente unendo tutte le funzionalità con TF-IDF sopra. train = pd.merge(train_tf_idf,df[caratteristiche],left_index=Vero, right_index=Vero) test = pd.merge(test_tf_idf,test[caratteristiche],left_index=Vero, right_index=Vero) -
Addestramento
Per lui addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., useremo l'algoritmo della foresta casuale dalla libreria di apprendimento di sci-kit.
X_treno, X_test, y_train, y_test = train_test_split(treno, train_Y, test_size=0.2, stato_casuale = 42) # Classificatore forestale casuale clf_model = RandomForestClassifier(n_estimatori = 1000, min_samples_split = 15, stato_casuale = 42) clf_model.in forma(X_treno, y_train) _RandomForestClassifier_prediction = clf_model.predict(X_test) val_RandomForestClassifier_prediction = clf_model.predict(test)
Confronto dei risultati
Per confronto, prima addestriamo il nostro modello sul set di dati sopra utilizzando tecniche di ingegneria delle caratteristiche e poi senza utilizzare tecniche di ingegneria delle caratteristiche. In entrambi gli approcci, abbiamo preelaborato il set di dati utilizzando lo stesso metodo descritto sopra e TF-IDF è stato utilizzato in entrambi gli approcci per codificare i dati di testo. Puoi usare qualsiasi tecnica di codifica tu voglia, come word2vec, guanto, eccetera.
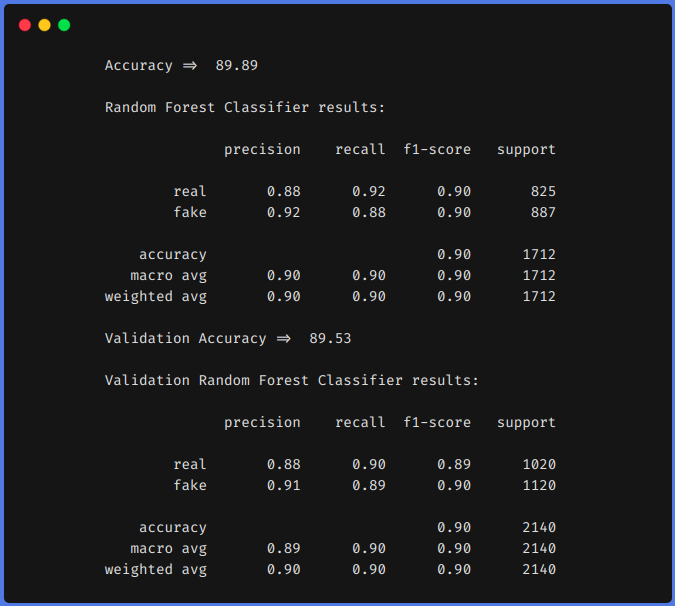
1. Senza utilizzare tecniche di ingegneria delle funzioni
2. Utilizzo di tecniche di ingegneria funzionale
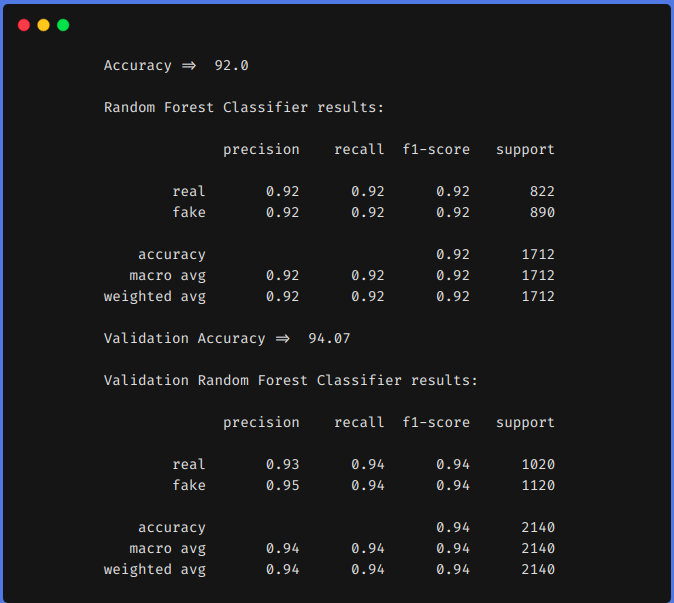
Dai risultati precedenti, possiamo vedere che le tecniche di ingegneria delle funzionalità ci hanno aiutato ad aumentare il nostro f1 a partire dal 0,90 fino a 0,92 in treno e da 0,90 fino a 0,94 nella squadra di prova.
conclusione
I risultati di cui sopra mostrano che se eseguiamo l'ingegneria delle funzioni, possiamo ottenere una maggiore precisione utilizzando i classici algoritmi di apprendimento automatico. L'utilizzo di un modello basato su trasformatore è un algoritmo che richiede tempo e risorse. Se eseguiamo l'ingegneria delle funzioni nel modo giusto, vale a dire, dopo aver analizzato il nostro set di dati, possiamo ottenere risultati comparabili.
Possiamo anche fare qualche altra ingegneria delle funzionalità, come contare il numero di emoji utilizzati, il tipo di emoji utilizzati, quali frequenze di parole uniche, eccetera. Possiamo definire le nostre caratteristiche analizzando il set di dati. Spero che tu abbia imparato qualcosa da questo blog, condividilo con gli altri. Dai un'occhiata al mio blog personale sull'apprendimento automatico (https://code-ml.com/) per ottenere contenuti nuovi ed entusiasmanti in diversi domini di ML e AI.
Circa l'autore
Mohammad Ahmad (B.Tech) LinkedIn - https://www.linkedin.com/in/mohammad-ahmad-ai/ Blog personale - https://codice-ml.com/ GitHub - https://github.com/ahmadkhan242 Twitter - https://twitter.com/ahmadkhan_242
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





