introduzione

Sommario
- Perché dovremmo usare l'ingegneria delle funzioni nella scienza dei dati??
- Selezione delle funzioni
- Gestione dei valori mancanti
- Gestione dei dati sbilanciati
- Gestione degli outlier
- Binning
- codifica
- Scala delle funzioni
1. Perché dovremmo usare l'ingegneria delle funzioni nella scienza dei dati??
En Data Science, le prestazioni del modello dipendono dalla pre-elaborazione e dalla gestione dei dati. Supponiamo che se costruiamo un modello senza la gestione dei dati, otteniamo una precisione di circa 70%. Applicando l'ingegneria delle funzioni sullo stesso modello, c'è la possibilità di aumentare le prestazioni del 70% di più.
Semplicemente, quando si utilizza l'ingegneria delle funzioni, miglioriamo le prestazioni del modello.
2. Selezione delle funzioni
La selezione delle funzioni non è altro che una selezione delle necessarie funzioni indipendenti. La selezione delle caratteristiche indipendenti importanti che sono maggiormente correlate alla caratteristica dipendente aiuterà a costruire un buon modello.. Esistono alcuni metodi per selezionare le funzioni:
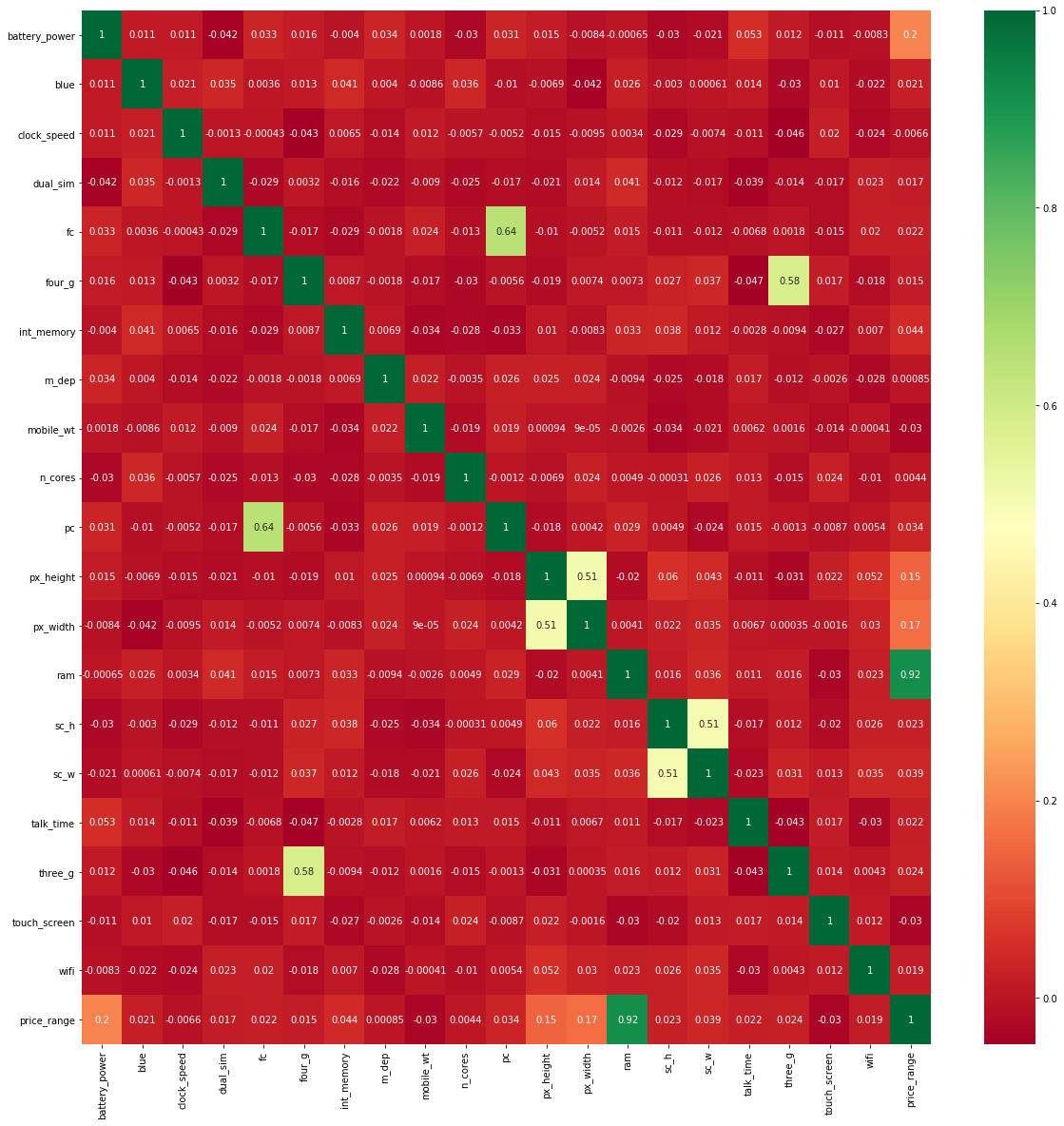
2.1 Matrice di correlazione con mappa termica
Il mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... es una representación gráfica de datos 2D (bidimensionale). Ogni valore dei dati è rappresentato in un array.
Primo, disegnare il grafico delle coppie tra tutte le caratteristiche indipendenti e le caratteristiche dipendenti. Darà la relazione tra caratteristiche dipendenti e indipendenti. La relazione tra la caratteristica indipendente e la caratteristica dipendente è minore di 0.2, quindi scegli quella caratteristica indipendente per costruire un modello.
2.2 Selezione univariata
In questo, i test statistici possono essere utilizzati per selezionare le caratteristiche indipendenti che hanno la relazione più forte con la caratteristica dipendente. Seleziona KBest Il metodo può essere utilizzato con una serie di diversi test statistici per selezionare un numero specifico di caratteristiche.
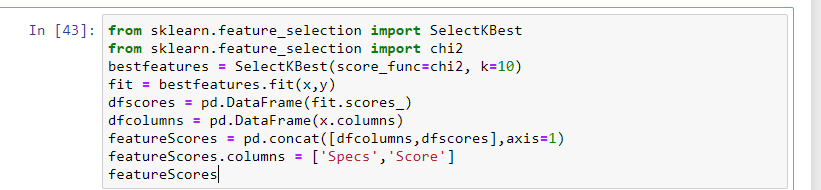
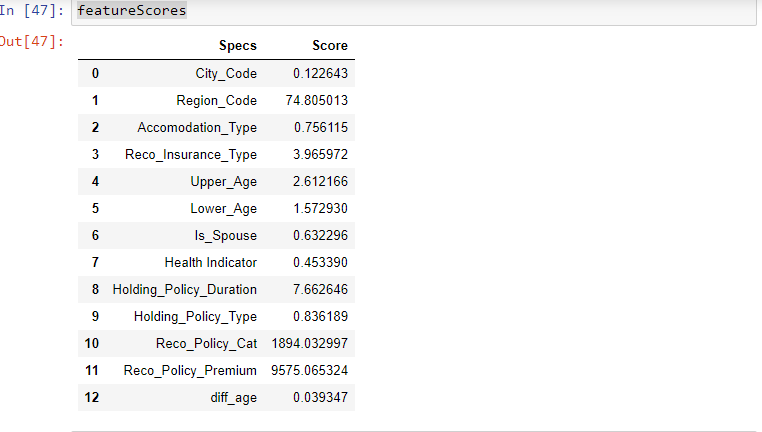
- La caratteristica che ha il punteggio più alto sarà più correlata alla caratteristica dipendente e sceglierà quelle caratteristiche per il modello.
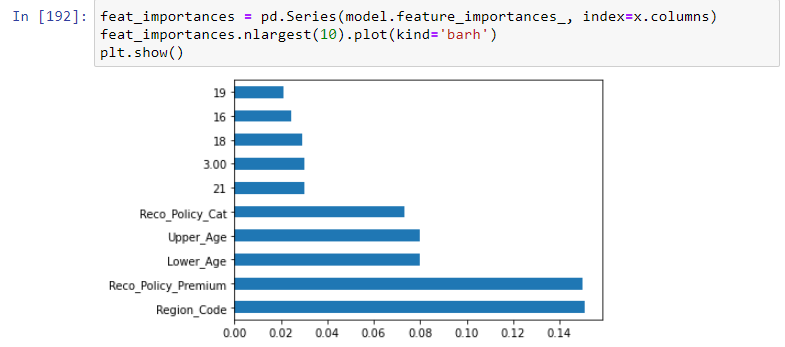
2.3 Metodo ExtraTreesClassifier
In questo metodo, il metodo ExtraTreesClassifier aiuterà a dare l'importanza di ogni caratteristica indipendente con una caratteristica dipendente. L'importanza del ruolo ti darà un punteggio per ogni ruolo nei tuoi dati, più alto è il punteggio, más importante o relevante para la función con respecto a su variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de salida.

3. Gestione dei valori mancanti
In alcuni set di dati, abbiamo ottenuto i valori di NA nelle caratteristiche. Mancano solo dati. Per gestire questo tipo di dati ci sono molti modi:
- Nei luoghi dei valori perduti, para reemplazar los valores perdidos con la media o medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... en los datos numéricos y para los datos categóricos con la moda.

- Elimina i valori NA in intere righe.

- Elimina i valori NA per funzionalità complete. (aiuta se i valori di NA sono superiori a 50% in una funzione)

- Sostituisci i valori NA con 0.

Se scegli di scartare le opzioni, c'è la possibilità di perdere informazioni importanti da loro. Quindi è meglio scegliere di sostituire le opzioni.
4. Gestione dei dati sbilanciati
Perché è necessario gestire dati sbilanciati? A causa di ridurre il problema di sovradattamento e disadattamento.
supponiamo una caratteristica ha un fattore level2 (0 e 1). consiste di 1 è 5% e 0 è 95%. Si chiamano dati sbilanciati.
Esempio:-

Per prevenire questo problema, ci sono alcuni metodi:
4.1 Classe di maggioranza sottocampionata
Un sottocampionamento della classe di maggioranza ricampionerà i punti della classe di maggioranza nei dati per renderli uguali alla classe di minoranza.

4.2 Duplicazione sovracampionamento classe di minoranza
Il sovracampionamento della classe di minoranza ricampionerà i punti della classe di minoranza nei dati per renderli uguali alla classe di maggioranza.

4.3 Sovracampionamento della classe di minoranza utilizzando la tecnica del sovracampionamento sintetico di minoranza (SMOTE)
In questo metodo, vengono generati campioni sintetici per la classe di minoranza e uguali alla classe di maggioranza.

5. Gestione degli outlier
Primo, calcola l'asimmetria delle caratteristiche e controlla se sono distorte positivamente, negativamente o normalmente di parte. Un altro metodo consiste nel tracciare il box plot sulle caratteristiche e verificare se un valore è fuori limite o meno.. se esistono, sono chiamati outlier.
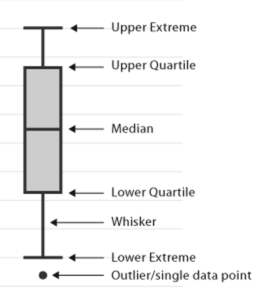
come gestire questi valori anomali?: –
Primo, calcolare i valori dei quantili a 25% e 75%.

- prossimo, calcolare l'intervallo interquartile
IQR = Q3 – Q1

- Prossimo, calcolare i valori degli estremi superiore e inferiore.
estremità inferiore = Q1 – 1,5 * IQR
estremità superiore = Q3– 1,5 * IQRe
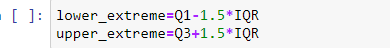
- finalmente, controlla che i valori siano al di sopra del limite superiore o al di sotto del limite inferiore. se si presenta, rimuoverli o sostituirli con la calza, la mediana o qualsiasi valore quantile.
- Sostituisci gli outlier con mean

- Sostituisci valori anomali con valori quantili


6. Binning
Il raggruppamento non è altro che qualsiasi valore di dati all'interno dell'intervallo che si adatta al cestino. È importante nella tua attività di esplorazione dei dati. Normalmente lo usiamo per trasformare le variabili continue in discrete..
Supponiamo che se abbiamo la funzione ETÀ continuamente e dobbiamo dividere l'età in gruppi come una funzione, allora sarà utile.
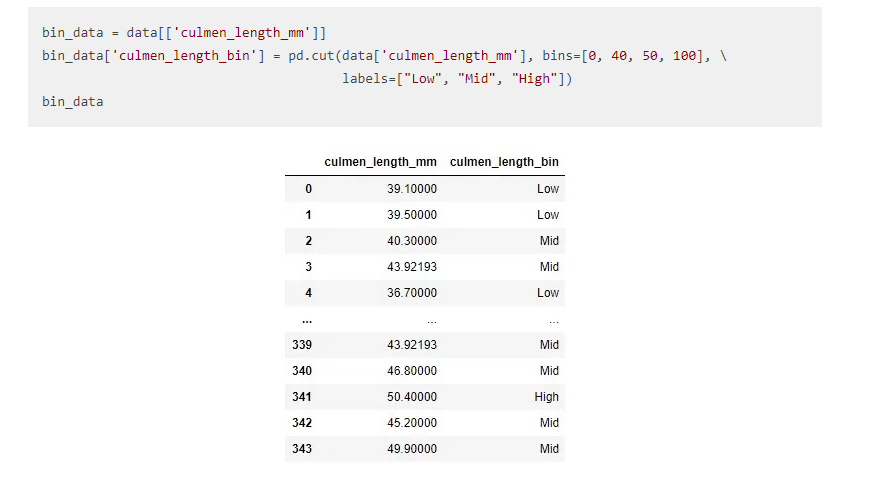
7. codifica:
Perché questo si applica?? perché nei set di dati possiamo contenere tipi di dati di oggetti. per costruire un modello, abbiamo bisogno che tutte le funzionalità siano in tipi di dati interi. così, Label Encoder e OneHotEncoder vengono utilizzati per convertire il tipo di dati dell'oggetto in un tipo di dati intero.

Prima di applicare la codifica dei tag
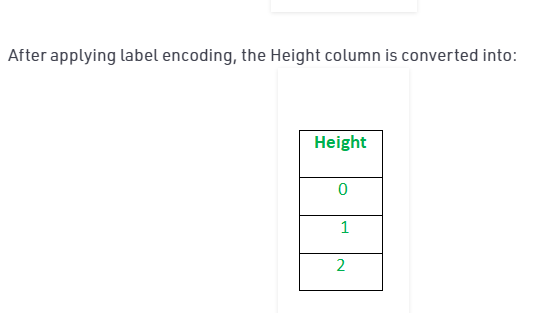
Dopo aver applicato la codifica dei tag, applica il metodo del trasformatore di colonna per convertire le etichette in 0 e 1

Al aplicar get_dummies, convertiamo direttamente da categorico a numerico

8. Scala delle funzioni
Perché viene applicata questa scala?? perché per ridurre l'effetto della varianza e superare il problema dell'adattamento. ci sono due tipi di metodi di ridimensionamento:
8.1 Standardizzazione
Quando viene utilizzato questo metodo? ?. quando tutte le caratteristiche hanno valori alti, no 0 e 1.
È una tecnica per standardizzare le caratteristiche indipendenti che si verificano in un intervallo fisso per portare tutti i valori alle stesse grandezze..
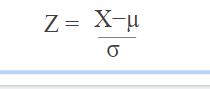
Nella standardizzazione, la media delle caratteristiche indipendenti è 0 e la deviazione standard è 1.
Metodo 1:

Metodo 2:

Dopo la codifica, le etichette delle caratteristiche sono attive 0 e 1. Questo può influenzare la standardizzazione. Per superare questo, noi usiamo NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.....
8.2 Normalizzazione
La normalización también hace que el proceso de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... sea menos sensible por la escala de las características. Ciò si traduce nell'ottenimento di coefficienti migliori dopo l'allenamento..
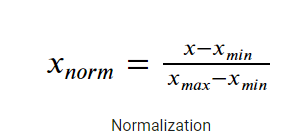
Metodo 1: -MinMaxScaler
È un metodo per ridimensionare la caratteristica a una gamma rapida e rigorosa di [0,1] sottraendo il valore minimo della caratteristica e quindi dividendo per l'intervallo.


Metodo 2: – Normalizzazione media
È un metodo per ridimensionare la caratteristica a una gamma rapida e rigorosa di [-1,1] con media = 0.
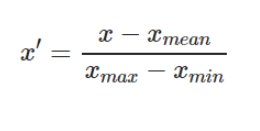


Note finali: –
In questo articolo, Ho seguito passo passo il processo di ingegneria delle funzioni. Questo è molto utile per aumentare la precisione della previsione..
Tieni presente che non esistono metodi particolari per aumentare la precisione della tua previsione. Tutto dipende dai tuoi dati e applica più metodi.
Come prossimo passo, Ti incoraggio a provare diversi set di dati e ad analizzarli. E non dimenticare di condividere le tue idee nella sezione commenti qui sotto!!
Circa l'autore:
Soia Pavan Kumar Reddy Elluru. Ho completato la mia laurea presso il G.Pullareddy Engineering College nell'anno 2020. Sono un data scientist certificato nell'anno 2021 y me apasiona el aprendizaje automático y los proyectos de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
Per favore, scrivimi in caso di domande o solo per salutare.
Identificazione e-mail:- [e-mail protetta]
Identificazione Linkedin: – www.linkedin.com/in/elluru-pavan-kumar-reddy-a1b183197
ID di Github: – pawankumarreddy1999 (Pavan Kumar Reddy Elluru) (github.com)





