Nota: Questo articolo è stato originariamente pubblicato in ottobre 6 a partire dal, 2015 e aggiornato il 13 settembre 2017
Panoramica
- Spiegazione della macchina vettoriale di supporto (SVM), un popolare algoritmo o classificazione di machine learning
- Implementazione di SVM in R e Python
- Scopri i pro e i contro di Support Vector Machines (SVM) e le sue diverse applicazioni
introduzione
Mastering algoritmi di apprendimento automatico non è affatto un mito. La maggior parte dei principianti inizia imparando la regressione. È semplice da imparare e da usare, ma questo risolve il nostro scopo?? Ovviamente no! Perché puoi fare molto di più della semplice regressione!!
Pensa agli algoritmi di apprendimento automatico come a un arsenale pieno di assi, spade, le foglie, arcos, pugnali, eccetera. Ha vari strumenti, ma devi imparare ad usarli al momento giusto. Per analogia, pensa alla "regressione"’ come una spada in grado di affettare e affettare i dati in modo efficiente, ma incapace di gestire dati molto complessi. al contrario, "Supporto macchine vettoriali"’ è come un coltello affilato: funziona su set di dati più piccoli, ma in insiemi complessi, può essere molto più forte e potente nella costruzione di modelli di apprendimento automatico.
In questa fase, Spero che tu abbia imparato Random Forest, l'algoritmo Naive Bayes e Modellazione d'insieme. Ma, Ti suggerisco di dedicare qualche minuto e leggere anche di loro. In questo articolo, Ti guiderò attraverso le basi per una conoscenza avanzata di un algoritmo di apprendimento automatico cruciale, macchine vettoriali di supporto.
Puoi ottenere informazioni sulle macchine vettoriali di supporto nel formato del corso qui (È gratis!):
Se sei un principiante e stai cercando di iniziare il tuo viaggio nella scienza dei dati, Siete venuti nel posto giusto! Dai un'occhiata ai corsi completi qui sotto, selezionati da esperti del settore, che abbiamo creato apposta per te:

Comprendere l'algoritmo Support Vector Machine dagli esempi (insieme al codice)
Sommario
- Che cos'è Support Vector Machine??
- Come funziona?
- Come implementare SVM in Python e R?
- ¿Cómo ajustar los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de SVM?
- Pro e contro associati a SVM
Qual è la macchina del vettore di supporto??
“Supporta la macchina vettoriale” (SVM) è un sistema supervisionato algoritmo di apprendimento automatico che può essere utilizzato per le sfide di classificazione o regressione. tuttavia, utilizzato principalmente nei problemi di classificazione. Nell'algoritmo SVM, tracciamo ogni elemento di dati come un punto nello spazio n-dimensionale (dove n è un numero di caratteristiche che ha) con il valore di ciascuna caratteristica essendo il valore di una particolare coordinata. Dopo, Eseguiamo la classificazione trovando l'iperpiano che differenzia molto bene le due classi (guarda l'istantanea qui sotto).
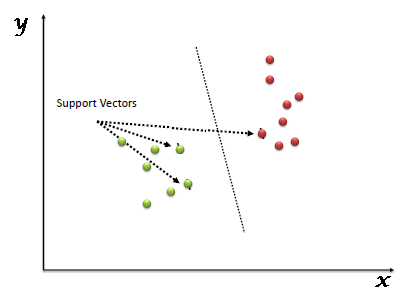
I vettori di supporto sono semplicemente le coordinate della singola osservazione. Il classificatore SVM è un confine che separa al meglio le due classi (iperpiano / linea).
Puoi vedere le macchine vettoriali di supporto e alcuni esempi di come funzionano qui.
Come funziona?
Al di sopra, ci abituiamo al processo di segregazione delle due classi con un iperpiano. Ora la domanda scottante è “Come possiamo identificare l'iperpiano corretto??”. Non preoccuparti, non è così difficile come pensi!
Facci capire:
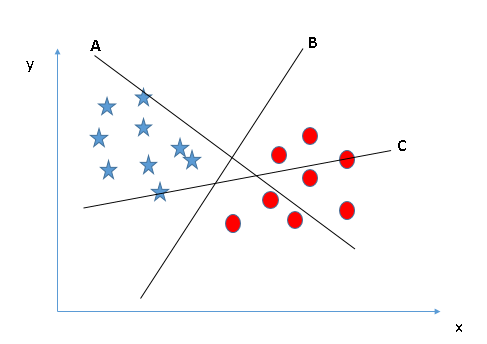
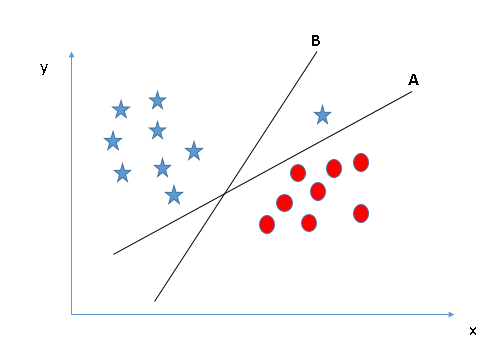
- Identificare l'iperpiano corretto (scenario 1): Qui, abbiamo tre iperpiani (UN, Per C). Ora, identificare l'iperpiano corretto per classificare stelle e cerchi.
 È necessario ricordare una regola empirica per identificare l'iperpiano corretto: “Seleziona l'iperpiano che meglio segrega le due classi”. In questa fase, l'iperpiano “B” ha svolto questo lavoro in modo eccellente.
È necessario ricordare una regola empirica per identificare l'iperpiano corretto: “Seleziona l'iperpiano che meglio segrega le due classi”. In questa fase, l'iperpiano “B” ha svolto questo lavoro in modo eccellente. - Identificare l'iperpiano corretto (Scenario-2): Qui, abbiamo tre iperpiani (UN, Per C) e tutti segregano bene le classi. Ora, Come possiamo identificare l'iperpiano corretto??
 Qui, massimizzare le distanze tra il punto dati più vicino (qualsiasi classe) e l'iperpiano ci aiuterà a decidere l'iperpiano corretto. Questa distanza si chiama MargineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale... Vediamo la prossima istantanea:
Qui, massimizzare le distanze tra il punto dati più vicino (qualsiasi classe) e l'iperpiano ci aiuterà a decidere l'iperpiano corretto. Questa distanza si chiama MargineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale... Vediamo la prossima istantanea:
Al di sopra, puoi vedere che il margine per l'iperpiano C è alto rispetto ad A e B. Perciò, chiamiamo l'iperpiano destro C. Un altro semplice motivo per selezionare l'iperpiano con un margine più alto è la robustezza. Se selezioniamo un iperpiano che ha un margine basso, c'è una grande possibilità di errata classificazione. - Identificare l'iperpiano corretto (Scenario-3):allusioni: Usa i righelli come discusso nella sezione precedente per identificare l'iperpiano corretto
 È necessario ricordare una regola empirica per identificare l'iperpiano corretto: “Seleziona l'iperpiano che meglio segrega le due classi”. In questa fase, l'iperpiano “B” ha svolto questo lavoro in modo eccellente.
È necessario ricordare una regola empirica per identificare l'iperpiano corretto: “Seleziona l'iperpiano che meglio segrega le due classi”. In questa fase, l'iperpiano “B” ha svolto questo lavoro in modo eccellente.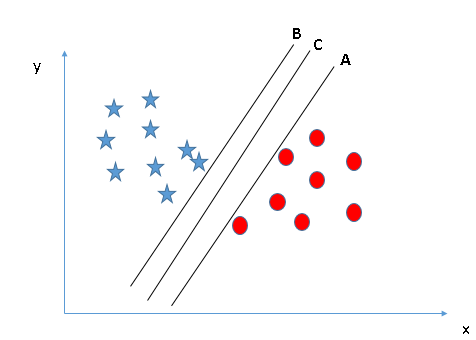 Qui, massimizzare le distanze tra il punto dati più vicino (qualsiasi classe) e l'iperpiano ci aiuterà a decidere l'iperpiano corretto. Questa distanza si chiama
Qui, massimizzare le distanze tra il punto dati più vicino (qualsiasi classe) e l'iperpiano ci aiuterà a decidere l'iperpiano corretto. Questa distanza si chiama 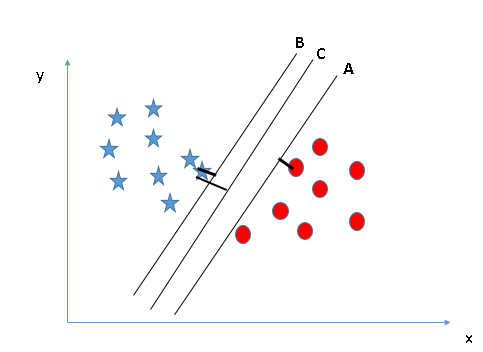
 Alcuni di voi potrebbero aver selezionato l'iperpiano B in quanto ha un margine maggiore rispetto a UN. Ma, ecco il trucco, SVM seleziona l'iperpiano che classifica accuratamente le classi prima di massimizzare il margine. Qui, l'iperpiano B ha un errore di classificazione e A ha classificato tutto correttamente. Perciò, l'iperpiano destro è UN.
Alcuni di voi potrebbero aver selezionato l'iperpiano B in quanto ha un margine maggiore rispetto a UN. Ma, ecco il trucco, SVM seleziona l'iperpiano che classifica accuratamente le classi prima di massimizzare il margine. Qui, l'iperpiano B ha un errore di classificazione e A ha classificato tutto correttamente. Perciò, l'iperpiano destro è UN.
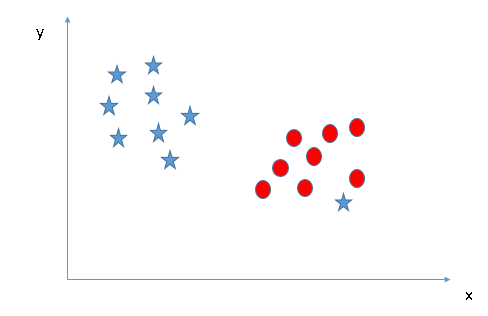
- Possiamo classificare due classi? (Scenario-4) ?: Prossimo, Non riesco a separare le due classi usando una linea retta, poiché una delle stelle è nel territorio dell'altra classe (cerchio) come un valore anomalo.
 Come ho già detto, una stella all'altra estremità è come un valore anomalo per la classe delle stelle. L'algoritmo SVM ha una funzione per ignorare i valori anomali e trovare l'iperpiano che ha il margine massimo. Perciò, possiamo dire che la classificazione SVM è robusta per gli outlier.
Come ho già detto, una stella all'altra estremità è come un valore anomalo per la classe delle stelle. L'algoritmo SVM ha una funzione per ignorare i valori anomali e trovare l'iperpiano che ha il margine massimo. Perciò, possiamo dire che la classificazione SVM è robusta per gli outlier.
- Trova l'iperpiano per separare le classi (Scenario-5): Nel seguente scenario, non possiamo avere un iperpiano lineare tra le due classi, poi, In che modo SVM classifica queste due classi?? Fino ad ora, abbiamo solo guardato l'iperpiano lineare.
 SVM può risolvere questo problema. Facilmente! Risolvi questo problema introducendo una funzionalità aggiuntiva. Qui, aggiungeremo una nuova funzionalità z = x ^ 2 + e ^ 2. Ora, tracciamo i punti dati sull'asse xez:
SVM può risolvere questo problema. Facilmente! Risolvi questo problema introducendo una funzionalità aggiuntiva. Qui, aggiungeremo una nuova funzionalità z = x ^ 2 + e ^ 2. Ora, tracciamo i punti dati sull'asse xez:
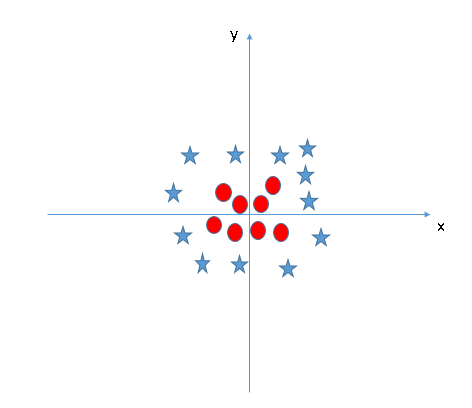
Nel grafico sopra, i punti da considerare sono:- Tutti i valori di z sarebbero sempre positivi perché z è la somma al quadrato di x e y
- Nella grafica originale, i cerchi rossi appaiono vicino all'origine degli assi x e y, che porta a un valore più basso di z e una stella relativamente lontana dall'origine risulta a un valore più alto di z.
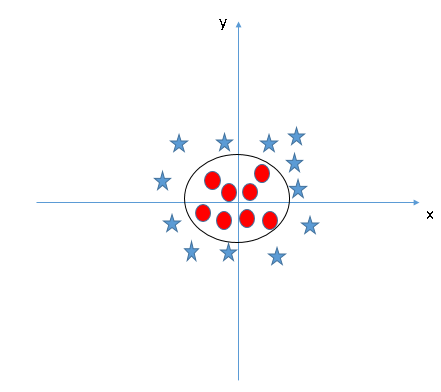
Nel classificatore SVM, è facile avere un iperpiano lineare tra queste due classi. Ma, un'altra domanda scottante che sorge è se dobbiamo aggiungere manualmente questa funzione per avere un iperpiano. No, l'algoritmo SVM ha una tecnica chiamata nucleo trucco. El kernel SVM es una función que toma un espacio de entrada de baja dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... y lo transforma en un espacio de mayor dimensión, vale a dire, converte un problema non separabile in un problema separabile. È particolarmente utile nei problemi di separazione non lineare. In poche parole, esegue alcune trasformazioni di dati estremamente complesse, quindi scopri il processo per separare i dati in base alle etichette o agli output che hai definito.
Quando osserviamo l'iperpiano nello spazio di input originale, sembra un cerchio:

 Come ho già detto, una stella all'altra estremità è come un valore anomalo per la classe delle stelle. L'algoritmo SVM ha una funzione per ignorare i valori anomali e trovare l'iperpiano che ha il margine massimo. Perciò, possiamo dire che la classificazione SVM è robusta per gli outlier.
Come ho già detto, una stella all'altra estremità è come un valore anomalo per la classe delle stelle. L'algoritmo SVM ha una funzione per ignorare i valori anomali e trovare l'iperpiano che ha il margine massimo. Perciò, possiamo dire che la classificazione SVM è robusta per gli outlier.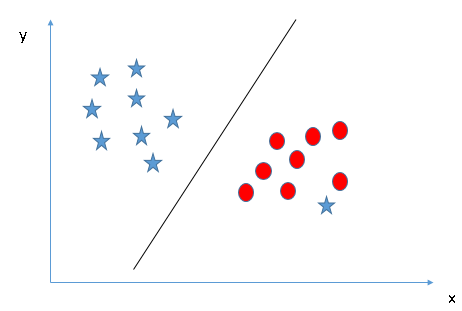
 SVM può risolvere questo problema. Facilmente! Risolvi questo problema introducendo una funzionalità aggiuntiva. Qui, aggiungeremo una nuova funzionalità z = x ^ 2 + e ^ 2. Ora, tracciamo i punti dati sull'asse xez:
SVM può risolvere questo problema. Facilmente! Risolvi questo problema introducendo una funzionalità aggiuntiva. Qui, aggiungeremo una nuova funzionalità z = x ^ 2 + e ^ 2. Ora, tracciamo i punti dati sull'asse xez: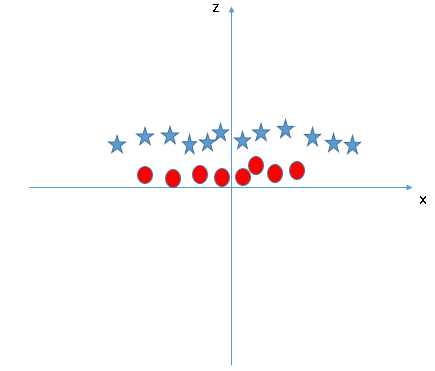
Ora, Vediamo i metodi per applicare l'algoritmo del classificatore SVM in una sfida di data science.
Puoi anche conoscere il funzionamento di Support Vector Machine in formato video da questo Certificazione di apprendimento automatico.
Come implementare SVM in Python e R?
e pitone, scikit-learn è una libreria ampiamente utilizzata per l'implementazione di algoritmi di apprendimento automatico. SVM è disponibile anche nella libreria scikit-learn e seguiamo la stessa struttura per usarlo (libreria di importazione, creazione di oggetti, fit e modello di previsione).
Ora, Diamo un'occhiata a una dichiarazione di un problema di vita reale e a un set di dati per capire come applicare SVM per la classificazione.
Dichiarazione problema
Dream Housing Finance si occupa di tutti i prestiti ipotecari. Sono presenti in tutte le aree urbane, semiurbano e rurale. Un cliente prima richiede un mutuo per la casa, dopo che la società ha convalidato l'idoneità del cliente per un prestito.
L'azienda vuole automatizzare il processo di idoneità al prestito (in tempo reale) in base ai dettagli del cliente forniti durante la compilazione di un modulo di domanda online. Questi dettagli sono di genere, stato civile, formazione scolastica, numero di dipendenti, reddito, ammontare del prestito, storia creditizia e altro. Per automatizzare questo processo, hanno dato un problema nell'identificare i segmenti di clientela, che hanno diritto all'importo del prestito in modo che possano rivolgersi specificamente a questi clienti. Qui hanno fornito un set di dati parziale.
Utilizzare la finestra di codifica sottostante per prevedere l'idoneità al prestito nel set di prova. Prova a modificare gli iperparametri di Linear SVM per migliorare la precisione.
Supporto del codice macchina vettoriale (SVM) un R
Il pacchetto e1071 in R viene utilizzato per creare facilmente macchine vettoriali di supporto. Ha funzioni ausiliarie, così come il codice per il classificatore Naive Bayes. La creazione di una macchina vettoriale di supporto in R e Python segue approcci simili, diamo ora un'occhiata al seguente codice:
#Import Library require(e1071 ·) #Contains the SVM Train <- leggi.csv(file.scegli()) Test <- leggi.csv(file.scegli()) # Ci sono varie opzioni associate alla formazione SVM; come cambiare il kernel, gamma e valore C. # create model model <- svm(Target~Predictor1+Predictor2+Predictor3,data=Train,kernel="lineare",gamma=0.2,costo=100) #Predict Output preds <- prevedere(modello,Test) tavolo(pred)
Come regolare i parametri SVM?
La regolazione dei valori dei parametri per gli algoritmi di machine learning migliora efficacemente le prestazioni del modello. Vediamo l'elenco dei parametri disponibili con SVM.
sklearn.svm.SVC(C=1,0, kernel="rbf", grado=3, gamma=0,0, coef0=0,0, restringimento=True, probabilità=Falso,tol=0,001, cache_size=200, class_weight=Nessuno, verbose=Falso, max_iter=-1, random_state=Nessuno)
Discuterò alcuni parametri importanti che hanno un impatto maggiore sulle prestazioni del modello, “kernel”, “gamma” e “C”.
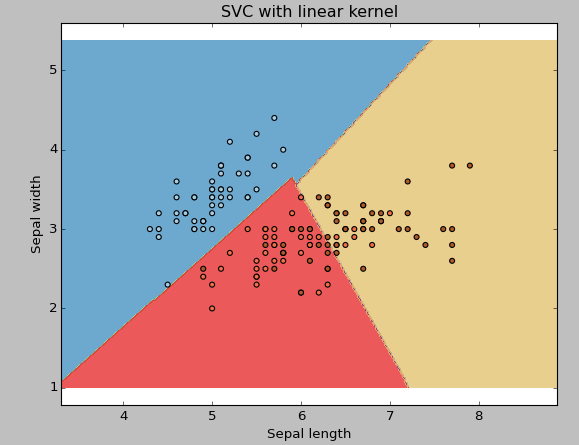
nucleo: Ne abbiamo già discusso. Qui, abbiamo diverse opzioni disponibili con il kernel come, “lineare”, “rbf”, “Poli” e altri (Il valore predefinito è “rbf”). Qui “rbf” e “Poli” sono utili per gli iperpiani non lineari. Vediamo l'esempio, dove abbiamo usato il kernel lineare in due funzionalità del dataset iris per classificarne la classe.
Supporta il codice macchina vettoriale (SVM) e Python
Esempio: Avere un kernel SVM lineare
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, set di dati
# import some data to play with iris = datasets.load_iris() X = iris.data[:, :2] # prendiamo solo le prime due caratteristiche. Potremmo # avoid this ugly slicing by using a two-dim dataset y = iris.target
# creiamo un'istanza di SVM e adattiamo i dati. Non scaliamo il nostro # data since we want to plot the support vectors C = 1.0 # SVM regularization parameter svc = svm.SVC(kernel="lineare", C=1,gamma=0).in forma(X, e)
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
Xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.sottotrama(1, 1, 1) Z = svc.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.forma) plt.contourf(Xx, Aa, INSIEME A, cmap=plt.cm.Accoppiato, alfa=0,8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Accoppiato)
plt.xlabel('Lunghezza sepale')
plt.ylabel('Larghezza sepale')
plt.xlim(xx.min(), xx.max())
plt.titolo('SVC con kernel lineare')
plt.mostra()
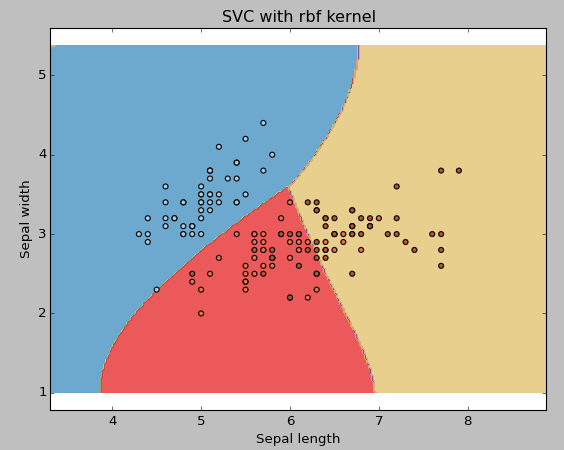
Esempio: Utilice el kernel SVM rbf
Cambie el tipo de kernel a rbf en la línea de abajo y observe el impacto.
svc = svm. SVC(kernel="rbf", C=1,gamma=0).in forma(X, e)
Le sugiero que opte por el kernel SVM lineal si tiene una gran cantidad de características (> 1000) perché è più probabile che i dati siano separabili linearmente in uno spazio ad alta dimensione. Cosa c'è di più, puoi usare RBF, ma non dimenticare di convalidare in modo incrociato i tuoi parametri per evitare l'over-tuning.
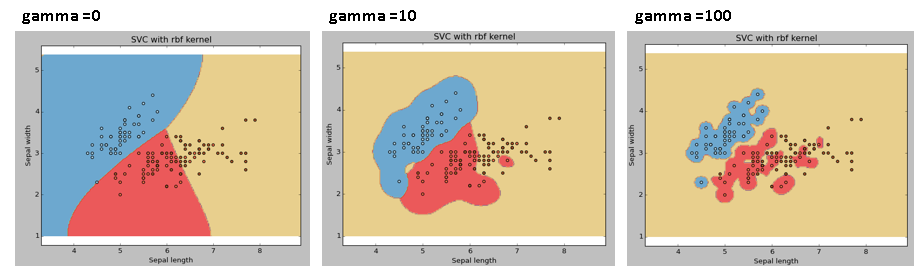
gamma: Coefficiente del kernel per 'rbf', 'Poli'’ e "sigmoide". Più alto è il valore gamma, se intentará ajustar con exactitud el conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., vale a dire, l'errore di generalizzazione e causerà un problema di sovradattamento.
Esempio: Differenziamo se abbiamo valori gamma diversi come 0, 10 oh 100.
svc = svm. SVC(kernel="rbf", C=1,gamma=0).in forma(X, e)
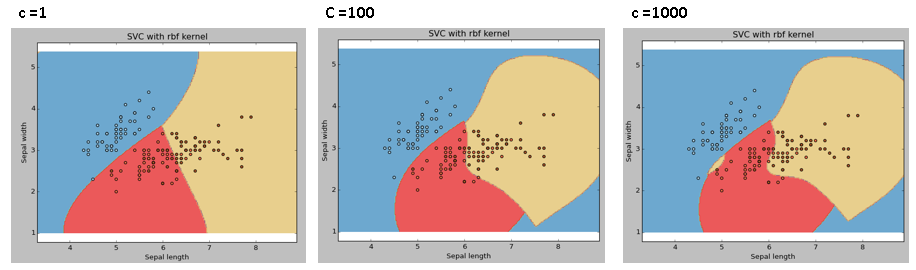
C: Parametro di penalità C del termine di errore. Controlla anche il compromesso tra limiti decisionali soft e corretta classificazione dei punti di allenamento..
Dovremmo sempre guardare al punteggio della convalida incrociata per avere una combinazione efficace di questi parametri ed evitare l'overfitting.
un R, Le SVM possono essere regolate in modo simile a come sono in Python. Di seguito sono indicati i rispettivi parametri per il pacchetto e1071.:
- Il parametro del kernel può essere regolato per prendere “Lineare”, “Poli”, “rbf”, eccetera.
- Il valore gamma può essere regolato impostando il parametro “Gamma”.
- Il valore C in Python è impostato dal parametro “Costo” un R.
Pro e contro associati a SVM
- Professionisti:
- Funziona alla grande con un vuoto chiaro.
- È efficace in ampi spazi.
- È efficace nei casi in cui il numero di dimensioni è maggiore del numero di campioni.
- Utilizzare un sottoinsieme di punti di addestramento nella funzione di decisione (chiamati vettori di supporto), quindi è anche efficiente in termini di memoria.
- Contro:
- Non funziona bene quando abbiamo un grande set di dati perché il tempo di formazione richiesto è più lungo
- Inoltre, non funziona molto bene quando il set di dati ha più rumore, vale a dire, le classi target si sovrappongono
- SVM non fornisce direttamente stime di probabilità, questi sono calcolati utilizzando una costosa convalida incrociata di cinque volte. È incluso nel relativo metodo SVC della libreria scikit-learn di Python.
problema di pratica
Trova la funzione aggiuntiva adatta per avere un iperpiano per segregare le classi nella seguente istantanea:
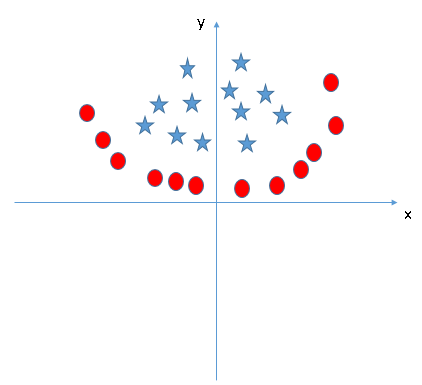
Responda el nombre de la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... en la sección de comentarios a continuación. Poi rivelerò la risposta.
Note finali
In questo articolo, analizziamo in dettaglio l'algoritmo di machine learning, Supporta la macchina vettoriale. Ho parlato del suo concetto di lavoro, il processo di implementazione in Python, i trucchi per rendere efficiente il modello regolandone i parametri, Pro e contro, e finalmente un problema da risolvere. Ti suggerisco di utilizzare SVM e analizzare la potenza di questo modello regolando i parametri. Voglio anche conoscere la tua esperienza con SVM, Come hai regolato i parametri per evitare una regolazione eccessiva e ridurre il tempo di allenamento??
Trovi utile questo articolo? Condividi le tue opinioni / pensieri nella sezione commenti qui sotto.





