introduzione
“¿Cuál es la diferencia entre el apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... e il Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso...?”
Questa è una domanda fin troppo comune tra i principianti e i principianti dell'apprendimento automatico. La risposta a questo sta alla base della comprensione dell'essenza degli algoritmi di apprendimento automatico.. Senza una chiara distinzione tra questo apprendimento supervisionato e l'apprendimento non supervisionato, il tuo viaggio non può progredire.
In realtà, questa è una delle prime cose che dovresti imparare quando intraprendi il tuo viaggio di apprendimento automatico. Non possiamo semplicemente saltare alla fase di costruzione del modello se non capiamo dove sono algoritmi come la regressione lineare., regressione logistica, il raggruppamento, reti neurali, eccetera.
Se non sappiamo qual è l'obiettivo dell'algoritmo di apprendimento automatico, falliremo nel nostro sforzo di costruire un modello accurato. È qui che entra in gioco l'idea dell'apprendimento supervisionato e dell'apprendimento non supervisionato..
In questo articolo, Discuterò questi due concetti usando esempi e risponderò anche alla grande domanda: Come decidere quando utilizzare l'apprendimento supervisionato o l'apprendimento non supervisionato??
Se preferisci imparare in formato video, il seguente video spiega 10 algoritmi di apprendimento automatico in un modo molto facile da capire:
Di seguito ho menzionato alcune ottime risorse che sono ottime per fare riferimento a un principiante dell'apprendimento automatico.:
Iniziamo dando un'occhiata all'apprendimento supervisionato.
Cos'è l'apprendimento supervisionato??
Nell'apprendimento supervisionato, il computer si insegna con l'esempio. Impara dai dati passati e applica l'apprendimento ai dati attuali per prevedere eventi futuri. In questo caso, sia i dati di input che quelli di output desiderati aiutano a prevedere eventi futuri.
Per ottenere previsioni accurate, i dati di input sono contrassegnati o contrassegnati come la risposta corretta.

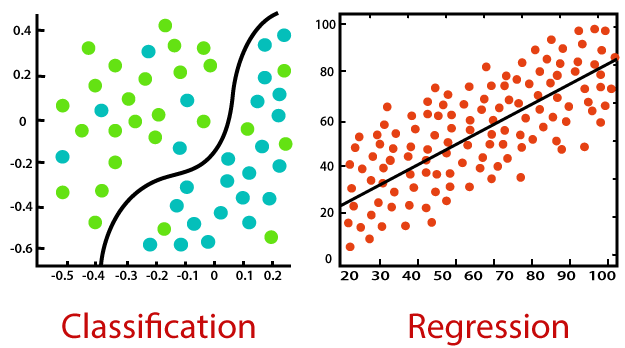
Classificazione supervisionata dell'apprendimento automatico
È importante ricordare che tutti gli algoritmi di apprendimento supervisionato sono essenzialmente algoritmi complessi., classificati come modelli di classificazione o regressione.
1) Modelli di classificazione – Los modelos de clasificación se utilizan para problemas en los que la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de salida se puede categorizar, Che cosa “sì” oh “No”, oh “Passaggio” oh “non passa”. I modelli di classificazione vengono utilizzati per prevedere la categoria dei dati. Esempi di vita reale includono il rilevamento dello spam, analisi delle opinioni, previsione dell'esame con schede di punteggio, eccetera.
2) Modelli di regressione – I modelli di regressione vengono utilizzati per problemi in cui la variabile di output è un valore reale, come numero unico, dollari, stipendio, peso o pressione, ad esempio. Più spesso utilizzato per prevedere valori numerici in base a precedenti osservazioni di dati. Alcuni degli algoritmi di regressione più familiari includono la regressione lineare, Regressione logistica, regressione polinomiale e regressione ridge.
Ci sono alcune applicazioni molto pratiche degli algoritmi di apprendimento supervisionato nella vita reale, Compreso:
- Classificazione del testo
- Riconoscimento facciale
- Riconoscimento della firma
- Scoperta del cliente
- Rilevamento spam
- Previsione del tempo
- Prevedi i prezzi delle case in base al prezzo di mercato prevalente
- Previsioni sul prezzo delle azioni, tra gli altri
Cos'è l'apprendimento non supervisionato??
Apprendimento non supervisionato, In secondo luogo, è il metodo che addestra le macchine a utilizzare dati non classificati o etichettati. Significa que no se pueden proporcionar datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y la máquina está hecha para aprender por sí misma. La macchina deve essere in grado di classificare i dati senza alcuna informazione preventiva sui dati.
L'idea è quella di esporre le macchine a grandi volumi di dati variabili e consentire loro di apprendere da tali dati per fornire informazioni precedentemente sconosciute e identificare schemi nascosti.. Come tale, nessun risultato necessariamente definito di algoritmi di apprendimento non supervisionato. Piuttosto, determina cosa è diverso o interessante dal set di dati dato.
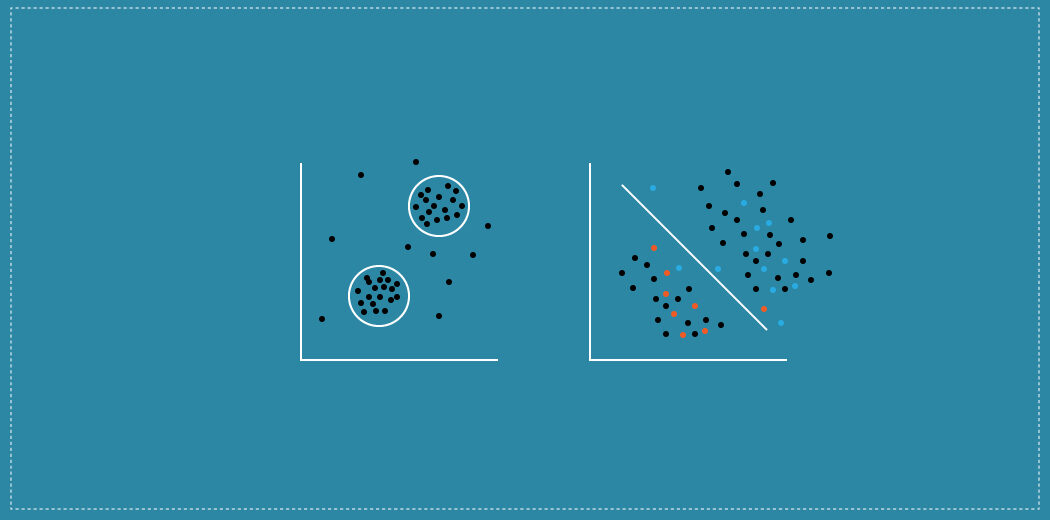
La macchina deve essere programmata per l'autoapprendimento. Il computer deve comprendere e fornire informazioni da dati strutturati e non strutturati. Ecco un'illustrazione accurata dell'apprendimento non supervisionato:

Categorizzazione dell'apprendimento automatico senza supervisione
1) Raggruppamento è uno dei metodi di apprendimento non supervisionato più comuni. Il metodo di raggruppamento prevede l'organizzazione dei dati senza etichetta in gruppi simili chiamati cluster.. Perciò, un gruppo è una raccolta di elementi di dati simili. L'obiettivo principale qui è trovare somiglianze nei punti dati e raggruppare punti dati simili in un gruppo.
2) Rilevamento anomalie è il metodo per identificare gli elementi rari, eventi o osservazioni che differiscono significativamente dalla maggior parte dei dati. Generalmente, cerchiamo anomalie o outlier nei dati perché sospetti. Il rilevamento delle anomalie viene spesso utilizzato nel rilevamento di frodi bancarie ed errori medici.
Applicazioni di algoritmi di apprendimento senza supervisione
Alcune applicazioni pratiche degli algoritmi di apprendimento non supervisionato includono:
- Intercettazione di una frode
- Rilevamento malware
- Identificazione degli errori umani durante l'inserimento dei dati
- Esecuzione di un'analisi accurata del carrello, eccetera.
Quando dovresti scegliere l'apprendimento supervisionato rispetto all'apprendimento non supervisionato??
Nella produzione, un gran numero di fattori influenzano quale approccio di apprendimento automatico è il migliore per un determinato compito. E, poiché ogni problema di apprendimento automatico è diverso, decidere quale tecnica utilizzare è un processo complesso.
Generalmente, una buona strategia per affinare il corretto approccio di apprendimento automatico è:
- Valuta i dati. È etichettato? / Senza etichetta? Sono disponibili conoscenze specialistiche per supportare l'etichettatura aggiuntiva?? Ciò contribuirà a determinare se è necessario utilizzare un approccio di apprendimento supervisionato., non supervisionato, semi-sorvegliato o rinforzato.
- Definire l'obiettivo. Il problema è ricorrente?, definito? O ci si aspetta che l'algoritmo preveda nuovi problemi??
- Rivedere gli algoritmi disponibili che può adattarsi al problema della dimensionalità (numero di funzioni, attributi o caratteristiche). Gli algoritmi candidati devono essere adattati al volume complessivo dei dati e alla sua struttura.
- Studia le applicazioni di successo del tipo algoritmo in problemi simili
Note finali
L'apprendimento supervisionato e l'apprendimento non supervisionato sono concetti chiave nel campo dell'apprendimento automatico. Una corretta comprensione delle basi è molto importante prima di saltare nel gruppo di diversi algoritmi di apprendimento automatico..
Come prossimo passo, vai avanti e dai un'occhiata al seguente articolo che copre i migliori e popolari algoritmi di apprendimento automatico:





