Una semplice analogia per spiegare l'albero decisionale rispetto alla foresta casuale
Iniziamo con un esperimento mentale che illustrerà la differenza tra un albero decisionale e un modello di foresta casuale..
Supponiamo che una banca debba approvare un piccolo importo di prestito per un cliente e che la banca debba prendere rapidamente una decisione.. La banca controlla la storia creditizia e la situazione finanziaria della persona e scopre che non ha ancora rimborsato il prestito precedente. Perciò, La banca respinge la richiesta.
Ma ecco il problema: L'importo del prestito era troppo piccolo per le enormi casse della banca e avrebbero potuto facilmente approvarlo in una misura a basso rischio.. Perciò, La banca ha perso l'opportunità di guadagnare un po' di soldi.
Ora, Un'altra richiesta di prestito arriverà entro pochi giorni, Ma questa volta la banca presenta una strategia diversa: Molteplici processi decisionali. Qualche volta, prima controlla la tua storia creditizia e, A volte, Per prima cosa controlla le condizioni finanziarie del cliente e l'importo del prestito. Dopo, La banca combina i risultati di questi molteplici processi decisionali e decide di concedere il prestito al cliente..
Anche se questo processo ha richiesto più tempo del precedente, La banca ha beneficiato di questo metodo. Questo è un classico esempio in cui il processo decisionale collettivo ha superato un singolo processo decisionale.. Ora, Ecco la mia domanda per te: Sapete cosa rappresentano questi due processi??

Questi sono alberi decisionali e una foresta casuale!! Esploreremo questa idea in dettaglio qui., Approfondiremo le principali differenze tra questi due metodi e risponderemo alla domanda chiave: Quale algoritmo di machine learning dovrei usare?
Sommario
- Breve introduzione agli alberi decisionali
- Una panoramica delle foreste casuali
- Scontro casuale nella foresta e albero decisionale (In codice!!)
- Perché Random Forest ha sovraperformato un albero decisionale?
- Albero decisionale vs. foresta casuale: Quando scegliere quale algoritmo?
Breve introduzione agli alberi decisionali
Un albero decisionale è un algoritmo di apprendimento automatico supervisionato che può essere utilizzato per problemi di classificazione e regressione.. Un albero decisionale è semplicemente una serie di decisioni sequenziali che vengono prese per raggiungere un risultato specifico.. Ecco un'illustrazione di un albero decisionale in azione (Usando il nostro esempio sopra):
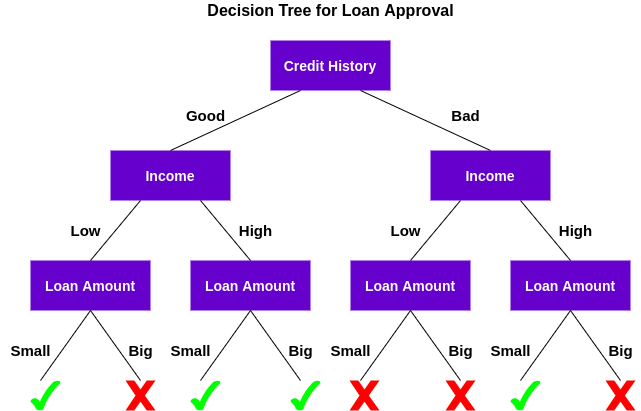
Capiamo come funziona questo albero.
Primo, Controlla se il cliente ha una buona storia creditizia. Sulla base di ciò, Classificare il cliente in due gruppi, vale a dire, clienti con una buona storia creditizia e clienti con una cattiva storia creditizia. Dopo, verifica il reddito del cliente e lo classifica nuovamente in due gruppi. Finalmente, Controlla l'importo del prestito richiesto dal cliente. Secondo i risultati della verifica di queste tre caratteristiche, L'albero decisionale decide se il prestito del cliente deve essere approvato o meno.
Tratti somatici / Gli attributi e le condizioni possono cambiare a seconda dei dati e della complessità del problema, Ma l'idea generale rimane la stessa.. Quindi, Un albero decisionale prende una serie di decisioni basate su un insieme di caratteristiche / Attributi presenti nei dati, che in questo caso erano la storia creditizia, Reddito e importo del prestito.
Ora, ti starai chiedendo:
Perché l'albero decisionale ha controllato prima il punteggio di credito e non il reddito?
Questo è noto come importanza caratteristica e la sequenza di attributi da controllare è decisa sulla base di criteri quali IndiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... dell'impurità di Gini oh Guadagno di informazioni. La spiegazione di questi concetti va oltre lo scopo del nostro articolo qui., Ma puoi controllare una qualsiasi delle risorse qui sotto per imparare tutto sugli alberi decisionali.:
Nota: L'idea alla base di questo articolo è quella di confrontare alberi decisionali e foreste casuali.. Perciò, Non entrerò nei dettagli delle basi, ma fornirò i link pertinenti nel caso in cui tu voglia esplorare di più.
Una panoramica di Random Forest
L'algoritmo dell'albero decisionale è abbastanza facile da capire e interpretare. Ma spesso, Un solo albero non è sufficiente per produrre risultati efficaci. È qui che entra in gioco l'algoritmo Random Forest..

Random Forest è un algoritmo di apprendimento automatico basato su alberi che sfrutta la potenza di più alberi decisionali per prendere decisioni.. Come suggerisce il nome, ¡È un “foresta” di alberi!
Ma, Perché la chiamiamo foresta? “a caso”? Questo perché è una foresta di Alberi decisionali creati casualmente. Ogni nodo nell'albero decisionale lavora su un sottoinsieme casuale di funzionalità per calcolare l'output. La foresta casuale combina quindi l'output dei singoli alberi decisionali per generare l'output finale.
In parole semplici:
L'algoritmo della foresta casuale combina l'output di più alberi decisionali (creato casualmente) Per generare l'output finale.
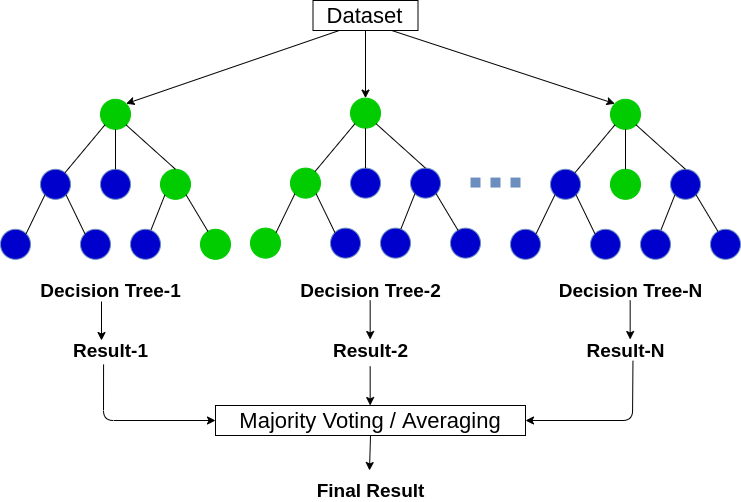
Questo processo di combinazione dell'output di più modelli individuali (Conosciuto anche come studenti deboli) è chiamato Co-apprendimento. Se vuoi saperne di più su come funzionano la foresta casuale e altri algoritmi di apprendimento dei set, Vedere i seguenti articoli:
Ora la domanda è:, Come possiamo decidere quale algoritmo scegliere tra un albero decisionale e una foresta casuale?? Vediamoli entrambi in azione prima di saltare alle conclusioni!!
Scontro casuale nella foresta e albero decisionale (In codice!!)
In questa sezione, useremo Python per risolvere un problema di classificazione binaria usando sia un albero decisionale che una foresta casuale. Quindi confronteremo i tuoi risultati e vedremo quale si adatta meglio al nostro problema..
Lavoreremo sul Set di dati di previsione dei prestiti da DataPeaker Piattaforma DataHack. Questo è un problema di classificazione binaria in cui dobbiamo determinare se una persona debba ricevere un prestito o meno in base a un certo insieme di caratteristiche..
Nota: Puoi andare al Hai mai lottato per migliorare il tuo grado in un hackathon di apprendimento automatico piattaforma e competere con altre persone in varie competizioni di apprendimento automatico online e avere la possibilità di vincere fantastici premi.
Pronto per il codice?
passo 1: Caricare le librerie e il set di dati
Iniziamo importando le librerie Python richieste e il nostro set di dati:

Il set di dati è composto da 614 righe e 13 caratteristiche, compresa la storia creditizia, Stato civile, l'importo del prestito e il sesso. Qui, il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... di destinazione è Stato_prestito, che indica se una persona deve ricevere un prestito o meno.
passo 2: pre-elaborazione dei dati
Ora arriva la parte più cruciale di qualsiasi progetto di data science: DPre-elaborazione ATA e fedeIngegneria naturale. In questa sezione, Mi occuperò delle variabili categoriali nei dati e dell'imputazione anche dei valori mancanti.
Imputerò i valori persi nelle variabili categoriali con la moda, e per variabili continue, con la media (per le rispettive colonne). Cosa c'è di più, Etichetteremo codificando i valori categoriali nei dati. Puoi leggere questo articolo per saperne di più su Codifica etichetta.

passo 3: Creazione di gruppi di test e treni
Ora, Dividiamo il set di dati in un 80:20 Relazione per formazione e test, rispettivamente:
Diamo un'occhiata alla forma del treno creato e ai set di test:

Eccellente! Ora siamo pronti per la fase successiva in cui creeremo l'albero decisionale e i modelli di foresta casuali!!
passo 4: Costruzione e valutazione del modello
Dal momento che abbiamo i set di formazione e test, È tempo di formare i nostri modelli e classificare le richieste di prestito. Primo, Verrà addestrato un albero decisionale su questo set di dati:
Prossimo, valuteremo questo modello utilizzando F1-Score. F1-Score è la media armonica di precisione e recupero data dalla formula:
![]()
Puoi saperne di più su questa e altre metriche di valutazione qui:
Valutiamo le prestazioni del nostro modello utilizzando il punteggio F1:
![]()
![]()
Qui, È possibile vedere che l'albero decisionale funziona bene nella valutazione all'interno del campione, ma le sue prestazioni diminuiscono drasticamente nella valutazione fuori campione. Perché pensi che sia così?? Sfortunatamente, Il nostro modello di albero decisionale è sovraadattato ai dati di addestramento. La foresta casuale risolverà questo problema?
Creazione di un modello di foresta casuale
Vediamo un modello di foresta casuale in azione:
![]()
![]()
Qui, Possiamo vedere chiaramente che il modello di foresta casuale ha funzionato molto meglio dell'albero decisionale nella valutazione fuori campione.. Discutiamo le ragioni alla base di questo nella prossima sezione..
Perché il nostro modello di foresta casuale ha sovraperformato l'albero decisionale?
La foresta casuale sfrutta la potenza di più alberi decisionali. Lo fa. no dipendono dall'importanza della caratteristica data da un singolo albero decisionale. Diamo un'occhiata all'importanza della funzionalità data da diversi algoritmi alle diverse caratteristiche:
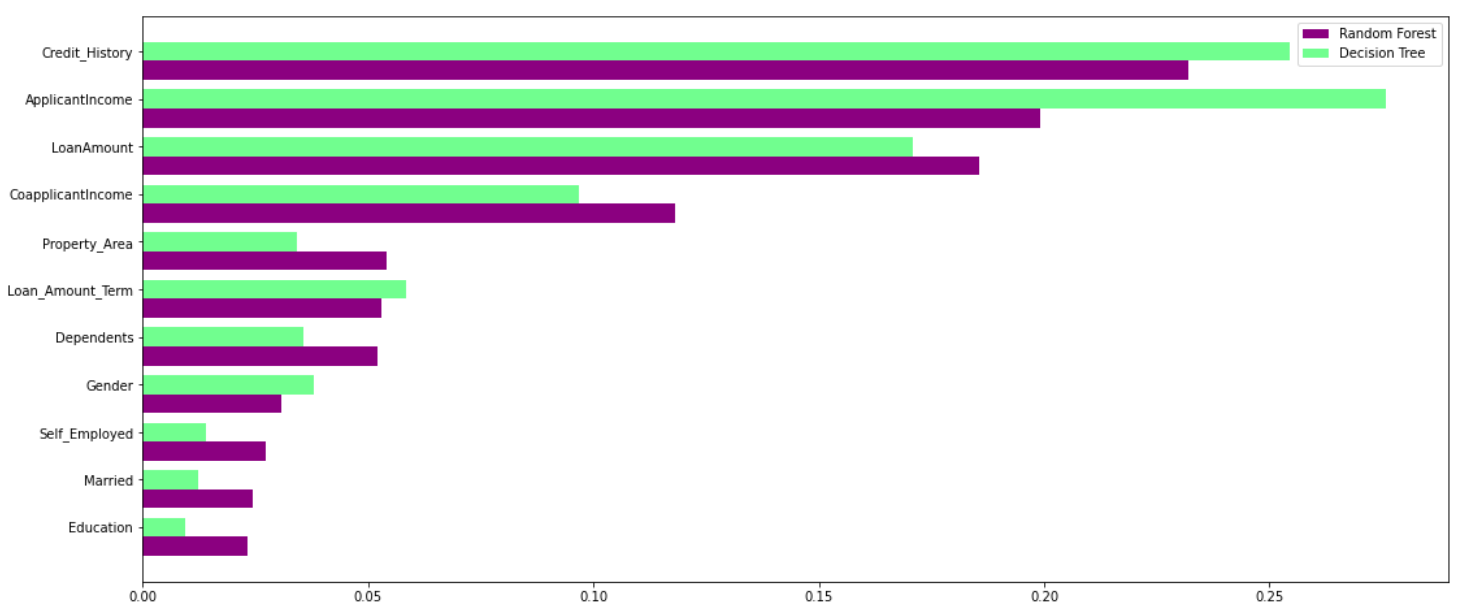
Come puoi vedere chiaramente nel grafico sopra, Il modello dell'albero decisionale attribuisce grande importanza a un particolare insieme di caratteristiche. Ma la foresta casuale sceglie le caratteristiche in modo casuale durante il processo di addestramento.. Perciò, non si basa molto su alcun set specifico di funzionalità. Questa è una caratteristica speciale della foresta casuale sugli alberi insaccati.. Puoi leggere di più sulla borsa.Classificatore ad albero ING qui.
Perciò, La foresta casuale può generalizzare i dati in modo migliore. Questa selezione casuale di feature rende la foresta casuale molto più accurata di un albero decisionale..
Quindi, Quale scegliere?: Albero decisionale o foresta casuale?
Random Forest è adatto per situazioni in cui abbiamo un grande set di dati e l'interpretabilità non è una preoccupazione importante..
Gli alberi decisionali sono molto più facili da interpretare e capire. Poiché una foresta casuale combina diversi alberi decisionali, diventa più difficile da interpretare. Ecco le buone notizie: Non è impossibile interpretare una foresta casuale. Ecco un articolo che parla di Interpretare i risultati di un modello di foresta casuale:
Cosa c'è di più, Random Forest ha un tempo di addestramento più elevato rispetto a un singolo albero decisionale. È necessario tenerlo a mente perché man mano che aumentiamo il numero di alberi in una foresta casuale, Anche il tempo necessario per addestrare ciascuno di loro aumenta. Questo può spesso essere cruciale quando si lavora a scadenze ravvicinate su un progetto di machine learning..
Ma dirò questo: nonostante l'instabilità e la dipendenza da un particolare insieme di caratteristiche, Gli alberi decisionali sono davvero utili perché sono più facili da interpretare e più veloci da addestrare.. Chiunque abbia pochissime conoscenze di data science può anche utilizzare gli alberi decisionali per prendere decisioni rapide e basate sui dati..
Note finali
Questo è essenzialmente ciò che devi sapere nell'albero decisionale rispetto al dibattito sulla foresta casuale.. Può essere complicato quando sei nuovo al machine learning, Ma questo articolo avrebbe dovuto chiarire le differenze e le somiglianze per te..
Puoi contattarmi con le tue domande e pensieri nella sezione commenti qui sotto..





