introduzione
Muchos analistas malinterpretan el término “impulso” utilizado en la ciencia de datos. Permítanme brindarles una explicación interesante de este término. El impulso otorga poder a los modelos de aprendizaje automático para mejorar su precisión de predicción.
Los algoritmos de impulso son uno de los algoritmos más utilizados en las competiciones de ciencia de datos. Los ganadores de nuestro últimos hackatones están de acuerdo en que intentan impulsar el algoritmo para mejorar la precisión de sus modelos.
In questo articolo, explicaré cómo funciona el algoritmo de impulso de una manera muy simple. También he compartido los códigos de Python a continuación. Me he saltado las intimidantes derivaciones matemáticas que se utilizan en Boosting. Porque eso no me habría permitido explicar este concepto en términos simples.
Cominciamo.

¿Qué es impulsar?
Definizione: Il termine “Impulso” se refiere a una familia de algoritmos que convierte a un alumno débil en un alumno fuerte.
Entendamos esta definición en detalle resolviendo un problema de identificación de correo electrónico no deseado:
¿Cómo clasificaría un correo electrónico como SPAM o no? Como todos los demás, nuestro enfoque inicial sería identificar los correos electrónicos “spam” e “niente spam” utilizando los siguientes criterios. e:
- El correo electrónico tiene solo un archivo de imagen (imagen promocional), es un SPAM
- El correo electrónico solo tiene enlace (S), es un SPAM
- El cuerpo del correo electrónico consta de una oración como “Ganaste un premio en metálico de $ xxxxxx”, es un SPAM
- Correo electrónico de nuestro dominio oficial “Analyticsvidhya.com“, No es un SPAM
- Correo electrónico de fuente conocida, no SPAM
In precedenza, hemos definido varias reglas para clasificar un correo electrónico en ‘spam’ o ‘no spam’. Ma, ¿cree que estas reglas individualmente son lo suficientemente fuertes como para clasificar con éxito un correo electrónico? No.
Individualmente, estas reglas no son lo suficientemente poderosas como para clasificar un correo electrónico en ‘spam’ o ‘no spam’. Perciò, estas reglas se denominan studente debole.
Para convertir a un alumno débil en un alumno fuerte, combinaremos la predicción de cada alumno débil utilizando métodos como:
• Usando promedio / media ponderata
• Considerando que la predicción tiene mayor voto
Ad esempio: sopra, hemos definido 5 estudiantes débiles. Di questi 5, 3 se votan como ‘SPAM’ e 2 se votan como ‘No es SPAM’. In questo caso, per impostazione predefinita, consideraremos un correo electrónico como SPAM porque tenemos un voto más alto (3) para ‘SPAM’.
¿Cómo funcionan los algoritmos de impulso?
Ahora sabemos que el impulso combina a un alumno débil, también conocido como alumno básico, para formar una regla sólida. Una pregunta inmediata que debería surgir en tu mente es: ‘¿Cómo impulsar la identificación de reglas débiles?‘
Para encontrar una regla débil, aplicamos algoritmos de aprendizaje base (ML) con una distribución diferente. Cada vez que se aplica el algoritmo de aprendizaje base, genera una nuova regola di previsione debole. Este es un proceso iterativo. Dopo molte iterazioni, el algoritmo de impulso combina estas reglas débiles en una sola regla de predicción fuerte.
Aquí hay otra pregunta que podría atormentarlo ”.¿Cómo elegimos una distribución diferente para cada ronda? ‘
Para elegir la distribución correcta, estos son los siguientes pasos:
passo 1: El alumno básico toma todas las distribuciones y asigna el mismo peso o atención a cada observación.
passo 2: Si hay algún error de predicción causado por el algoritmo de aprendizaje de la primera base, entonces prestamos mayor atención a las observaciones que tienen un error de predicción. Dopo, aplicamos el siguiente algoritmo de aprendizaje base.
passo 3: Ripetere il passaggio 2 hasta que se alcance el límite del algoritmo de aprendizaje base o se logre una mayor precisión.
Finalmente, combina los resultados del alumno débil y crea un alumno fuerte que finalmente mejora el poder de predicción del modelo. El impulso se presta más atención a los ejemplos que están mal clasificados o tienen errores más altos por las reglas débiles anteriores.
Tipos de algoritmos de impulso
El motor subyacente utilizado para impulsar algoritmos puede ser cualquier cosa. Puede ser un sello de decisión, un algoritmo de clasificación que maximiza los márgenes, eccetera. Hay muchos algoritmos de impulso que utilizan otros tipos de motores, Che cosa:
- AdaBoost (Adaptive AumentoSinistro)
- Aumento del árbol de degradado
- XGBoost
In questo articolo, nos centraremos en AdaBoost y Gradient Boosting seguidos de sus respectivos códigos de Python y nos centraremos en XGboost en el próximo artículo.
Aumento dell'algoritmo: AdaBoost
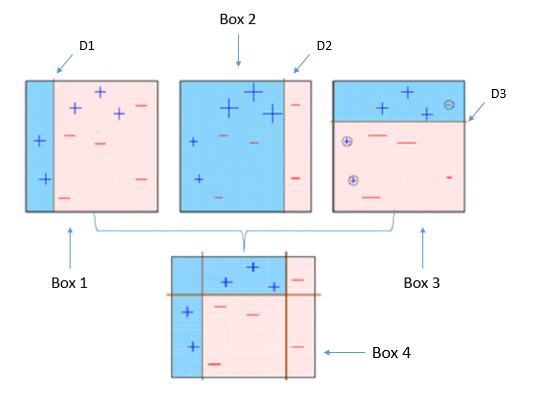
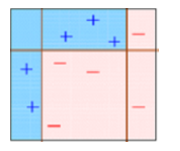
Este diagrama explica acertadamente Ada-boost. Entendamos de cerca:
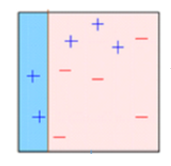
Recuadro 1: Puede ver que hemos asignado pesos iguales a cada punto de datos y aplicado un muñón de decisión para clasificarlos como + (più) oh – (meno). El muñón de decisión (D1) ha generado una línea vertical en el lado izquierdo para clasificar los puntos de datos. Vemos que, esta línea vertical ha predicho incorrectamente tres + (più) Che cosa – (meno). In quel caso, asignaremos pesos más altos a estos tres + (più) y aplicaremos otro muñón de decisión.
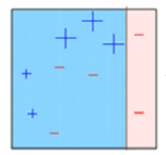
Recuadro 2: Qui, puede ver que el tamaño de tres + (più) predichos incorrectamente es mayor en comparación con el resto de los puntos de datos. In questo caso, el segundo muñón de decisión (re2) intentará predecirlos correctamente. Ora, una línea vertical (re2) en el lado derecho de este cuadro ha clasificado correctamente tres + (più) mal clasificados. ma di nuovo, ha causado errores de clasificación errónea. Esta vez con tres – (meno). Ancora, asignaremos un mayor peso a tres – (meno) y aplicaremos otro muñón de decisión.
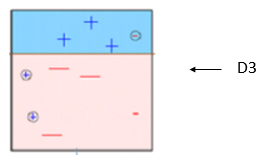
Recuadro 3: Qui, tres – (meno) reciben pesos más altos. Se aplica un muñón de decisión (RE3) para predecir correctamente estas observaciones mal clasificadas. Esta vez se genera una línea horizontal para clasificar + (più) e – (meno) basándose en un mayor peso de observación mal clasificada.
Recuadro 4: Qui, hemos combinado D1, D2 y D3 para formar una predicción fuerte que tiene una regla compleja en comparación con un alumno débil individual. Puede ver que este algoritmo ha clasificado estas observaciones bastante bien en comparación con cualquiera de los estudiantes débiles individuales.
AdaBoost (Adaptive Aumentoing): Funciona con un método similar al descrito anteriormente. Se ajusta a una secuencia de estudiantes débiles en diferentes datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... ponderados. Empieza por predecir el conjunto de datos original y da el mismo peso a cada observación. Si la predicción es incorrecta utilizando el primer alumno, entonces se da mayor peso a las observaciones que se han predicho incorrectamente. Al ser un proceso iterativo, continúa agregando aprendices hasta que se alcanza un límite en el número de modelos o precisión.
Principalmente, usamos sellos de decisión con AdaBoost. Pero podemos usar cualquier algoritmo de aprendizaje automático como aprendiz base si acepta el peso en el conjunto de datos de entrenamiento. Podemos usar algoritmos AdaBoost para problemas de clasificación y regresión.
Puede consultar el artículo “Cómo ser inteligente con el aprendizaje automático: AdaBoost” para comprender los algoritmos de AdaBoost con más detalle.
Codice Python
Ecco una finestra di codifica dal vivo per iniziare. Puoi eseguire i codici e ottenere il risultato in questa finestra:
Puede ajustar los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para optimizar el rendimiento de los algoritmos, he mencionado a continuación los parámetros clave para el ajuste:
- n_estimatori: Controla el número de estudiantes débiles.
- tasso di apprendimento:CControla la contribución de los estudiantes débiles en la combinación final. Hay una compensación entre tasso di apprendimento e n_estimatori.
- estimadores_base: Ayuda a especificar diferentes algoritmos de aprendizaje automático.
También puede ajustar los parámetros de los alumnos básicos para optimizar su rendimiento.
Algoritmo de impulso: aumento del gradiente
En el aumento de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in..., entrena muchos modelos secuencialmente. Cada nuevo modelo minimiza gradualmente la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... (y = ax + B + e, e necesita atención especial ya que es un término de error) de todo el sistema usando Discesa gradiente metodo. El procedimiento de aprendizaje se ajustó consecutivamente a nuevos modelos para proporcionar una estimación más precisa de la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de respuesta.
La idea principal detrás de este algoritmo es construir nuevos alumnos base que puedan correlacionarse al máximo con el gradiente negativo de la función de pérdida, asociado con todo el conjunto. Puede consultar el artículo “Aprenda el algoritmo de aumento de gradiente” para comprender este concepto con un ejemplo.
En la biblioteca Python Sklearn, usamos Gradient Tree Boosting o GBRT. Es una generalización del impulso a funciones de pérdida diferenciables arbitrarias. Se puede utilizar tanto para problemas de regresión como de clasificación.
Codice Python
from sklearn.ensemble import GradientBoostingClassifier #For Classification from sklearn.ensemble import GradientBoostingRegressor #For Regression
clf = GradientBoostingClassifier(n_estimatori=100, tasso_di_apprendimento=1.0, profondità massima=1) clf.in forma(X_treno, y_train)
- n_estimatori: Controla el número de estudiantes débiles.
- tasso di apprendimento:CControla la contribución de los estudiantes débiles en la combinación final. Hay una compensación entre tasso di apprendimento e n_estimatori.
- Profondità massima: profundidad máxima de los estimadores de regresión individuales. La profundidad máxima limita el número de nodos en el árbol. Ajuste este parámetro para obtener el mejor rendimiento; el mejor valor depende de la interacción de las variables de entrada.
Puede ajustar la función de pérdida para un mejor rendimiento.
Nota finale
In questo articolo, analizamos el impulso, uno de los métodos de modelado de conjuntos para mejorar el poder de predicción. Qui, hemos discutido la ciencia detrás del impulso y sus dos tipos: AdaBoost y Gradient Boost. También estudiamos sus respectivos códigos de Python.
Nel mio prossimo articolo, discutiré sobre otro tipo de algoritmos de impulso que ahora es un secreto de días para ganar concursos de ciencia de datos “XGBoost”.
Trovi utile questo articolo? Condividi le tue opinioni / pensieri nella sezione commenti qui sotto.





