Introduzione:
datos no estructurados en un formato estructurado? Aquí es donde entra en escena el Web Scraping.
Cos'è il web scraping??
En lenguaje sencillo, Raspado web, cosecha web, oh extracción de datos web es un proceso automatizado de recopilación de datos grandes (non strutturato) de sitios web. El usuario puede extraer todos los datos en sitios particulares o los datos específicos según el requisito. Los datos recopilados se pueden almacenar en un formato estructurado para su posterior análisis.
Usos del web scraping:
Nel mondo reale, el web scraping ha ganado mucha atención y tiene una amplia gama de usos. Alcuni di loro sono elencati di seguito:
- Análisis del sentimiento de las redes sociales
- Generación de leads en el dominio de marketing
- Analisi di mercato, comparación de precios en línea en el dominio de comercio electrónico
- Recopile datos de entrenamiento y prueba en aplicaciones de aprendizaje automático
Pasos involucrados en el web scraping:
- Busque la URL de la página web que desea raspar
- Seleccione los elementos particulares inspeccionando
- Escribe el código para obtener el contenido de los elementos seleccionados
- Almacene los datos en el formato requerido
¡¡Así de simples chicos .. !!
Las bibliotecas / herramientas populares que se utilizan para el web scraping son:
- Selenio: un marco para probar aplicaciones web
- bellazuppa: biblioteca de Python para obtener datos de HTML, XML y otros lenguajes de marcado
- panda: biblioteca de Python para manipulación y análisis de datos
In questo articolo, crearemos nuestro propio conjunto de datos extrayendo reseñas de Domino’s Pizza del sitio web. consumeraffairs.com/food.
Noi useremo richieste e Bella zuppa di raspado y análisis i dati.
passo 1: busque la URL de la página web que desea raspar
Abra la URL “consumeraffairs.com/food”Y busque Domino’s Pizza en la barra de búsqueda y presione Enter.
A continuación se muestra cómo se ve nuestra página de reseñas.
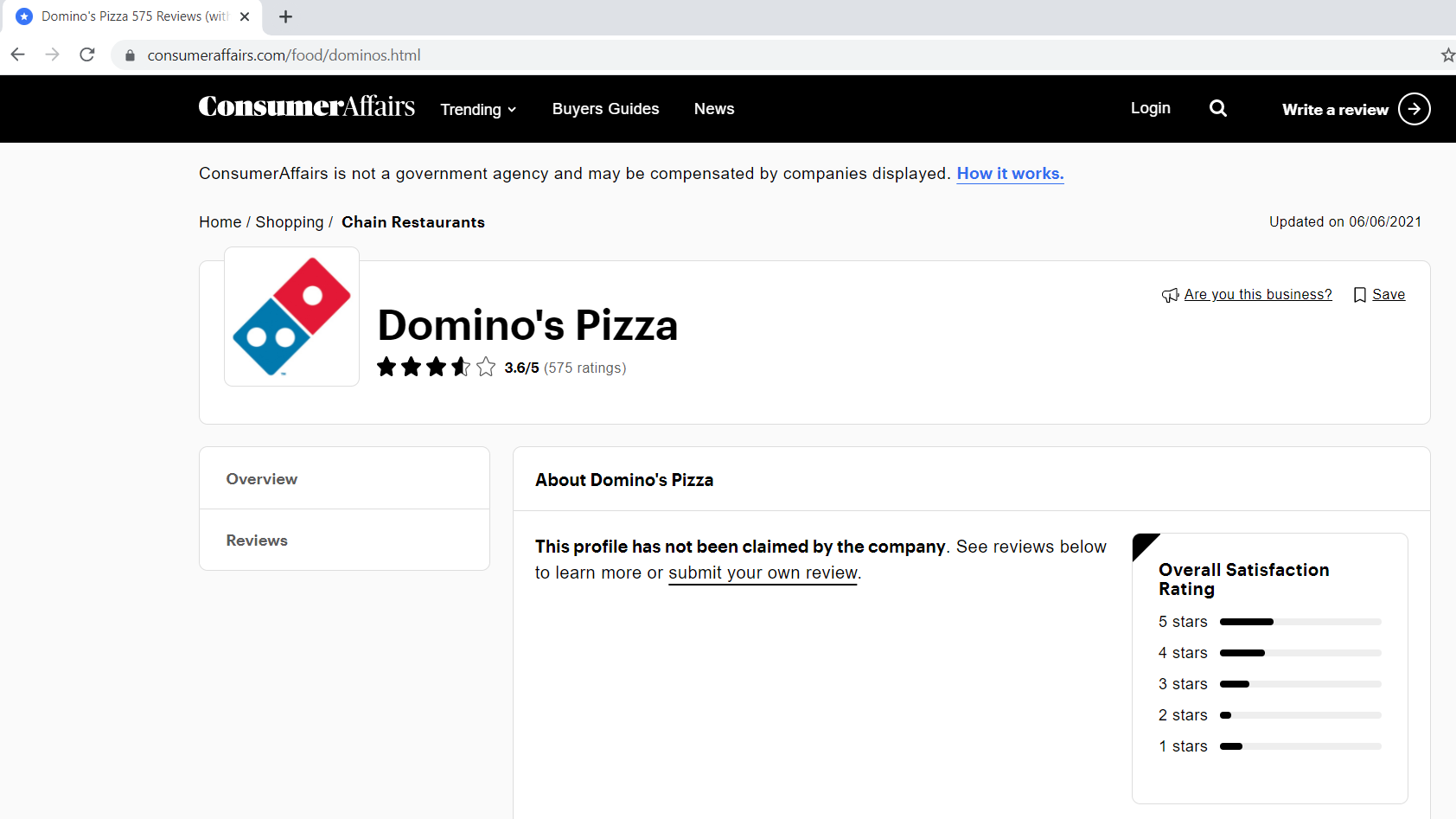
passo 1.1: Definición de la URL base, parámetros de consulta
La URL base es la parte coherente de su dirección web y representa la ruta a la función de búsqueda del sitio web.
base_url = "https://www.consumeraffairs.com/food/dominos.html?pagina="
Los parámetros de consulta representan valores adicionales que se pueden declarar en la página.
query_parameter = "?pagina="+str(io) # i represents the page number
passo 2: seleccione los elementos particulares inspeccionando
A continuación se muestra una imagen de una revisión de muestra. Cada reseña tiene muchos elementos: la calificación otorgada por el usuario, il nome utente, la fecha de la reseña y el texto de la reseña junto con alguna información sobre cuántas personas le gustó.

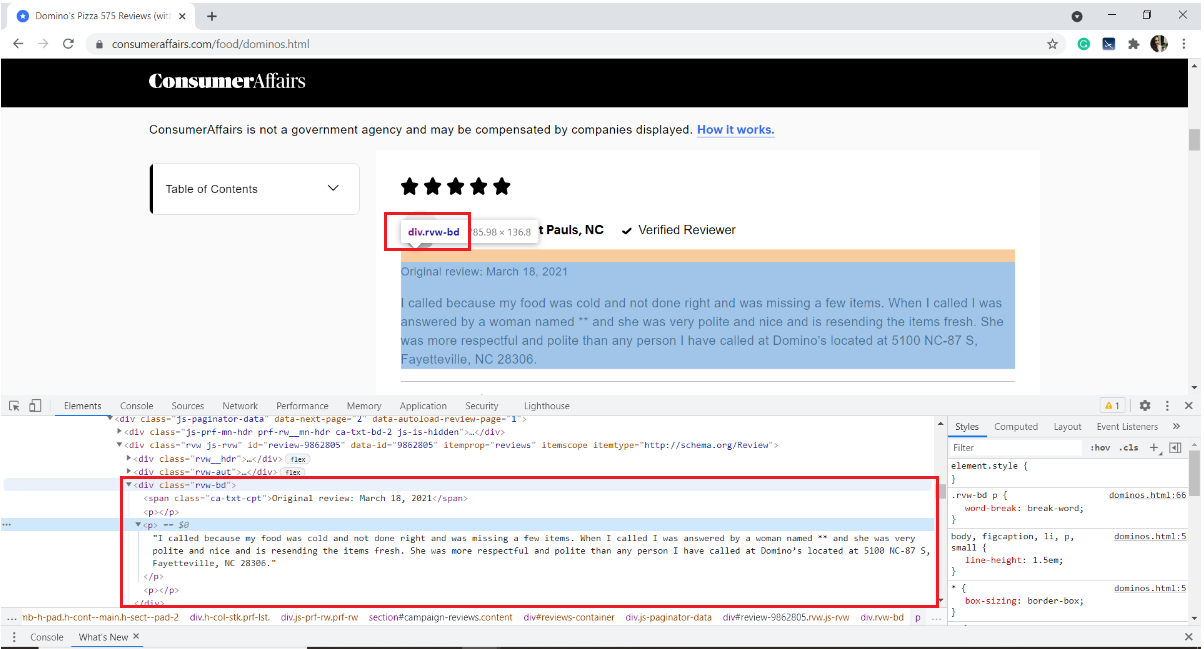
Nuestro interés es extraer solo el texto de la reseña. Per quello, necesitamos inspeccionar la página y obtener las etiquetas HTML, los nombres de los atributos del elemento de destino.
Para inspeccionar una página web, haga clic con el botón derecho en la página, seleccione Inspeccionar o use el atajo de teclado Ctrl + Spostare + io.
Nel nostro caso, el texto de revisión se almacena en la etiqueta HTML
del div con el nombre de clase “rvw-bd“
Con questo, nos familiarizamos con la página web. Saltemos rápidamente al raspado.
passo 3: Escribe el código para obtener el contenido de los elementos seleccionados
Comience instalando los módulos / paquetes necesarios
pip install pandas requests BeautifulSoup4
Importa le librerie richieste
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
panda – para crear un marco de datos
solicitudes: para enviar solicitudes HTTP y acceder al contenido HTML desde la página web de destino
bellazuppa: es una biblioteca de Python para analizar datos HTML estructurados
Cree una lista vacía para almacenar todas las reseñas extraídas
all_pages_reviews = []
definir una función de raspador
def scraper():
Dentro de la función de raspador, escriba un para que el bucle recorra el número de páginas que le gustaría raspar. Me gustaría raspar las reseñas de cinco páginas.
per io nel raggio d'azione(1,6):
Creando una lista vacía para almacenar las reseñas de cada página (a partire dal 1 un 5)
pagewise_reviews = []
Construye la URL
url = base_url + query_parameter
Envíe la solicitud HTTP a la URL mediante solicitudes y almacene la respuesta
risposta = request.get(URL)
Cree un objeto de sopa y analice la página HTML
soup = bs(response.content, 'html.parser')
Encuentre todos los elementos div del nombre de clase “rvw-bd” y guárdelos en una variable
rev_div = soup.findAll("div",attrs={"classe","rvw-bd"})
Recorra todo el rev_div y agregue el texto de revisión a la lista pagewise
per j nell'intervallo(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].trova("P").testo)
Anexar todas las reseñas de páginas a una sola lista “all_pages about”
per k nell'intervallo(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[K])
Al final de la función, devuelve la lista final de reseñas.
return all_pages_reviews
Call the function scraper() and store the output to a variable 'reviews'
# Driver code
reviews = scraper()
passo 4: almacene los datos en el formato requerido
4.1 almacenamiento en un marco de datos de pandas
i = range(1, len(recensioni)+1) reviews_df = pd.DataFrame({'recensione':recensioni}, index=i)
Now let us take a glance of our dataset
Stampa(reviews_df)

4.2 Escribir el contenido del marco de datos en un archivo de texto
reviews_df.to_csv('recensioni.txt', settembre = 't')
Con questo, terminamos de extraer las reseñas y almacenarlas en un archivo de texto. Mmm, es bastante simple, no?
Código Python completo:
# !pip install pandas requests BeautifulSoup4 import pandas as pd import requests from bs4 import BeautifulSoup as bs base_url = "https://www.consumeraffairs.com/food/dominos.html" all_pages_reviews =[]
-
def scraper(): per io nel raggio d'azione(1,6): # fetching reviews from five pages pagewise_reviews = [] query_parameter = "?pagina="+str(io) url = base_url + query_parameter response = requests.get(URL) soup = bs(response.content, 'html.parser') rev_div = soup.findAll("div",attrs={"classe","rvw-bd"}) per j nell'intervallo(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].trova("P").testo) per k nell'intervallo(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[K]) return all_pages_reviews # Driver code reviews = scraper() i = range(1, len(recensioni)+1) reviews_df = pd.DataFrame({'recensione':recensioni}, index=i) reviews_df.to_csv('recensioni.txt', settembre = 't')
Note finali:
Alla fine di questo articolo, hemos aprendido el proceso paso a paso de extraer contenido de cualquier página web y almacenarlo en un archivo de texto.
- inspeccionar el elemento de destino utilizando las herramientas de desarrollo del navegador
- utilizar solicitudes para descargar el contenido HTML
- analizar el contenido HTML usando BeautifulSoup para extraer los datos requeridos
Podemos desarrollar más este ejemplo raspando nombres de usuario, revisando texto. Realice una vectorización en el texto de revisión limpio y agrupe a los usuarios de acuerdo con las revisiones escritas. Podemos usar Word2Vec o CounterVectorizer para convertir texto en vectores y aplicar cualquiera de los algoritmos de agrupamiento de Machine Learning.
Riferimenti:
Biblioteca BeautifulSoup: Documentazione, Tutorial en video
Enlace de repositorio de GitHub para descargar el código fuente
Espero que este blog ayude a comprender el web scraping en Python usando la biblioteca BeautifulSoup. Buon apprendimento !! ?
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





