Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
1. obbiettivo
El objetivo de este artículo es predecir los precios de los vuelos dados los distintos parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto..... I dati utilizzati in questo articolo sono disponibili pubblicamente su Kaggle. Este será un problema de regresión ya que la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... objetivo o dependiente es el precio (valore numerico continuo).
2. introduzione
Le compagnie aeree utilizzano algoritmi complessi per calcolare i prezzi dei voli date le varie condizioni presenti in quel particolare momento.. Questi metodi tengono conto di fattori finanziari, marketing e social per prevedere i prezzi dei voli.
Oggi, il numero di persone che utilizzano i voli è aumentato in modo significativo. È difficile per le compagnie aeree mantenere i prezzi, poiché i prezzi cambiano dinamicamente a causa di condizioni diverse. Ecco perché proveremo a utilizzare l'apprendimento automatico per risolvere questo problema.. Questo può aiutare le compagnie aeree prevedendo quali prezzi possono mantenere. Può anche aiutare i clienti a prevedere i prezzi dei voli futuri e a pianificare il viaggio di conseguenza..
3. Dati utilizzati
Sono stati utilizzati i dati di Kaggle, che è una piattaforma di accesso gratuito per i data scientist e gli appassionati di machine learning.
Fonte: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
Stiamo utilizzando jupyter-notebook per eseguire l'attività di previsione del prezzo del volo.
4. Analisi dei dati
La procedura di estrazione delle informazioni da dati grezzi è chiamata analisi dei dati. Qui useremo eda modulo preparazione dei dati biblioteca para hacer este paso.
from dataprep.eda import create_report import pandas as pd dataframe = pd.read_excel("../output/Data_Train.xlsx") create_report(dataframe)
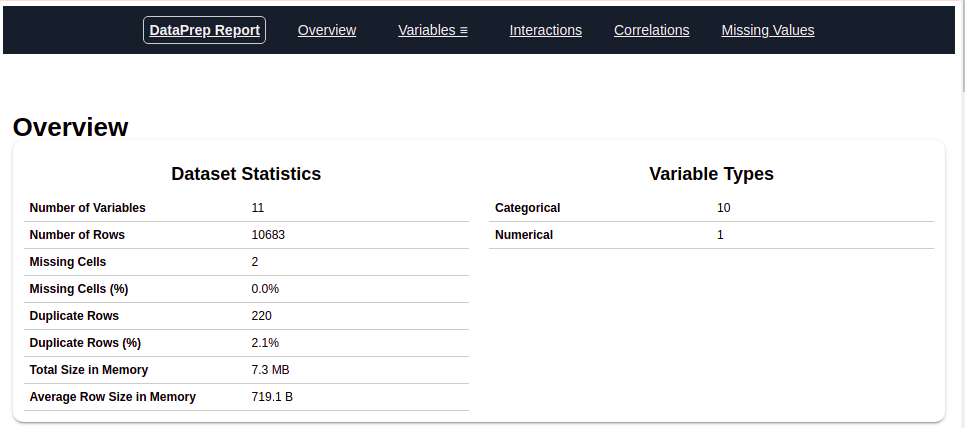
Dopo aver eseguito il codice sopra, obtendrá un informe como se muestra en la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore. Este informe contiene varias secciones o pestañas. La sección ‘Descripción general’ de este informe nos proporciona toda la información básica de los datos que estamos utilizando. Para los datos actuales que estamos usando, obtuvimos la siguiente información:
Número de variables = 11
Número de filas = 10683
Número de tipo categórico de característica = 10
Número de tipo numérico de característica = 1
Filas nuplicadas = 220, eccetera.
Exploremos otras secciones del informe una por una.
4.1 Variabili
Después de seleccionar la sección de variables, otterrai informazioni come mostrato nelle figure seguenti.
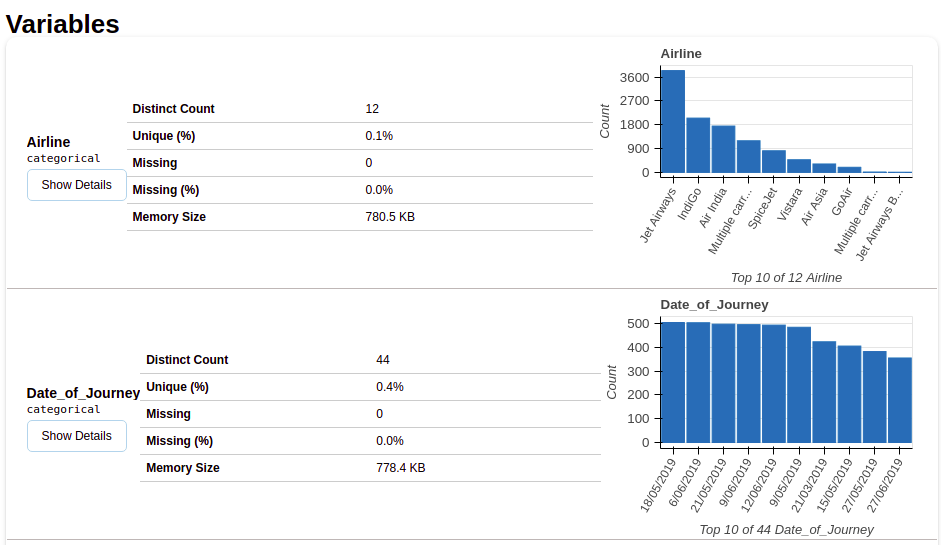
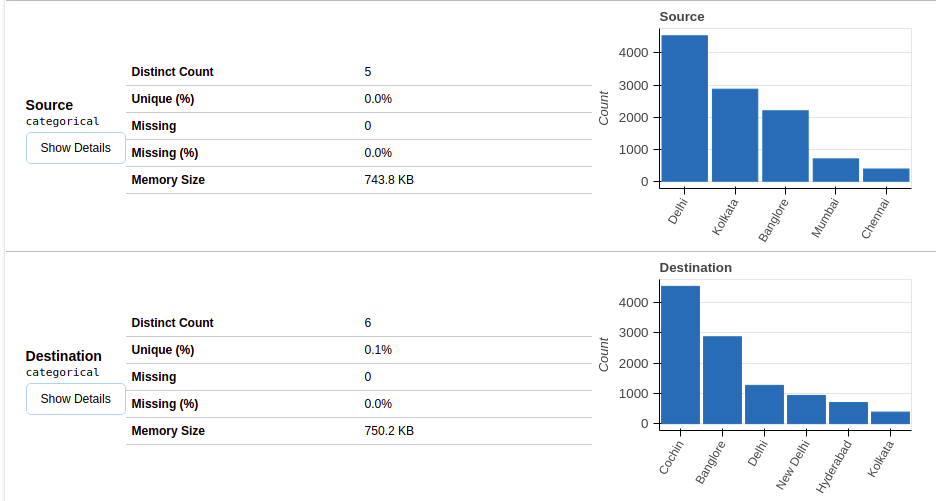
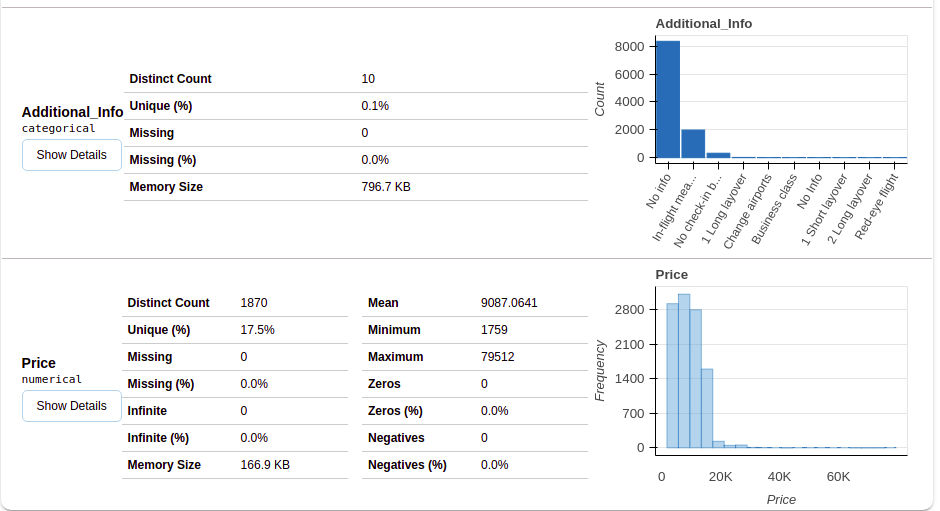
Questa sezione fornisce il tipo di ciascuna variabile insieme a una descrizione dettagliata della variabile..
4.2 Valori mancanti
Questa sezione ha diversi modi in cui possiamo analizzare i valori mancanti nelle variabili. Discuteremo i tre metodi più utilizzati, grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia...., espectro y mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate..... Esploriamoli uno per uno.
4.2.1 Grafico a barre
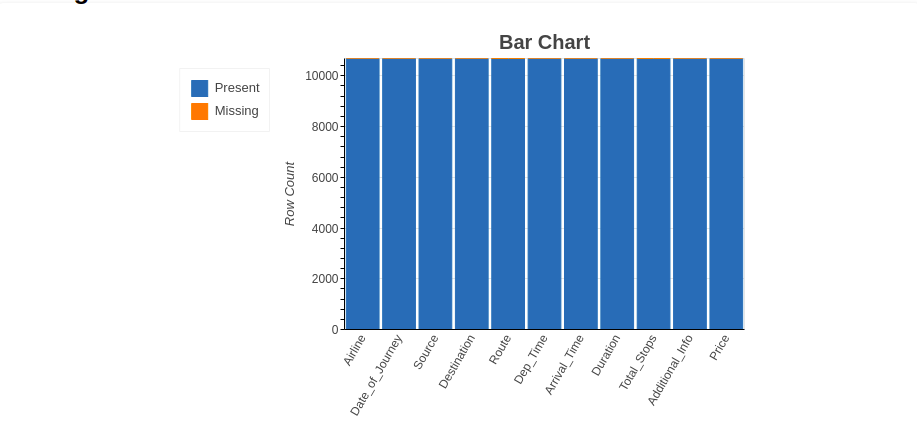
Il metodo del grafico a barre mostra il "numero di valori mancanti e presenti"’ in ogni variabile in un colore diverso.
4.2.2 Spettro
Il metodo dello spettro mostra la percentuale di valori mancanti in ciascuna variabile.
4.2.3 Mappa di calore
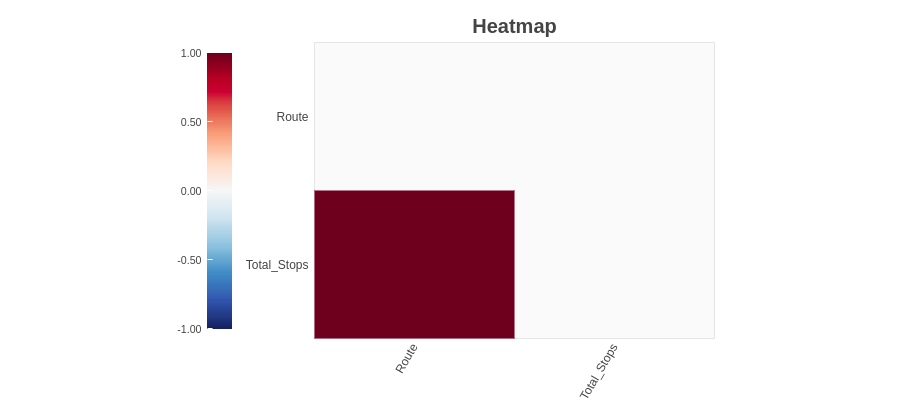
Il metodo della mappa termica mostra le variabili che hanno valori mancanti in termini di correlazione. Da "Rotta"’ e "Total_Paradas"’ sono altamente correlati, entrambi hanno valori mancanti.
Come possiamo osservare, le "Variabili di percorso"’ e "Total_Paradas"’ hanno valori mancanti. Dal momento che non abbiamo trovato alcuna informazione sui valori mancanti dal metodo del grafico a barre dello spettro, ma troviamo variabili di valore mancanti usando il metodo della mappa di calore. Combinando queste informazioni, possiamo dire che le variabili ‘Path’ e "Total_Paradas"’ hanno valori mancanti ma sono molto bassi.
5. Preparazione dei dati
Prima di iniziare la preparazione dei dati, diamo prima un'occhiata ai dati.
dataframe.head()

Come abbiamo visto in Analisi dei dati, ci sono 11 variabili nei dati forniti. Di seguito è riportata la descrizione di ciascuna variabile.
compagnia aerea: Nome della compagnia aerea utilizzata per viaggiare
Data_del_viaggio: Data in cui una persona ha viaggiato
Fonte: Luogo di partenza del volo
Destino: Luogo di fine del volo
Rotta: Contiene informazioni sulla località di partenza e di arrivo del viaggio nel formato standard utilizzato dalle compagnie aeree.
Dept_Time: Orario di partenza del volo dal punto di partenza
Registrare: Orario di arrivo del volo a destinazione
Durata: Durata del volo in ore / minuti
Total_Stops: Numero totale di scali effettuati dal volo prima di atterrare a destinazione.
Informazioni aggiuntive: Mostra eventuali informazioni aggiuntive su un volo
Prezzo: Prezzo del volo
Poche osservazioni su alcune delle variabili:
1. ‘Prezzo‘Sarà la nostra variabile dipendente e tutte le restanti variabili potranno essere usate come variabili indipendenti.
2. ‘Total_Stops'Può essere utilizzato per determinare se il volo era diretto o in coincidenza.
5.1 Gestione dei valori mancanti
Come abbiamo scoperto, le "Variabili di percorso"’ e "Total_Paradas"’ hanno valori mancanti molto bassi nei dati. Vediamo ora la percentuale di valori mancanti nei dati.
(dataframe.isnull().somma()/dataframe.shape[0])*100
Produzione :
compagnia aerea 0.000000 Data_del_viaggio 0.000000 Fonte 0.000000 Destinazione 0.000000 Rotta 0.009361 Dept_Time 0.000000 Orario di arrivo 0.000000 Durata 0.000000 Total_Stops 0.009361 Informazioni addizionali 0.000000 Prezzo 0.000000 dtype: float64
Come possiamo osservare, 'Rotta’ y "Total_Stops"’ hanno entrambi 0.0094% di valori perduti. In questo caso, è meglio rimuovere i valori mancanti.
dataframe.dropna(al posto = vero) dataframe.isnull().somma()
Produzione :
compagnia aerea 0 Data_del_viaggio 0 Fonte 0 Destinazione 0 Rotta 0 Dept_Time 0 Orario di arrivo 0 Durata 0 Total_Stops 0 Informazioni addizionali 0 Prezzo 0 dtype: int64
Ora non abbiamo perso valore.
5.2 Gestione delle variabili di data e ora
Tenemos 'Date_of_Journey', una "variabile di tipo data e"’ Rep_Time',’ Arrival_Time 'che cattura le informazioni sull'ora.
Possiamo estrarre "Journey_day"’ y 'Viaggio_Mese'’ della variabile 'Date_of_Journey'. “Giorno di viaggio” mostra il giorno del mese in cui è iniziato il viaggio.
dataframe["Viaggio_giorno"] = pd.to_datetime(dataframe.Date_of_Journey, formato="%d/%m/%Y").dt.giorno dataframe["Viaggio_mese"] = pd.to_datetime(dataframe["Data_del_viaggio"], formato = "%d/%m/%Y").dt.mese dataframe.gocciolare(["Data_del_viaggio"], asse = 1, al posto = vero)
Allo stesso modo, possiamo estrarre "Orario di partenza"’ e "Orario di partenza"’ così come "Ora di arrivo e Minuto di arrivo"’ delle variabili 'Time_dip.’ E 'orario di arrivo’ rispettivamente.
dataframe["Dep_hour"] = pd.to_datetime(dataframe["Dept_Time"]).dt.hour dataframe["Dip_min"] = pd.to_datetime(dataframe["Dept_Time"]).dt.minuto dataframe.gocciolare(["Dept_Time"], asse = 1, al posto = vero)
dataframe["Arrivo_ora"] = pd.to_datetime(dataframe.Arrival_Time).dt.hour dataframe["Arrivo_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.minuto dataframe.gocciolare(["Orario di arrivo"], asse = 1, al posto = vero)
Abbiamo anche informazioni sulla durata della variabile "Durata". Questa variabile contiene informazioni combinate di ore e minuti di durata.
Possiamo estrarre "Duration_hours"’ e "Durata_minuti"’ separatamente dalla variabile 'Durata'.
def get_duration(X):
x=x.split(' ')
hours=0
mins=0
if len(X)==1:
x=x[0]
se x[-1]=='h':
hours=int(X[:-1])
altro:
mins=int(X[:-1])
altro:
hours=int(X[0][:-1])
mins=int(X[1][:-1])
return hours,mins
dataframe['Duration_hours']=dataframe.Duration.apply(lambda x:get_duration(X)[0])
dataframe['Duration_mins']=dataframe.Duration.apply(lambda x:get_duration(X)[1])
dataframe.drop(["Durata"], asse = 1, al posto = vero)
5.3 Manejo de datos categóricos
compagnia aerea, Origen, Destino, Rotta, Total_Stops, Información adicional son las variables categóricas que tenemos en nuestros datos. Manejemos cada uno por uno.
Variable de aerolínea
Veamos cómo se relaciona la variable Aerolínea con la variable Precio.
import seaborn as sns sns.set() sns.catplot(y = "Prezzo", x = "compagnia aerea", data = train_data.sort_values("Prezzo", ascending = False), gentile="boxen", altezza = 6, aspect = 3) plt.mostra()
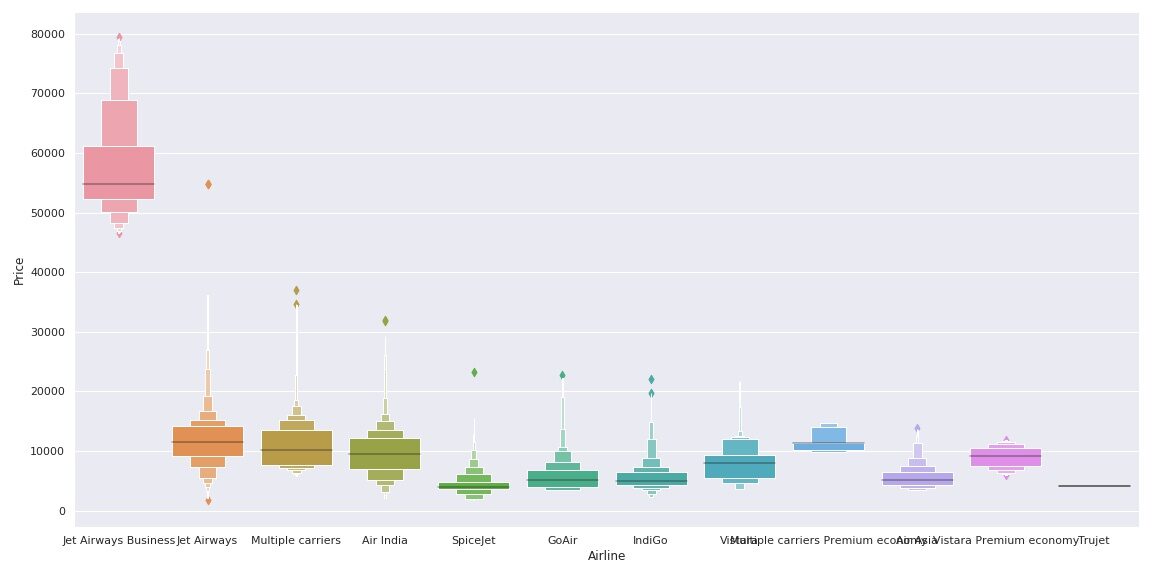
Come possiamo vedere, el nombre de la aerolínea importa. ‘JetAirways Business’ tiene el rango de precios más alto. El precio de otras aerolíneas también varía.
Dal compagnia aerea variable es Datos categóricos nominales (No hay orden de ningún tipo en los nombres de las aerolíneas) noi useremo codifica one-hot per gestire questa variabile.
Compagnia aerea = dataframe[["compagnia aerea"]] Compagnia aerea = pd.get_dummies(compagnia aerea, drop_first= Vero)
I dati di ‘Compagnia Aerea’ codificati in One-Hot sono memorizzati nella variabile Compagnia aerea come mostrato nel codice sopra.
Variabile sorgente e destinazione
Ancora, le "Variabili sorgente"’ e "Destinazione"’ sono dati categoriali nominali. Useremo di nuovo la codifica One-Hot per gestire queste due variabili.
Fonte = dataframe[["Fonte"]] Fonte = pd.get_dummies(Fonte, drop_first= Vero) Destinazione = train_data[["Destinazione"]] Destinazione = pd.get_dummies(Destinazione, drop_first = Vero)
Variabile percorso
La variabile percorso rappresenta il percorso del viaggio. Poiché la variabile "Total_Stops"’ acquisisce le informazioni se il volo è diretto o connesso, Ho deciso di eliminare questa variabile.
dataframe.drop(["Rotta", "Informazioni addizionali"], asse = 1, al posto = vero)
Variabile Total_Stops
dataframe["Total_Stops"].unico()
Produzione:
Vettore(['non-stop', '2 fermate', '1 fermata', '3 fermate', "4 fermate"],
dtype=oggetto)
Qui, significa senza sosta 0 bilancia, cosa significa volo diretto. Allo stesso modo, il significato di altri valori è ovvio. Possiamo vedere che è un Dati categorici ordinali allora useremo EtichettaEncoder qui per gestire questa variabile.
dataframe.replace({"non-stop": 0, "1 fermare": 1, "2 fermate": 2, "3 fermate": 3, "4 fermate": 4}, al posto = vero)
Variabile Informazioni_aggiuntive
dataframe.Additional_Info.unique()
Produzione:
Vettore(["Nessuna informazione", "Pasto a bordo non incluso",
"Nessun bagaglio in stiva incluso", '1 breve sosta', "Nessuna informazione",
'1 sosta lunga', "Cambia aeroporti", 'Business class',
"Volo occhi rossi", '2 Lunga sosta'], dtype=oggetto)
Come possiamo vedere, Questa funzione acquisisce informazioni rilevanti che possono influenzare in modo significativo il prezzo del volo.. Vengono ripetuti anche i valori "Nessuna informazione".. Affrontiamolo prima.
dataframe['Informazioni addizionali'].sostituire({"Nessuna informazione": "Nessuna informazione"}, al posto = vero)
però, questa variabile è anche un dato categorico nominale. Usiamo la codifica One-Hot per gestire questa variabile.
Add_info = dataframe[["Informazioni addizionali"]] Add_info = pd.get_dummies(Add_info, drop_first = Vero)
5.4 Marco de datos final
Ahora crearemos el marco de datos final concatenando todas las características codificadas por etiquetas y One-hot en el marco de datos original. También eliminaremos las variables originales con las que hemos preparado nuevas variables codificadas.
dataframe = pd.concat([dataframe, compagnia aerea, Fonte, Destinazione,Add_info], asse = 1) dataframe.drop(["compagnia aerea", "Fonte", "Destinazione","Informazioni addizionali"], asse = 1, al posto = vero)
Veamos el número de variables finales que tenemos en el marco de datos.
dataframe.shape[1]
Produzione:
38
Quindi, avere 38 variables en el marco de datos final, incluida la variable dependiente ‘Precio’. C'è solo 37 variables para el addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
6. Costruzione di modelli
X=dataframe.drop('Prezzo',asse=1) y=dataframe['Prezzo'] #train-test split from sklearn.model_selection import train_test_split x_treno, x_test, y_train, y_test = train_test_split(X, e, test_size = 0.2, stato_casuale = 42)
6.1 Aplicación de la predicción perezosa
Uno de los problemas del ejercicio de creación de modelos es “¿Cómo decidir qué algoritmo de aprendizaje automático aplicar?”
Aquí es donde entra en juego Lazy Prediction. Lazy Prediction es una biblioteca de aprendizaje automático disponible en Python que puede proporcionarnos rápidamente el rendimiento de múltiples clasificaciones estándar o modelos de regresión en múltiples matrices de rendimiento.
Vamos a ver cómo funciona…
Como estamos trabajando en una tarea de Regresión, usaremos modelos Regresores.
from lazypredict.Supervised import LazyRegressor reg = LazyRegressor(verboso=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(x_treno, x_test, y_train, y_test) models.head(10)
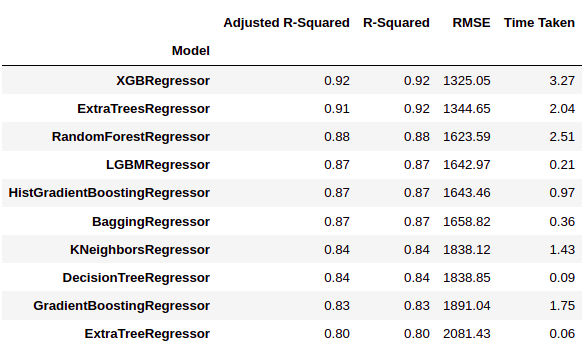
Come possiamo vedere, LazyPredict nos da resultados de múltiples modelos en múltiples matrices de desempeño. Nella figura sopra, hemos mostrado los diez mejores modelos.
Aquí ‘XGBRegressor’ y ‘ExtraTreesRegressor’ superan significativamente a otros modelos. Se necesita una gran cantidad de tiempo de entrenamiento con respecto a otros modelos. En este paso podemos elegir la prioridad si queremos “tempo metereologico” oh “prestazione”.
Hemos decidido elegir “prestazione” sobre el tiempo de entrenamiento. Así que entrenaremos a ‘XGBRegressor y visualizaremos los resultados finales.
6.2 Formazione modello
from xgboost import XGBRegressor
model = XGBRegressor()
model.fit(x_treno,y_train)
Produzione:
XGBRegressor(base_score=0.5, booster="gbtree", colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1, importance_type="gain", interaction_constraints="", learning_rate=0.300000012, max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan, monotone_constraints="()", n_estimatori = 100, n_jobs=0, num_parallel_tree=1, stato_casuale=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1, tree_method='exact', validate_parameters=1, verbosity=None)
Comprobemos el rendimiento del modelo …
y_pred = model.predict(x_test) Stampa('Training Score :',model.score(x_treno, y_train)) Stampa('Test Score :',model.score(x_test, y_test))
Produzione:
Training Score : 0.9680428701701702 Test Score : 0.918818721300552
Come possiamo vedere, la puntuación del modelo es bastante buena. Visualicemos los resultados de algunas predicciones.
number_of_observations=50 x_ax = range(len(y_test[:number_of_observations])) plt.trama(x_ax, y_test[:number_of_observations], etichetta="originale") plt.trama(x_ax, y_pred[:number_of_observations], etichetta="previsto") plt.titolo("Flight Price test and predicted data") plt.xlabel('Observation Number') plt.ylabel('Prezzo') plt.legend() plt.mostra()
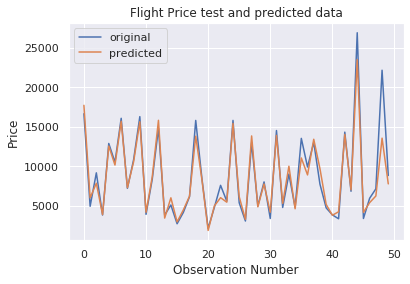
Como podemos observar en la figura anterior, las predicciones del modelo y los precios originales se superponen. Este resultado visual confirma la alta puntuación del modelo que vimos anteriormente.
7. conclusione
In questo articolo, vimos cómo aplicar la biblioteca Laze Prediction para elegir el mejor algoritmo de aprendizaje automático para la tarea en cuestión.
Lazy Prediction ahorra tiempo y esfuerzos para crear un modelo de aprendizaje automático al proporcionar rendimiento del modelo y tiempo de capacitación. Si può scegliere qualsiasi in base alla situazione in questione.
Può anche essere utilizzato per creare una serie di modelli di apprendimento automatico. Esistono molti modi in cui è possibile utilizzare le funzionalità della libreria LazyPredict.
Spero che questo articolo ti abbia aiutato a capire gli approcci di analisi dei dati, preparazione e modellazione dei dati in un modo molto più semplice.
Contatta la sezione commenti in caso di qualsiasi domanda.
Grazie e buona giornata.. ?
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





