Considera il seguente fatto:
Facebook ha attualmente più di un miliardo di utenti attivi ogni mese
Prendiamoci qualche secondo per pensare a quali informazioni solitamente memorizza Facebook sui suoi utenti. Alcuni di questi sono:
- Dati demografici di base (come esempio, data di nascita, sesso, Posizione attuale, posizione precedente, Università)
- Attività dell'utente e accordo di aggiornamento (le loro foto, Commenti, mi piace, applicazioni che hai usato, giochi che hai giocato, post, chat, eccetera.)
- Il tuo social network (i tuoi amici, i loro circoli, come sei imparentato?, eccetera.)
- Interessi dell'utente (Leggere libri, film visti, posti, eccetera.)

Usando questa e molte altre informazioni (come esempio, su cosa ha cliccato un utente, cosa hai letto e quanto tempo ci hai dedicato), Facebook fa quanto segue in tempo reale:
- Consiglia le persone che conosci e le connessioni reciproche con loro.
- Usa le tue attività attuali e passate per capire cosa ti interessa
- Contattarti con gli aggiornamenti, attività e annunci che potrebbero interessarti di più.
Allo stesso tempo di questi, ci sono attività a breve termine (aggiornato in batch e non in tempo reale) come il numero di persone che parlano di una pagina, persone raggiunte in una settimana.
Ora, immagina il tipo di infrastruttura dati necessaria per eseguire Facebook, le dimensioni del tuo data center, la potenza di elaborazione richiesta per soddisfare i requisiti dell'utente. La grandezza può essere eccitante o terrificante, dipende da come la guardi.
La prossima infografica di IBM mette in evidenza l'entità dei requisiti / elaborazione dati per alcune istituzioni simili:

Questo tipo di dimensione e scala non è stato ascoltato da nessun analista fino a pochi anni fa e l'infrastruttura di dati in cui alcune di queste istituzioni avevano investito non era preparata per gestire questa scala.. Questo è spesso chiamato un problema di Big Data..
Quindi, Cosa sono i big data?
I big data sono dati troppo grandi, complesso e dinamico da acquisire per qualsiasi strumento di dati convenzionale, negozio, gestire e analizzare. Gli strumenti tradizionali sono stati progettati pensando alla scala. Come esempio, quando un'organizzazione vuole investire in una soluzione di Business Intelligence, partner di implementazione verrebbe, studiare i requisiti aziendali e quindi creare una soluzione per soddisfare questi requisiti.
Se il requisito per questa organizzazione aumenta nel tempo o se si desidera eseguire un'analisi più granulare, ha dovuto reinvestire nell'infrastruttura dei dati. Il costo delle risorse coinvolte nell'aumento delle risorse che vengono regolarmente utilizzate per aumentare in modo esponenziale. Allo stesso tempo, ci sarebbe una limitazione alla dimensione a cui potrebbe scalare (come esempio, dimensione della macchina, processore, RAM, eccetera.). Questi sistemi tradizionali non potevano supportare la scala richiesta da alcune delle società Internet..
In che modo i big data sono diversi dai dati tradizionali??
Per fortuna o sfortuna, non c'è limite di dimensione / parametrico per scegliere se i dati sono “grandi dati” o no. I big data sono tipicamente caratterizzati sulla base di ciò che è comunemente noto come 3 VS:
- Volume – Attualmente, ci sono istituzioni che producono terabyte di dati in un giorno. Con l'aumento dei dati, dovrai lasciare alcuni dati non analizzati, se vuoi usare strumenti tradizionali. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que el tamaño de los datos aumente aún más, lascerà sempre più dati non analizzati. Questo significa lasciare il valore sul tavolo. Ha tutte le informazioni su ciò che il cliente sta facendo e dicendo, Ma non riesco a capire! – un segno sicuro che hai a che fare con dati più grandi di quelli supportati dal tuo sistema.
- Varietà – Anche se il volume è solo l'inizio, la varietà è ciò che rende molto difficili gli strumenti tradizionali. Gli strumenti tradizionali funzionano meglio con i dati strutturati. Richiedi che i dati abbiano una struttura e un formato particolari per avere un senso. Nonostante questo, il flusso di dati dalle e-mail, opinione del cliente, forum sui social media, il percorso del cliente nel portale web e nei call center non sono strutturati per natura o, nel migliore dei casi, sono semi-strutturati.
- Velocità – La velocità con cui vengono generati i dati è critica quanto gli altri due fattori. La velocità con cui un'azienda può analizzare i dati alla fine diventerebbe per loro un vantaggio competitivo.. È la sua velocità di analisi che consente a Google di prevedere la posizione dei pazienti affetti da influenza quasi in tempo reale. Perché, se non riesci ad analizzare i dati a una velocità superiore al tuo flusso di input, potresti aver bisogno di una soluzione per i big data.
Individualmente, ognuna di queste V può ancora essere riparata con l'aiuto di soluzioni tradizionali. Come esempio, se la maggior parte dei tuoi dati è strutturata, puoi ancora ottenere da 80% al 90% di valore commerciale attraverso strumenti tradizionali. Nonostante questo, se affronti una sfida con i tre Vs, saprai che si tratta “grandi dati”.

Quando hai bisogno di una soluzione per i big data?
sebbene il 3 V ti dirà se hai a che fare con "big data" o no, se hai bisogno o meno di una soluzione per i big data a seconda delle tue esigenze. Di seguito sono riportati gli scenari in cui le soluzioni per i big data sono intrinsecamente più adatte:
- Quando si tratta di big data semi-strutturati o non strutturati da più fonti
- Devi analizzare tutti i tuoi dati e non puoi lavorare con il campionamento.
- La procedura è di natura iterativa (come esempio, ricerche nel motore di ricerca di Google, cerca la grafica su Facebook)
Come funziona la risposta sui big data?
Sebbene i limiti delle soluzioni tradizionali siano chiari, In che modo le soluzioni per i big data li risolvono?? Le soluzioni Big Data operano su un'architettura fondamentalmente diversa che si basa sulle seguenti caratteristiche (illustrativo sotto):
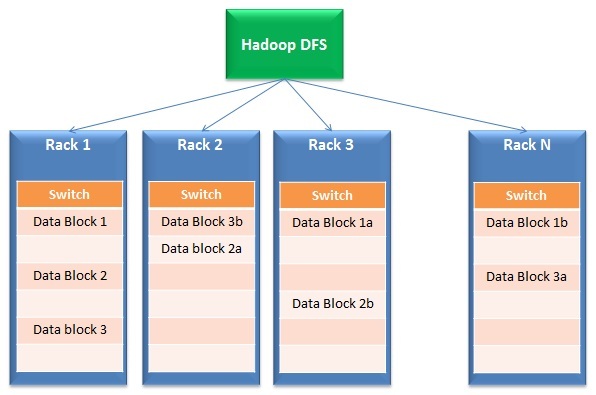
- Distribuzione dei dati ed elaborazione parallela: Le soluzioni per i big data funzionano su storage distribuito ed elaborazione parallela. Brevemente, i file sono divisi in diversi piccoli blocchi e memorizzati in diverse unità (chiama dietro le quinte). Dopo, l'elaborazione avviene in parallelo in questi blocchi e i risultati vengono nuovamente uniti. La prima parte dell'operazione è tipicamente chiamata File system distribuitoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... (DFS) mentre la seconda parte si chiama Mappa piccola.
- Tolleranza per il fallimento: Per la natura del suo design, la risposta ai big data ha una ridondanza incorporata. Come esempio, Hadoop crea 3 copie di ogni blocco di dati in almeno 2 rack. Perché, anche se un rack completo si guasta o non è abilitato, la risposta funziona ancora. Perché è incorporato?? Questa funzionalità consente alle soluzioni Big Data di scalare fino a un hardware entry-level economico invece di costosi dischi SAN..
- Scalabilità e flessibilità: Questa è la genesi del paradigma completo delle soluzioni big data. Puede agregar o quitar racks fácilmente del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... sin preocuparse por el tamaño para el que se diseñó esta solución.
- Efficacia dei costi: A causa dell'uso di hardware di base, il costo della creazione di questa infrastruttura è molto inferiore rispetto all'acquisto di server costosi con dischi resistenti ai guasti (come esempio, SAN)
In sintesi, E se tutto questo fosse nel cloud??
Sebbene lo sviluppo di un'architettura di big data sia redditizio, trovare le risorse giuste è difficile, che aumenta il costo di implementazione.
Immagina una situazione in cui un fornitore di servizi cloud si occupa anche di tutte le tue preoccupazioni IT / infrastruttura. Ti concentri sulla conduzione di analisi e sulla fornitura di risultati all'azienda invece di organizzare i rack e preoccuparti della portata del loro utilizzo.
Tutto quello che devi fare è pagare in base al tuo utilizzo. Attualmente, sul mercato sono disponibili soluzioni end-to-end, dove non solo puoi archiviare i tuoi dati nel cloud, ma anche consultarli e analizzarli nel cloud. Puoi interrogare terabyte di dati in pochi secondi e lasciare a qualcun altro tutte le preoccupazioni per questa infrastruttura!!
Anche se ho fornito una panoramica delle soluzioni per i big data, questo non copre affatto l'intero spettro. Lo scopo è iniziare il viaggio ed essere preparati per la rivoluzione che è in corso..





