Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Ciao ragazzi! In questo blog, Discuterò tutto sulla classificazione delle immagini.
Negli ultimi anni, Deep Learning ha dimostrato di essere uno strumento molto potente grazie alla sua capacità di gestire grandi quantità di dati. L'uso di strati nascosti supera le tecniche tradizionali, soprattutto per il riconoscimento dei modelli. Una delle reti neurali profonde più popolari sono le reti neurali convoluzionali (CNN).
UN convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. (CNN) è una specie di neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. artificial (ANN) utilizzato nel riconoscimento e nell'elaborazione delle immagini, che è appositamente progettato per elaborare i dati (pixel).
Fonte immagine: Google.com
Prima di andare avanti, dobbiamo capire cos'è la rete neurale. Andiamo…
neuronale rosso:
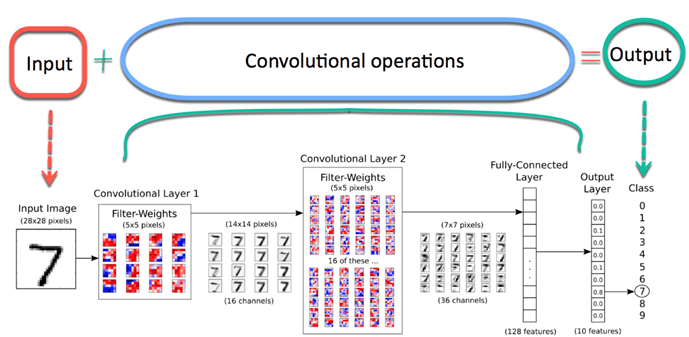
Una rete neurale è costituita da diversi nodi interconnessi chiamati “neuroni”. I neuroni sono organizzati in livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche...., capa oculta y Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati..... Il livello di input corrisponde ai nostri predittori / caratteristiche e il livello di output alle nostre variabili di risposta.
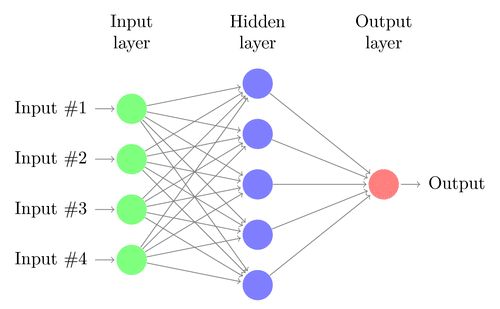
Fonte immagine: Google.com
Perceptron multistrato (MLP):
La rete neurale con un livello di input, uno o più livelli nascosti e viene chiamato un livello di output perceptron multistrato (MLP). MLP è inventato da Frank Rosenblatt Nell'anno di 1957. MLP mostrato di seguito ha 5 nodi di input, 5 nodos ocultos con dos capas ocultas y un nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... de salida
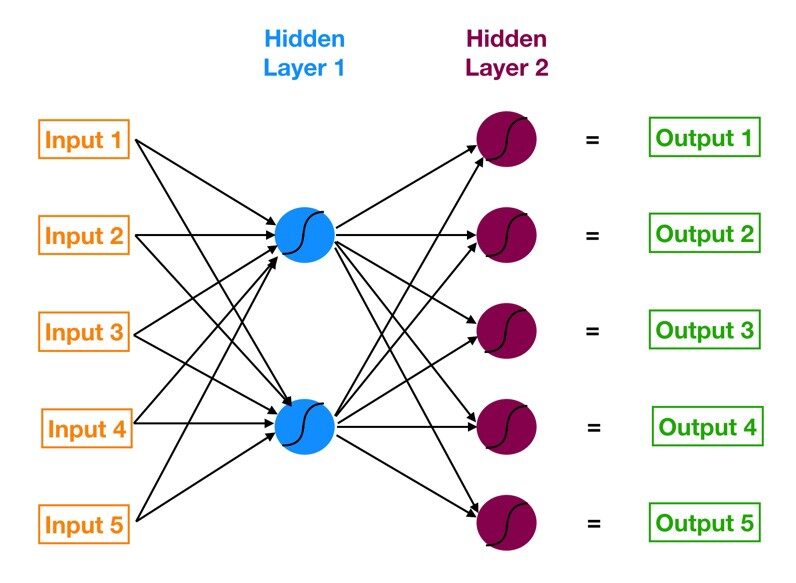
Fonte immagine: Google.com
Come funziona questa rete neurale?
– I neuroni dello strato di input ricevono informazioni in entrata dai dati che elaborano e distribuiscono al strati nascosti.
– quell'informazione, allo stesso tempo, viene elaborato da livelli nascosti e passato all'output. neuroni.
– Le informazioni da questa rete neurale artificiale (ANN) viene elaborato in termini di a funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni..... Questa funzione imita effettivamente i neuroni nel cervello.
– Ogni neurone contiene un valore di funzioni di attivazione e un valore di soglia.
– Il valore di soglia è il valore minimo che l'ingresso deve avere per attivarsi.
– Il compito del neurone è quello di eseguire una somma pesata di tutti i segnali in ingresso e applicare la funzione di attivazione sulla somma prima di passarla allo strato successivo. (nascosto o esci).
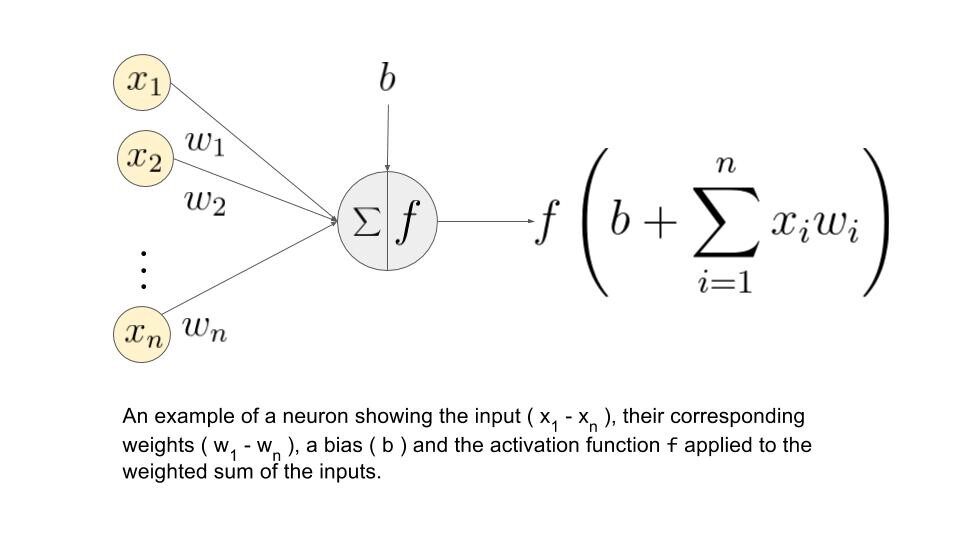
Capiamo qual è la somma ponderata.
Diciamo che abbiamo valori 𝑎1, 2, 3, 𝑎4 per input e pesi come 𝑤1, 2, 3, 4 come input per uno dei neuroni dello strato nascosto, diciamo, quindi la somma ponderata è rappresentata come
𝑆𝑗 = σ 𝑖 = 1to4 𝑤𝑖 * 𝑎𝑖 + ?
dove: bias dovuto al nodo
Fonte immagine: Google.com
Quali sono le funzioni di attivazione?
Queste funzioni sono necessarie per introdurre una non linearità nella rete. La funzione trigger viene applicata e quell'output viene passato al livello successivo.
* Funzioni possibili *
• Sigmoide: la funzione sigmoide è differenziabile. Produce un output tra 0 e 1.
• Tangente iperbolica: Anche la tangente iperbolica è differenziabile. Questo produce un output tra -1 e 1.
• riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione..: ReLU è la funzione più popolare. ReLU se usa ampliamente en el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
• Softmax: il Funzione SoftMaxLa funzione softmax è uno strumento matematico utilizzato nel campo dell'apprendimento automatico, soprattutto nelle reti neurali. Converte un vettore di valore in una distribuzione di probabilità, Assegnazione di probabilità a ciascuna classe in problemi di multi-classificazione. La sua formula normalizza gli output, garantire che la somma di tutte le probabilità sia uguale a uno, consentendo un'interpretazione efficace dei risultati. È essenziale nell'ottimizzazione della... se utiliza para problemas de clasificación de clases múltiples. È una generalizzazione della funzione sigmoide. Produce anche un output tra 0 e 1
Ora, andiamo con il nostro tema CNN …
CNN:
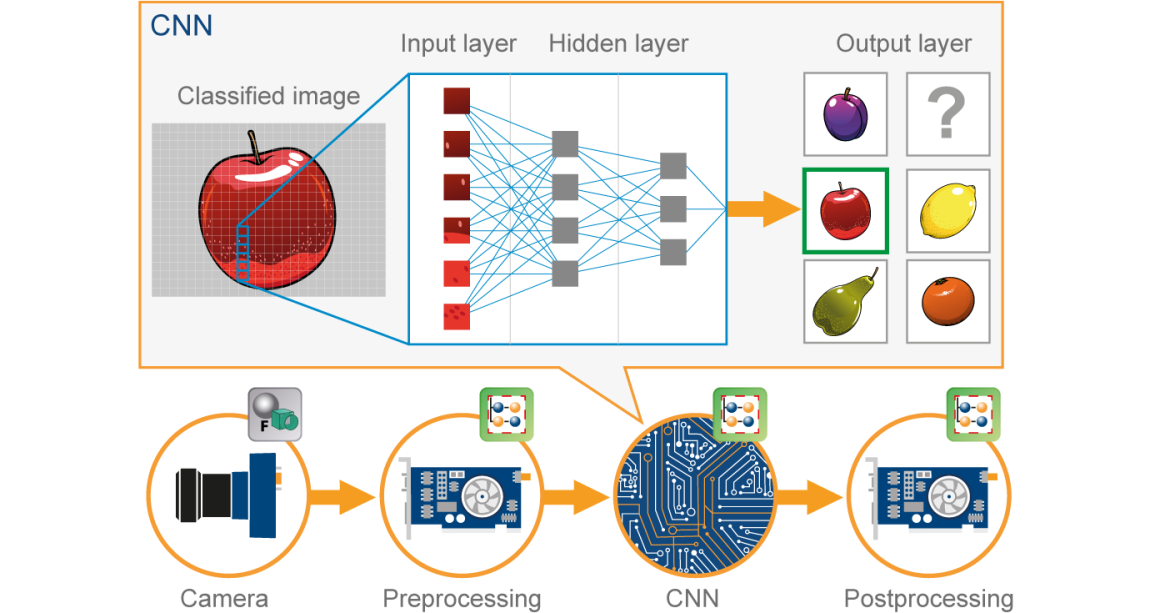
Ora immagina che ci sia la foto di un uccello, e vuoi identificarlo se è davvero un uccello o qualcos'altro. La prima cosa che devi fare è alimentare i pixel dell'immagine sotto forma di array al livello di input della rete neurale (Le reti MLP vengono utilizzate per classificare queste cose). I livelli nascosti trasportano l'estrazione delle caratteristiche eseguendo vari calcoli e operazioni. Ci sono diversi livelli nascosti come la convoluzione, il ReLU e il livello di raggruppamento che esegue l'estrazione delle caratteristiche dall'immagine. Quindi, Finalmente, c'è un livello completamente connesso che puoi vedere che identifica l'oggetto esatto nell'immagine. Puede comprender muy fácilmente en la siguiente figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline....:
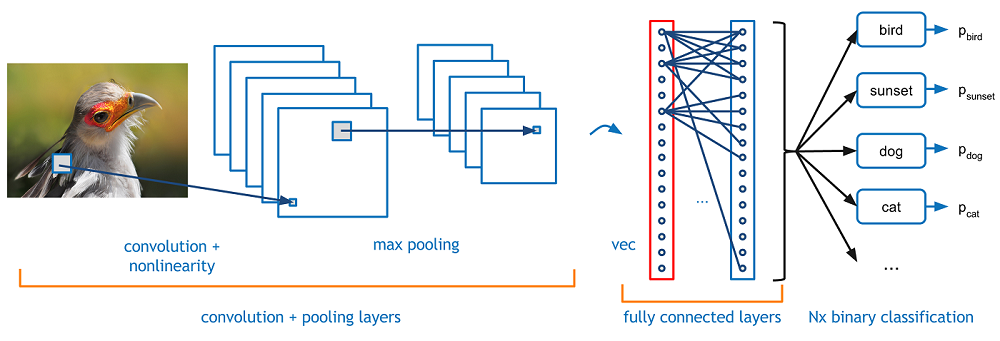
Fonte immagine: Google.com
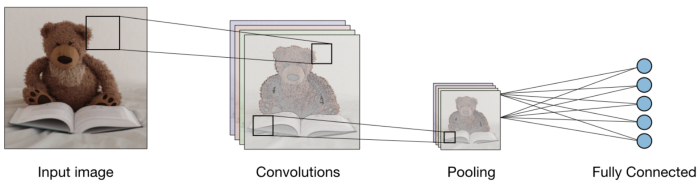
convoluzione:-
L'operazione di convoluzione prevede operazioni aritmetiche matriciali e ogni immagine è rappresentata come un array di valori (pixel).
Capiamo l'esempio:
a = [2,5,8,4,7,9]
b = [1,2,3]
Nell'operazione di convoluzione, le matrici vengono moltiplicate una per una in termini di elementi, e il prodotto viene raggruppato o sommato per creare una nuova matrice che rappresenta un * B.
I primi tre elementi dell'array un ora moltiplica per gli elementi dell'array B. Il prodotto viene aggiunto per ottenere il risultato e viene immagazzinato in una nuova matrice di un * B.
Questo processo rimane continuo fino al completamento dell'operazione..
Fonte immagine: Google.com
Raggruppamento:
Dopo la convoluzione, c'è un'altra operazione chiamata raggruppamento. Quindi, Nella catena, convoluzione e raggruppamento vengono applicati in sequenza sui dati al fine di estrarre alcune caratteristiche dai dati. Dopo livelli cluster sequenziali e convoluzionali, i dati sono appiattiti
in una rete neurale di feedback che è anche chiamata percettrone multistrato.
Fonte immagine: Google.com
Finora, abbiamo visto concetti che sono importanti per il nostro modello di costruzione della CNN.
Ora andremo avanti per vedere un caso di studio della CNN.
1) Qui importeremo le librerie necessarie necessarie per eseguire le attività CNN.
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)
2) Qui richiediamo il seguente codice per formare il modello CNN
modello = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),attivazione = "riprendere" , input_forma = (180,180,3)) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),attivazione = "riprendere") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),attivazione = "riprendere") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128,(3,3),attivazione = "riprendere"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Appiattire(),
tf.strati.duri.Densi(550,attivazione="riprendere"), #Adding the Hidden layer
tf.keras.layers.Dropout(0.1,seme = 2019),
tf.strati.duri.Densi(400,attivazione ="riprendere"),
tf.keras.layers.Dropout(0.3,seme = 2019),
tf.strati.duri.Densi(300,attivazione="riprendere"),
tf.keras.layers.Dropout(0.4,seme = 2019),
tf.strati.duri.Densi(200,attivazione ="riprendere"),
tf.keras.layers.Dropout(0.2,seme = 2019),
tf.strati.duri.Densi(5,attivazione = "softmax") #Aggiunta del livello di output
])
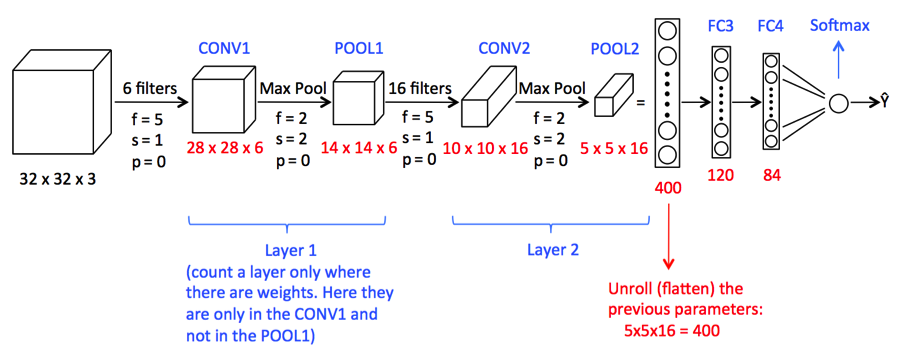
Un'immagine contorta potrebbe essere troppo grande e, così, si restringe senza perdere feature o serie, quindi il raggruppamento è fatto.
Qui, Creare una rete neurale significa inizializzare la rete utilizzando il modello sequenziale Keras.
Appiattire (): l'appiattimento trasforma una matrice bidimensionale di feature in un vettore di feature.
3) Ora diamo un'occhiata a un riepilogo del modello della CNN
modello.riepilogo()
Stamperai il seguente output
Modello: "sequenziale" _________________________________________________________________ Strato (genere) Parametro forma di output # ================================================================= conv2d (Conv2D) (Nessuno, 178, 178, 16) 448 _________________________________________________________________ max_pooling2d (MaxPooling2D) (Nessuno, 89, 89, 16) 0 _________________________________________________________________ conv2d_1 (Conv2D) (Nessuno, 87, 87, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (Nessuno, 43, 43, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (Nessuno, 41, 41, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (Nessuno, 20, 20, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (Nessuno, 18, 18, 128) 73856 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (Nessuno, 9, 9, 128) 0 _________________________________________________________________ flatten (Appiattire) (Nessuno, 10368) 0 _________________________________________________________________ dense (Denso) (Nessuno, 550) 5702950 _________________________________________________________________ dropout (Ritirarsi) (Nessuno, 550) 0 _________________________________________________________________ dense_1 (Denso) (Nessuno, 400) 220400 _________________________________________________________________ dropout_1 (Ritirarsi) (Nessuno, 400) 0 _________________________________________________________________ densa_2 (Denso) (Nessuno, 300) 120300 _________________________________________________________________ dropout_2 (Ritirarsi) (Nessuno, 300) 0 _________________________________________________________________ densa_3 (Denso) (Nessuno, 200) 60200 _________________________________________________________________ dropout_3 (Ritirarsi) (Nessuno, 200) 0 _________________________________________________________________ dense_4 (Denso) (Nessuno, 5) 1005 ================================================== =============== Parametri totali: 6,202,295 Parametri addestrabili: 6,202,295 Parametri non addestrabili: 0
4) Así que ahora estamos obligados a especificar optimizadores.
da tensorflow.keras.optimizers importare RMSprop,SGD,Adam
adam=Adam(lr=0,001)
modello.compila(ottimizzatore="Adamo", perdita="categorical_crossentropy", metriche = ['acc'])
L'ottimizzatore viene utilizzato per ridurre il costo calcolato per entropia incrociata
Il Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... se utiliza para calcular el error.
Il termine metriche viene utilizzato per rappresentare l'efficienza del modello.
5) In questo passaggio, vedremo come configurare la directory dei dati e generare i dati dell'immagine.
bs=30 #Setting batch size train_dir = "D:/Data Science/Set di dati di immagini/FastFood/treno/" #Setting training directory validation_dir = "D:/Data Science/Set di dati di immagini/FastFood/test/" #Setting testing directory from tensorflow.keras.preprocessing.image import ImageDataGenerator # Tutte le immagini verranno ridimensionate da 1./255. train_datagen = ImageDataGenerator( ridimensionamento = 1.0/255. ) test_datagen = ImageDataGenerator( ridimensionamento = 1.0/255. ) # Immagini di addestramento del flusso in lotti di 20 using train_datagen generator #Flow_from_directory function lets the classifier directly identify the labels from the name of the directories the image lies in train_generator=train_datagen.flow_from_directory(train_dir,batch_size=bs,class_mode="categorico",target_size=(180,180)) # Immagini di convalida del flusso in batch di 20 using test_datagen generator validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=bs, class_mode="categorico", target_size=(180,180))
La salida será:
Fondare 1465 immagini appartenenti a 5 Classi. Fondare 893 immagini appartenenti a 5 Classi.
6) Paso final del modelo de ajuste.
storia = modello.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=150 // B,
epoche=30,
validation_steps=50 // B,
verboso=2)
La salida será:
Epoca 1/30 5/5 - 4S - perdita: 0.8625 - acc: 0.6933 - val_loss: 1.1741 - val_acc: 0.5000 Epoca 2/30 5/5 - 3S - perdita: 0.7539 - acc: 0.7467 - val_loss: 1.2036 - val_acc: 0.5333 Epoca 3/30 5/5 - 3S - perdita: 0.7829 - acc: 0.7400 - val_loss: 1.2483 - val_acc: 0.5667 Epoca 4/30 5/5 - 3S - perdita: 0.6823 - acc: 0.7867 - val_loss: 1.3290 - val_acc: 0.4333 Epoca 5/30 5/5 - 3S - perdita: 0.6892 - acc: 0.7800 - val_loss: 1.6482 - val_acc: 0.4333 Epoca 6/30 5/5 - 3S - perdita: 0.7903 - acc: 0.7467 - val_loss: 1.0440 - val_acc: 0.6333 Epoca 7/30 5/5 - 3S - perdita: 0.5731 - acc: 0.8267 - val_loss: 1.5226 - val_acc: 0.5000 Epoca 8/30 5/5 - 3S - perdita: 0.5949 - acc: 0.8333 - val_loss: 0.9984 - val_acc: 0.6667 Epoca 9/30 5/5 - 3S - perdita: 0.6162 - acc: 0.8069 - val_loss: 1.1490 - val_acc: 0.5667 Epoca 10/30 5/5 - 3S - perdita: 0.7509 - acc: 0.7600 - val_loss: 1.3168 - val_acc: 0.5000 Epoca 11/30 5/5 - 4S - perdita: 0.6180 - acc: 0.7862 - val_loss: 1.1918 - val_acc: 0.7000 Epoca 12/30 5/5 - 3S - perdita: 0.4936 - acc: 0.8467 - val_loss: 1.0488 - val_acc: 0.6333 Epoca 13/30 5/5 - 3S - perdita: 0.4290 - acc: 0.8400 - val_loss: 0.9400 - val_acc: 0.6667 Epoca 14/30 5/5 - 3S - perdita: 0.4205 - acc: 0.8533 - val_loss: 1.0716 - val_acc: 0.7000 Epoca 15/30 5/5 - 4S - perdita: 0.5750 - acc: 0.8067 - val_loss: 1.2055 - val_acc: 0.6000 Epoca 16/30 5/5 - 4S - perdita: 0.4080 - acc: 0.8533 - val_loss: 1.5014 - val_acc: 0.6667 Epoca 17/30 5/5 - 3S - perdita: 0.3686 - acc: 0.8467 - val_loss: 1.0441 - val_acc: 0.5667 Epoca 18/30 5/5 - 3S - perdita: 0.5474 - acc: 0.8067 - val_loss: 0.9662 - val_acc: 0.7333 Epoca 19/30 5/5 - 3S - perdita: 0.5646 - acc: 0.8138 - val_loss: 0.9151 - val_acc: 0.7000 Epoca 20/30 5/5 - 4S - perdita: 0.3579 - acc: 0.8800 - val_loss: 1.4184 - val_acc: 0.5667 Epoca 21/30 5/5 - 3S - perdita: 0.3714 - acc: 0.8800 - val_loss: 2.0762 - val_acc: 0.6333 Epoca 22/30 5/5 - 3S - perdita: 0.3654 - acc: 0.8933 - val_loss: 1.8273 - val_acc: 0.5667 Epoca 23/30 5/5 - 3S - perdita: 0.3845 - acc: 0.8933 - val_loss: 1.0199 - val_acc: 0.7333 Epoca 24/30 5/5 - 3S - perdita: 0.3356 - acc: 0.9000 - val_loss: 0.5168 - val_acc: 0.8333 Epoca 25/30 5/5 - 3S - perdita: 0.3612 - acc: 0.8667 - val_loss: 1.7924 - val_acc: 0.5667 Epoca 26/30 5/5 - 3S - perdita: 0.3075 - acc: 0.8867 - val_loss: 1.0720 - val_acc: 0.6667 Epoca 27/30 5/5 - 3S - perdita: 0.2820 - acc: 0.9400 - val_loss: 2.2798 - val_acc: 0.5667 Epoca 28/30 5/5 - 3S - perdita: 0.3606 - acc: 0.8621 - val_loss: 1.2423 - val_acc: 0.8000 Epoca 29/30 5/5 - 3S - perdita: 0.2630 - acc: 0.9000 - val_loss: 1.4235 - val_acc: 0.6333 Epoca 30/30 5/5 - 3S - perdita: 0.3790 - acc: 0.9000 - val_loss: 0.6173 - val_acc: 0.8000
La función anterior entrena la red neuronal utilizando el conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y evalúa su rendimiento en el conjunto de prueba. Le funzioni restituiscono due metriche per ogni epoca 'acc’ y 'val_acc’ quali sono la precisione delle previsioni ottenute nel training set e la precisione raggiunta nel test set, rispettivamente.
conclusione:
Perciò, vediamo che è stato accolto con sufficiente precisione. tuttavia, chiunque può eseguire questo modello aumentando il numero di epoche o qualsiasi altro parametro.
Spero che il mio articolo ti sia piaciuto. condividi con i tuoi amici, colleghi.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





