Archivia i modelli nei bucket di Google Cloud Storage e quindi scrivi Google Cloud Functions. Usando Python para recuperar modelos del depósito y usando solicitudes HTTP JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.., possiamo ottenere i valori previsti per gli input forniti con l'aiuto di Google Cloud Function.
1. Per quanto riguarda i dati, codice e modelli
Prendendo le recensioni dei film set di dati per l'analisi del sentimento, vedi la risposta qui nel mio repository GitHub e dati, Modelli disponibile anche nello stesso repository.
2. Crea un bucket di archiviazione
Quando si esegue il “ServerlessDeployment.ipynb"File otterrà 3 Modelli ML: Classificatore di decisioni, LinearSVC e regressione logistica.
Fare clic sull'opzione Browser di archiviazione per creare un nuovo bucket come mostrato nell'immagine:
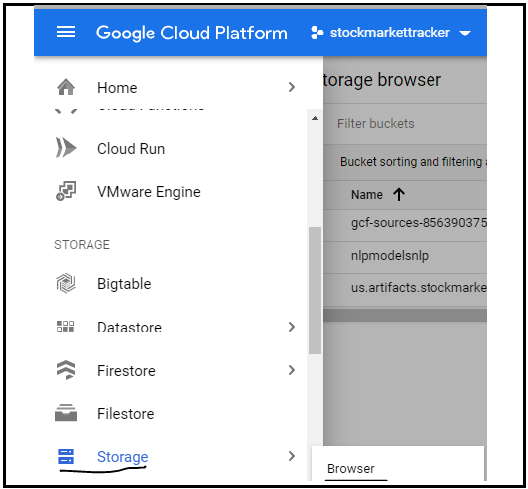
FIGURA: fai clic sull'opzione Negozio GCP
3. Crea un nuovo ruolo
Crea un nuovo secchio, quindi creare una cartella e caricare il 3 modelli in quella cartella creando 3 sottocartelle come mostrato.
Qui Modelli sono il nome della mia cartella principale e le mie sottocartelle sono:
- modello_albero_decisione
- linear_svc_model
- modello_regione_logistica
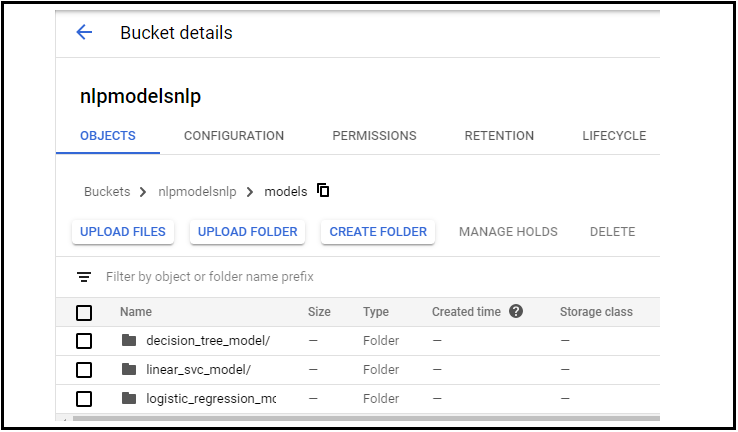
FIGURA: Cartelle in deposito
4. Crea una funzione
Successivamente, vai a Google Cloud Functions e crea una funzione, quindi seleziona il tipo di trigger come HTTP e seleziona la lingua come Python (puoi selezionare qualsiasi lingua):
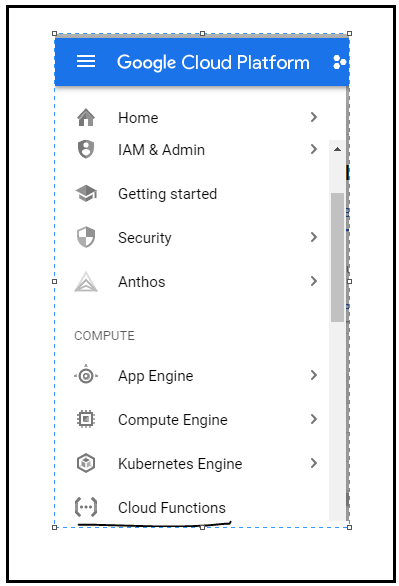
FIGURA: Seleziona l'opzione GCP Cloud Function
5. Scrivi la funzione cloud nell'editor.
Controlla la funzione cloud nel mio repository, qui ho importato le librerie richieste per chiamare i modelli da google cloud warehouse e altre librerie per la richiesta HTTP Metodo GET utilizzato per testare la soluzione URL e il metodo POST eliminare il modello predefinito e incollare il nostro codice in seguito cetriolino viene utilizzato per deserializzare il nostro modello google.cloud: accedi alla nostra funzione di archiviazione cloud.
Se la richiesta in arrivo è OTTENERE semplicemente torniamo “benvenuto nel classificatore”.
Se la richiesta in arrivo è MAIL inserisci i dati JSON nel corpo della richiesta ottieni JSON ci dà per istanziare l'oggetto client di archiviazione e inserire i modelli dal magazzino, qui abbiamo 3 – modelli di classificazione in magazzino.
Se l'utente specifica "Decision Classifier" accediamo al modello dalla rispettiva cartella rispettivamente con altri modelli.
Se l'utente non specifica alcun modello, il modello predefinito è il modello di regressione logistica.
Il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... blob contiene una referencia al archivo model.pkl para el modelo correcto.
Scarichiamo il file .pkl sulla macchina locale in cui questa funzione viene eseguita nel cloud. Ora, ogni chiamata potrebbe essere in esecuzione in una macchina virtuale diversa e accediamo solo alla cartella / temperatura sulla VM, ecco perché salviamo il nostro file model.pkl.
Desterilizziamo il modello invocando pkl.load per inserire le istanze di previsione dalla richiesta in arrivo e chiamiamo model.predict sui dati di previsione.
La soluzione che verrà inviata dalla funzione serverless è il testo originale che è la revisione che vogliamo classificare e la nostra classe pred.
Dopo main.py, scrivi require.txt con le librerie e le versioni richieste
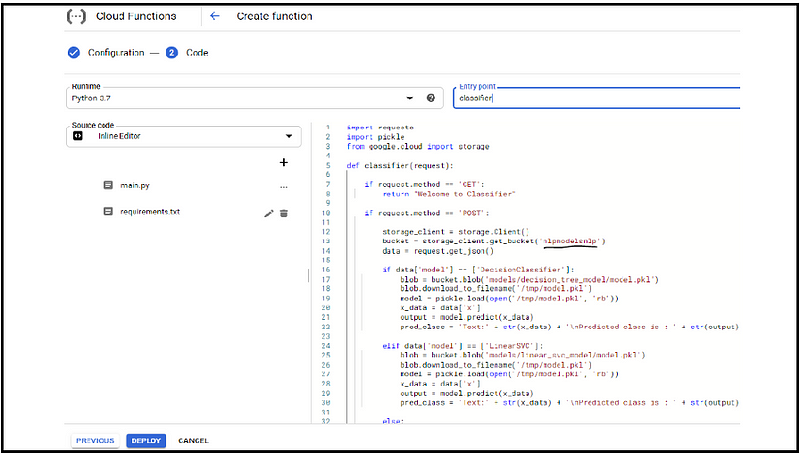
5. Metti in pratica il modello
6. Prova il modello
Diventa uno scienziato di dati full stack imparando varie implementazioni del modello ML e il motivo alla base di questa grande spiegazione nei primi giorni ho difficoltà a imparare l'implementazione del modello ML, quindi ho deciso che il mio blog dovrebbe essere utile per i principianti di data science dall'inizio alla fine.





