
R Siete pronti? Impariamo a raggruppare in R.
http: // www.paginaS: //www.rstudio.com/products/rstudio/download/
Visualizzazione dei dati utilizzando R
Nei tempi presenti, le immagini parlano più forte dei numeri o dell'analisi delle parole. sì, grafici e diagrammi sono più attraenti e facili da identificare per l'occhio umano. È qui che entra in gioco l'importanza dell'analisi dei dati R.. I clienti comprendono meglio la rappresentazione grafica della loro crescita / valutazione / distribuzione del prodotto. Perciò, la scienza dei dati è in forte espansione al giorno d'oggi e R è uno di quei linguaggi che offre flessibilità nella stampa e nella grafica, in quanto ha funzioni e pacchetti specifici per tali compiti. RStudio è un software in cui dati e visualizzazione avvengono fianco a fianco, il che lo rende molto favorevole per un analista di dati. Diagrammi a dispersione, box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati...., grafici a barre, grafici a linee, grafici a linee, mappe di calore, ecc. sono possibili in R con una semplice funzione, ad esempio: l'istogramma può essere tracciato usando la funzione hist (nome dei dati) insieme a parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... Mi piace xlab (x tag), colore, dovrebbe, eccetera.
Approfittando di questa comodità, Passiamo ad un metodo di Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso...: raggruppamento.
Apprendimento supervisionato e non supervisionato
Ci sono due tipi di apprendimento nell'analisi dei dati: apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... e senza supervisione.
Apprendimento supervisionato – I dati taggati sono un input per la macchina per l'apprendimento. Regressione, la classificazione, alberi decisionali, eccetera. sono metodi di apprendimento supervisionato.
Esempio di apprendimento supervisionato:
La regressione lineare è dove ce n'è solo uno variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dipendente. Equazione: y = mx + C, y dipende da x.
Ad esempio: l'età e la circonferenza di un albero sono le 2 etichette come set di dati di input, la macchina deve prevedere l'età di un albero con una circonferenza come input dopo aver conosciuto il set di dati che è stato alimentato. L'età dipende dalla circonferenza.
Perciò, l'apprendimento è monitorato in base ai tag.
Apprendimento non supervisionato – I dati senza etichetta vengono inviati alla macchina per trovare un motivo da solo. Il clustering è un metodo di apprendimento non supervisionato che ha modelli: KMezzi, raggruppamento gerarchico, DBSCAN, eccetera.
La rappresentazione visiva dei cluster mostra i dati in un formato facilmente comprensibile, poiché raggruppa elementi di un ampio set di dati in base alle loro somiglianze. Questo rende l'analisi più facile. tuttavia, l'apprendimento non supervisionato non è sempre accurato ed è un processo complesso per la macchina, poiché i dati non sono etichettati.
Continuiamo ora con un esempio di raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. utilizzando il set di dati del fiore di Iris.
Raggruppamento
cluster sono un insieme degli stessi elementi o elementi come un grappolo di stelle o un grappolo d'uva o un grappolo di reti e così via …
Utilizzo del clustering nel mondo reale:
Viene utilizzato nei siti di e-commerce per formare gruppi di clienti in base al loro profilo come l'età, sesso, spendere, regolarità, eccetera. È utile nel marketing e nelle vendite, in quanto aiuta a raggruppare il pubblico di destinazione del prodotto. Il filtraggio dello spam nelle e-mail e molti altri sono applicazioni di clustering del mondo reale.
Il clustering in R si riferisce all'assimilazione dello stesso tipo di dati in gruppi o cluster per distinguere un gruppo dagli altri. (raccolta dello stesso tipo di dati). Questo può essere rappresentato in formato grafico tramite R. Usiamo il modello KMeans in questo processo.
Cos'è l'algoritmo K significa??
K Means è un algoritmo di clustering che assegna ripetutamente un gruppo tra i k gruppi presenti a un punto dati in base alle caratteristiche del punto. È un metodo di raggruppamento basato sui centroidi.
Il numero di cluster è deciso, i centri cluster sono selezionati casualmente più lontani l'uno dall'altro, la distanza tra ciascun punto dati e il centro è calcolata utilizzando la distanza euclidea, il punto dati è assegnato al cluster il cui centro è più vicino a quel punto. Questo processo viene ripetuto finché il centro dei gruppi non cambia e i punti dati rimangono nello stesso gruppo..
Questa è tutta teoria, ma in pratica, R ha un pacchetto di bundle che calcola i passaggi precedenti.
passo 1
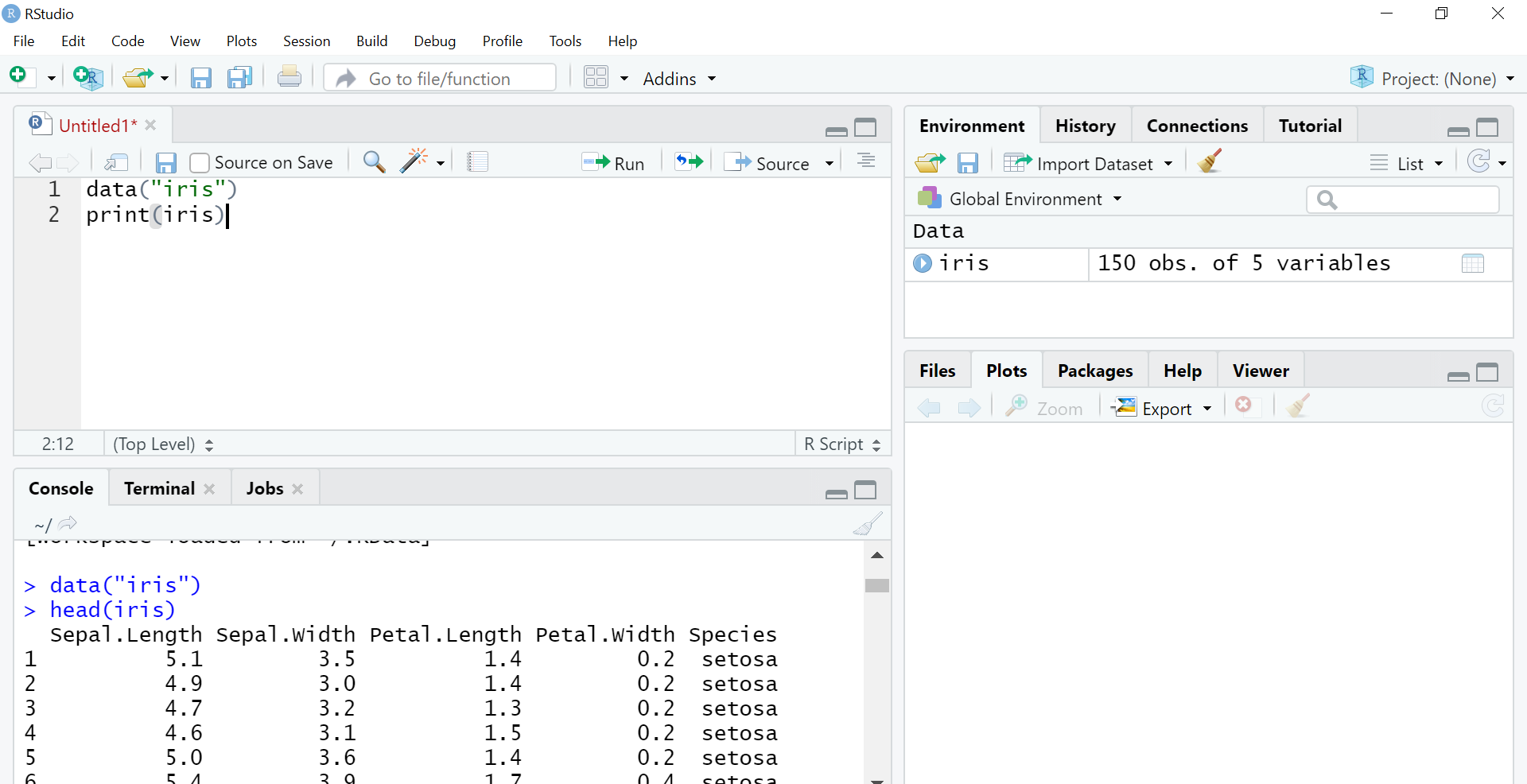
Lavorerò sul set di dati Iris, che è un set di dati integrato in R che utilizza il pacchetto Cluster. Ho 5 colonne, vale a dire: lunghezza del sepalo, larghezza del sepalo, lunghezza del petalo, larghezza e specie del petalo. Iris è un fiore e qui in questo dataset sono citati 3 della sua specie Setosa, versicolor, Verginica. Raggrupperemo i fiori in base alla loro specie. Il codice per caricare il set di dati:
dati("iris")
testa(iris) #mostrerà in alto 6 solo righe

passo 2
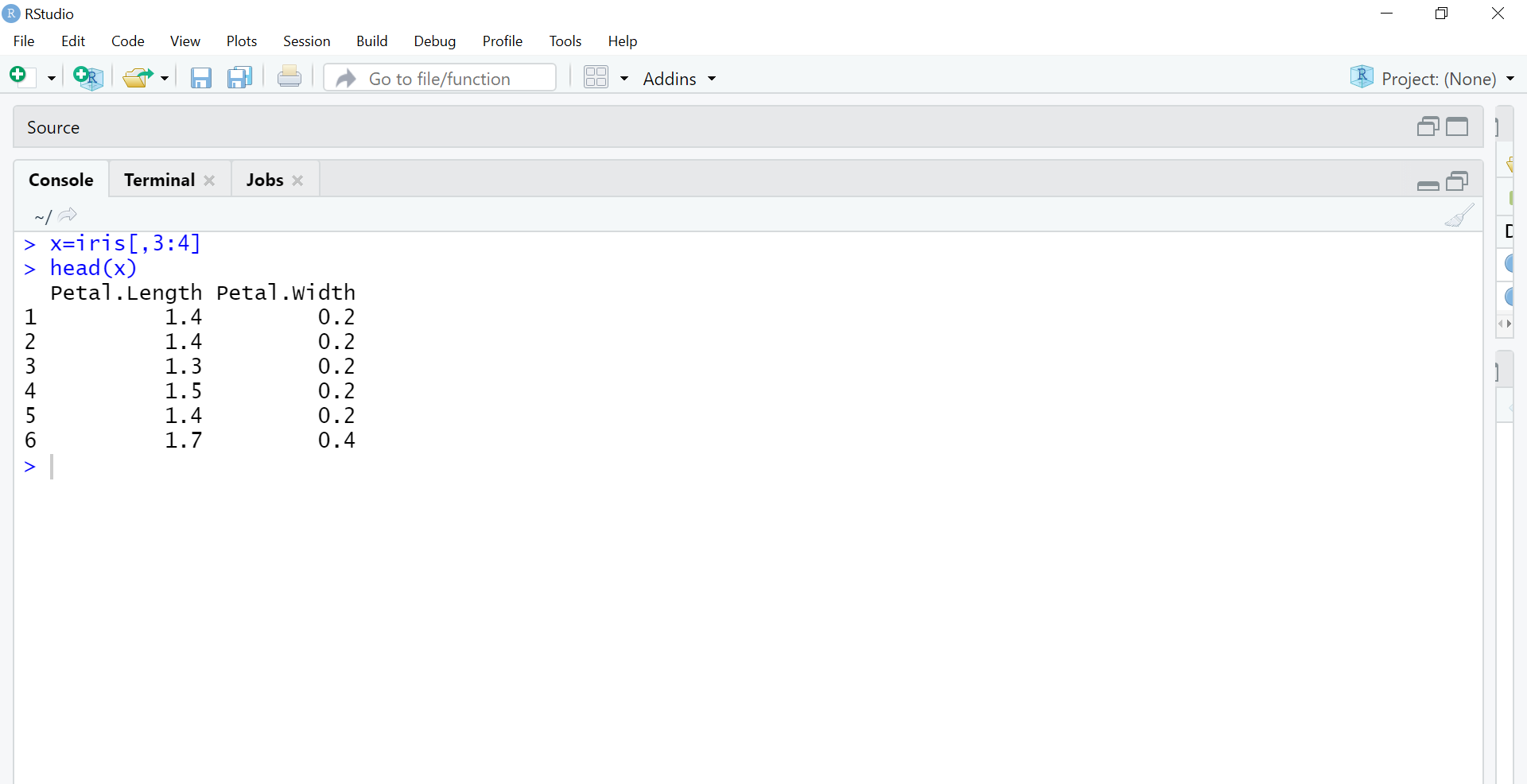
Il prossimo passo è separare le colonne 3 e 4 in un oggetto x separato, poiché stiamo usando il metodo di apprendimento non supervisionato. Stiamo rimuovendo le etichette per consentire alla macchina di utilizzare l'enorme input delle colonne di lunghezza e larghezza del petalo per il raggruppamento non presidiato.
x = iride[,3:4] #utilizzando solo le colonne di lunghezza e larghezza del petalo testa(X)
passo 3
Il prossimo passo è usare l'algoritmo K Means. K Means è il metodo che usiamo che ha parametri (dati, no. Dai cluster ai gruppi). Qui i nostri dati sono l'oggetto x e avremo k = 3 gruppi, visto che ci sono 3 specie nel set di dati.
Così lui ‘pacchetto cluster è chiamato. Il clustering in R viene eseguito utilizzando questo pacchetto integrato che farà tutta la matematica. La funzione Clusplot crea un grafico 2D dei cluster.
modello=ksignifica(X,3) biblioteca(grappolo) clusplot(X,modello$cluster)
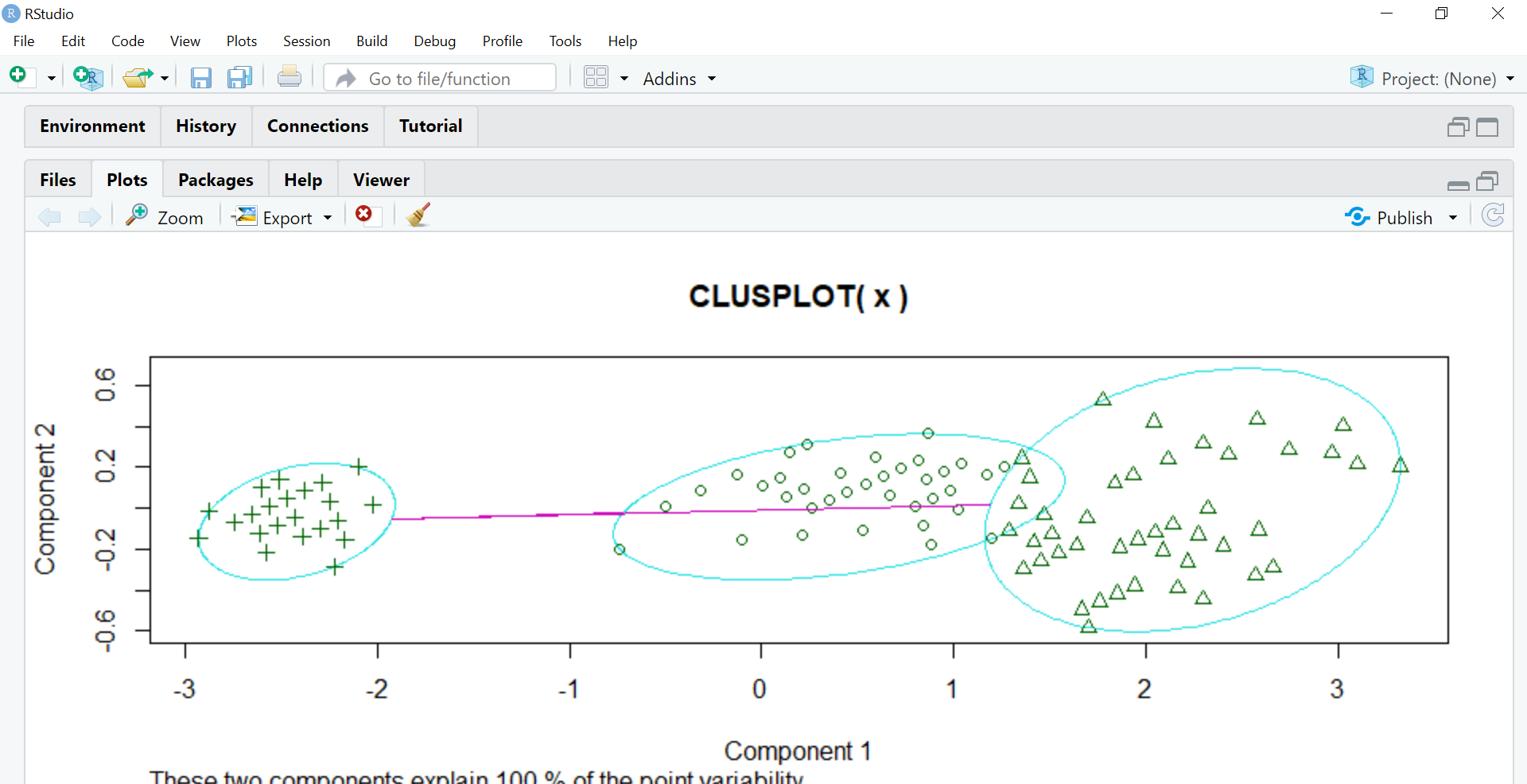
Il componente 1 e il componente 2 visti nel grafico sono i due componenti di PCA (analisi del componente principale), che è fondamentalmente un metodo di estrazione delle caratteristiche che utilizza i componenti importanti e rimuove il resto. Riduce la dimensionalità dei dati per facilitare l'applicazione di KMeans. Tutto questo viene fatto dal grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... un R.
Queste due componenti spiegano la variabilità del 100% all'uscita, il che significa che l'oggetto dati x inviato a PCA era abbastanza accurato da formare gruppi chiari usando KMeans e c'è una sovrapposizione minima (insignificante) tra loro.
passo 4
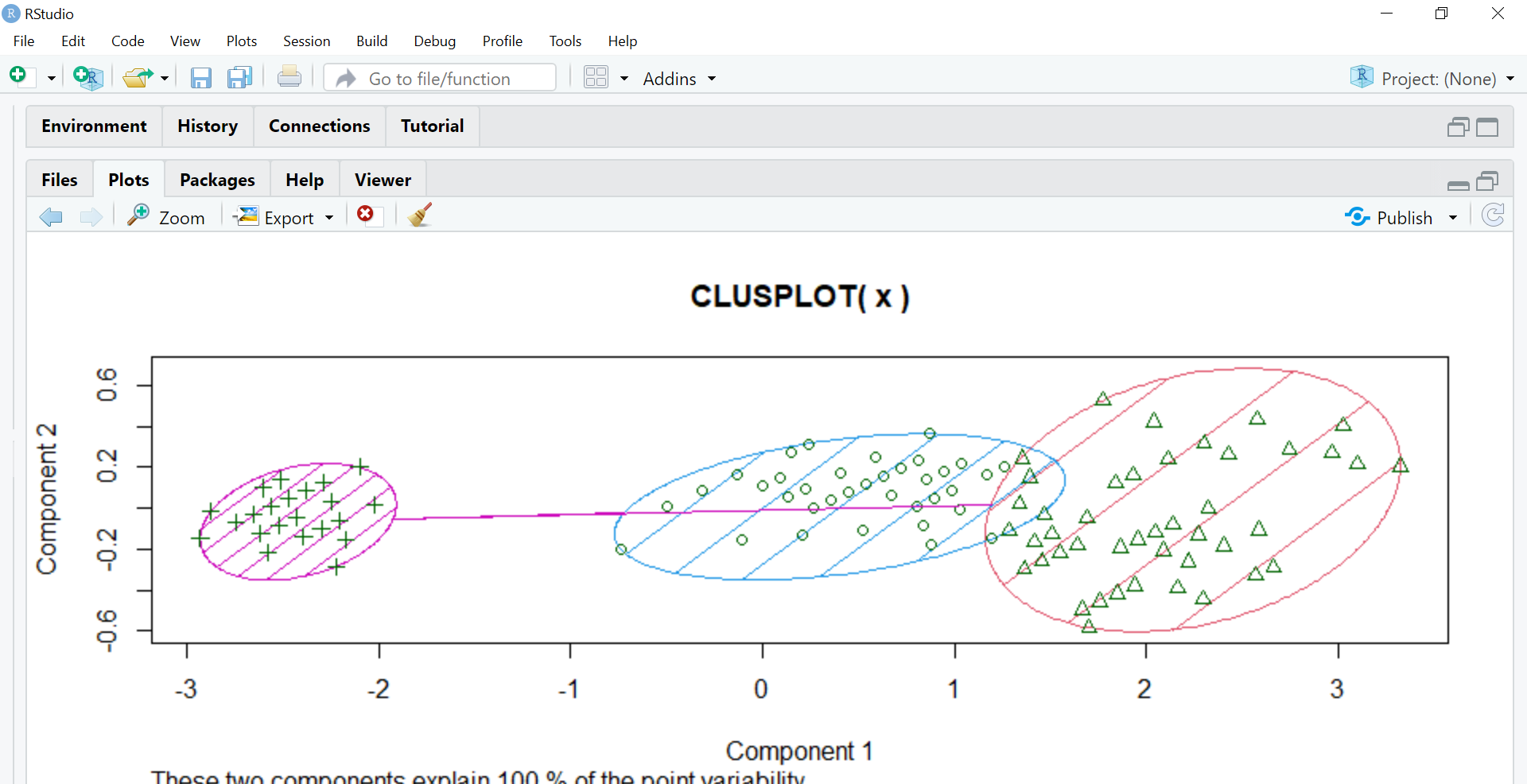
Il prossimo passo è assegnare colori diversi ai gruppi e sfumarli, così, usiamo i parametri colore e ombra impostandoli su T, cosa significa vero?.
clusplot(X,modello$cluster,colore=T,ombra=T)
conclusione
Tutto questo riassume le basi del clustering in R. Qui uso un set di dati integrato, ma i set di dati importati possono essere utilizzati anche per il clustering. Ad esempio: raggruppare gli utenti di un sito in base agli elementi preferiti, eccetera. È molto utile per fare confronti commerciali.
Importa set di dati in R:
set di dati <- leggi.csv("percorso.csv")
Visualizzazione(set di dati)
allegare(set di dati)
Grazie per aver dedicato del tempo e aver letto questo articolo.,Sentiti libero di commentare cosa può essere migliorato, poiché l'apprendimento è un processo quotidiano.dopotutti..
Collegareinsieme amesuLinkedIn:https://www.linkedin.com/in/akansha-bose-149b14164/
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





