introduzione
L'intelligenza artificiale e l'apprendimento automatico saranno il nostro più grande aiuto nel prossimo decennio!!
Oggi al mattino, Stavo leggendo un articolo che riportava che un sistema di intelligenza artificiale ha vinto contro 20 avvocati e avvocati sono stati davvero contenti che l'intelligenza artificiale possa prendersi cura di una parte ripetitiva dei loro ruoli e aiutarli a lavorare su questioni complesse. Questi avvocati erano contenti che l'intelligenza artificiale permettesse loro di svolgere ruoli più soddisfacenti.
Oggi, Condividerò un esempio simile: come contare il numero di persone in una folla usando Apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... e visione industriale? Ma, prima di farlo, sviluppiamo un senso di quanto sia facile la vita per uno scienziato che conta la folla.
Agisci come uno scienziato che conta la folla
Cominciamo!
Puoi aiutarmi a contare? / stimare il numero di persone in questa immagine che parteciperanno a questo evento?

Ok, che dire di questo?

Fonte: Set di dati ShanghaiTech
Ci prendi la mano. Alla fine di questo tutorial, creeremo un algoritmo per il conteggio della folla con una precisione sorprendente (rispetto agli umani come te e me). Userai un tale assistente??
PD Questo articolo presuppone che tu abbia una conoscenza di base del funzionamento delle reti neurali convoluzionali. (CNN). È possibile fare riferimento al post di seguito per ulteriori informazioni su questo argomento prima di procedere.:
Sommario
- Cosa conta la folla??
- Perché è necessario il conteggio della folla??
- Comprensione delle diverse tecniche di visione artificiale per il conteggio della folla
- Architettura CSRNet e metodi di formazione
- Costruire il proprio modello di conteggio della folla in Python
Questo articolo è molto ispirato dall'articolo: CSRNet: Reti neurali convoluzionali dilatate per comprendere scene altamente congestionate.
Cosa conta la folla??
Il conteggio della folla è una tecnica per contare o stimare il numero di persone in un'immagine. Prenditi un momento per analizzare l'immagine seguente:
Fonte: Set di dati ShanghaiTech
Puoi darmi un numero approssimativo di quante persone ci sono nella scatola?? sì, compresi quelli presenti in sottofondo. Il metodo più diretto è contare manualmente ogni persona, ma ha senso pratico?? È quasi impossibile quando la folla è così numerosa!
Gli scienziati della folla (sì, Questo è un vero titolo di lavoro!) Contano il numero di persone in determinate parti di un'immagine e poi estrapolano per arrivare a una stima. Più comunemente, abbiamo dovuto fare affidamento su metriche grezze per stimare questo numero per decenni.
Sicuramente ci deve essere un approccio migliore e più accurato.
si ci sono!
Anche se non abbiamo ancora algoritmi che possano darci il numero ESATTO, la maggioranza visione computerizzata Le tecniche possono produrre stime straordinariamente accurate. Per prima cosa capiamo perché il conteggio della folla è importante prima di immergerci nell'algoritmo che sta dietro..
Perché il conteggio della folla è utile??
Capiamo l'utilità del conteggio delle folle con un esempio. Immagina questo: la tua azienda ha appena terminato di ospitare una conferenza sulla scienza dei big data. Durante l'evento si sono svolte molte sessioni differenti.
Ti viene chiesto di analizzare e stimare il numero di persone che hanno partecipato a ciascuno sessioneIl "Sessione" È un concetto chiave nel campo della psicologia e della terapia. Si riferisce a un incontro programmato tra un terapeuta e un cliente, dove si esplorano i pensieri, Emozioni e comportamenti. Queste sessioni possono variare in durata e frequenza, e il suo scopo principale è quello di facilitare la crescita personale e la risoluzione dei problemi. L'efficacia delle sessioni dipende dalla relazione tra il terapeuta e il terapeuta... Questo aiuterà il tuo team a capire quali tipi di sessioni hanno attirato le folle più grandi. (e quali hanno fallito in quel senso). Questo darà forma alla conferenza del prossimo anno, Quindi è un compito importante!

C'erano centinaia di persone all'evento, Contarli manualmente richiederà giorni! È qui che entrano in gioco le tue capacità di data scientist.. È riuscito a ottenere foto della folla ad ogni scatto e a creare un modello di visione artificiale per fare il resto!!
Esistono molti altri scenari in cui gli algoritmi di conteggio della folla stanno cambiando il modo in cui lavorano le industrie.:
- Contare il numero di persone che partecipano a un evento sportivo
- Stima quante persone hanno partecipato a un'inaugurazione o a una marcia (manifestazioni politiche, può essere)
- Monitoraggio di aree ad alto traffico
- Aiutare con il personale e l'allocazione delle risorse.
Ti vengono in mente altri casi d'uso?? Fatemi sapere nella sezione commenti qui sotto!! Possiamo connetterci e cercare di capire come possiamo usare le tecniche di conteggio della folla sul tuo palco..
Comprensione delle diverse tecniche di visione artificiale per il conteggio della folla
In termini generali, ci sono attualmente quattro metodi che possiamo usare per contare il numero di persone in una folla:
1. Metodi basati sul rilevamento
Qui, usiamo un rilevatore mobile simile a una finestra per identificare le persone in un'immagine e contare quante ce ne sono. I metodi utilizzati per il rilevamento richiedono classificatori ben addestrati in grado di estrarre caratteristiche di basso livello. Sebbene questi metodi funzionino bene per rilevare i volti, non funzionano bene nelle immagini affollate, poiché la maggior parte degli oggetti target non sono chiaramente visibili.
2. Metodi basati sulla regressione
Non siamo stati in grado di estrarre funzionalità di basso livello con l'approccio di cui sopra. I metodi basati sulla regressione trionfano qui. Per prima cosa tagliamo le patch dall'immagine e poi, per ogni patch, estraiamo le caratteristiche di basso livello.
3. Metodi basati sulla stima della densità
Per prima cosa creiamo una mappa di densità per gli oggetti. Dopo, l'algoritmo apprende una mappatura lineare tra le caratteristiche estratte e le loro mappe di densità dell'oggetto. Possiamo anche usare la regressione casuale della foresta per imparare la mappatura non lineare.
4. Metodi basati sulla CNN
Ah, reti neurali convoluzionali buone e affidabili (CNN). Invece di guardare le macchie di un'immagine, creiamo un metodo di regressione end-to-end utilizzando la CNN. Questo prende l'intera immagine come input e produce direttamente il conteggio delle persone. Le CNN funzionano alla grande con attività di regressione o classificazione, e hanno anche dimostrato il loro valore nella generazione di mappe di densità.
CSRNet, una tecnica che implementeremo in questo articolo, implementa una CNN più profonda per acquisire funzionalità di alto livello e generare mappe di densità di alta qualità senza espandere la complessità della rete. Capiamo cos'è CSRNet prima di passare alla sezione di codifica.
Comprendere l'architettura CSRNet e il metodo di formazione
CSRNet utilizza VGG-16 come interfaccia grazie alle sue elevate capacità di apprendimento del trasferimento. La dimensione dell'output VGG è un quinto della dimensione dell'input originale. CSRNet utilizza anche strati convolutivi dilatati sul retro.
Ma, Che diavolo sono le circonvoluzioni dilatate?? È una domanda giusta. Considera la seguente immagine:
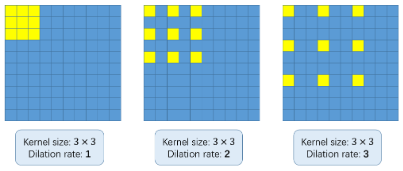
Il concetto di base dell'uso delle convoluzioni dilatate è quello di ingrandire il kernel senza aumentare il parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto..... Quindi, se il tasso di dilatazione è 1, prendiamo il kernel e lo convertiamo nell'intera immagine. Mentre, se aumentiamo il tasso di dilatazione a 2, il nucleo si estende come mostrato nell'immagine sopra (segui le etichette sotto ogni immagine). Può essere un'alternativa al raggruppamento di livelli.
Matematica di base (consigliato, ma opzionale)
Mi prendo un momento per spiegare come funziona la matematica. Nota che questo non è obbligatorio per implementare l'algoritmo in Python, ma ti consiglio di imparare l'idea di fondo. Questo sarà utile quando è necessario regolare o modificare il modello..
Supponiamo di avere un input x (m, n), un filtro w (io, J) e la velocità di dilatazione r. L'uscita e (m, n) sarà:
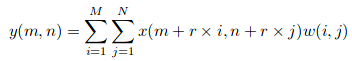
Possiamo generalizzare questa equazione usando un kernel (K * K) con un tasso di dilatazione r. Il nucleo si allarga a:
([K + (k-1)*(r-1)] * [K + (k-1)*(r-1)])
Quindi la verità di base è stata generata per ogni immagine. La testa di ogni persona in una data immagine è sfocata usando un kernel gaussiano. Tutte le immagini sono ritagliate a 9 patch e la dimensione di ogni patch è un quarto della dimensione dell'immagine originale. Con me fino ad ora?
Il primo 4 le patch sono divise in 4 stanze e le altre 5 le patch vengono ritagliate a caso. Finalmente, Lo specchio di ogni patch viene preso per duplicare l'insieme di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
Quella, in poche parole, sono i dettagli dell'architettura dietro CSRNet. Prossimo, vedremo i dettagli del tuo allenamento, inclusa la metrica di valutazione utilizzata.
Il declino dei gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... Lo stocastico viene utilizzato per addestrare CSRNet come struttura end-to-end. Durante l'allenamento, il tasso di apprendimento fisso è impostato su 1e-6. Il Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... Viene presa come distanza euclidea per misurare la differenza tra la verità del terreno e la mappa della densità stimata. Questo è rappresentato come:
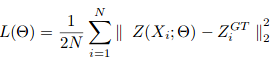
dove N è la dimensione del batch di addestramento. La metrica di valutazione utilizzata in CSRNet è MAE e MSE, vale a dire, errore medio assoluto ed errore quadratico medio. Questi sono dati da:
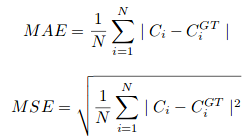
Qui, Ci è il conteggio stimato:
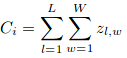
L e W sono la larghezza della mappa di densità prevista.
Il nostro modello prevede prima la mappa della densità per una data immagine. Il valore in pixel sarà 0 se non c'è nessuna persona presente. Verrà assegnato un determinato valore preimpostato se quel pixel corrisponde a una persona. Quindi, calcolare i valori di pixel totali corrispondenti a una persona ci darà il conteggio delle persone in quell'immagine. Degno di nota, verità?
E adesso, Signore e signori, È ora di costruire finalmente il nostro modello di conteggio delle folle!!
Costruire il proprio modello di conteggio della folla
Pronto con il tuo laptop acceso?
Implementeremo CSRNet nel dataset ShanghaiTech. Questo contiene 1198 immagini annotate da un totale combinato di 330,165 persone. Puoi scaricare il set di dati da qui.
Usa il seguente blocco di codice per clonare il repository CSRNet-pytorch. Contiene tutto il codice per creare il set di dati, addestrare il modello e convalidare i risultati:
git clone https://github.com/leeyeehoo/CSRNet-pytorch.git
Si prega di installare MIRACOLI e PyTorch prima di continuare. Queste sono la spina dorsale dietro il codice che useremo in seguito.
Ora, sposta il set di dati nel repository che hai clonato in precedenza e decomprimilo. Dopo, avremo bisogno di creare i valori di verità di base. il make_dataset.ipynb il file è il nostro salvatore. Abbiamo solo bisogno di apportare piccole modifiche a quel taccuino:
#mettere la radice alla Shanghai set di datiun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi.... che hai scaricato
# cambia il percorso radice in base alla posizione del set di dati
radice="/home/pulkit/CSRNet-pytorch/"
Ora, generiamo i valori reali di base per le immagini in parte_A e parte_B:
La generazione della mappa della densità per ogni immagine è un passaggio temporale. Quindi prepara una tazza di caffè mentre il codice viene eseguito.
Fino ad ora, abbiamo generato i valori di verità di base per le immagini in part_A. Faremo lo stesso con le immagini part_B. Ma prima di questo, Diamo un'occhiata a un'immagine di esempio e tracciamo la sua mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... reale da terra:
plt.imshow(Immagine.apri(img_paths[0]))
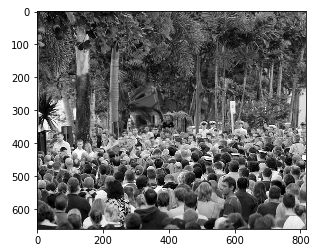
Le cose si stanno facendo interessanti!
gt_file = h5py.File(img_paths[0].sostituire('.jpg','.h5').sostituire('immagini','realtà di base'),'R')
groundtruth = np.asarray(gt_file['densità'])
plt.imshow(realtà di base,cmap=CM.jet)
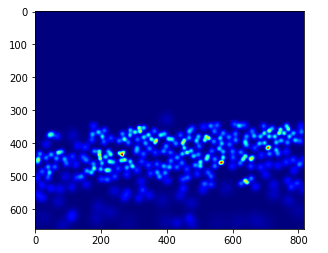
Contiamo quante persone sono presenti in questa immagine:
np.sum(realtà di base)
270.32568
Nello stesso modo, genereremo i valori per part_B:
Ora, abbiamo le immagini, così come i loro corrispondenti valori di verità fondamentali. È ora di addestrare il nostro modello!
Useremo i file .json disponibili nella directory clonata. Abbiamo solo bisogno di cambiare la posizione delle immagini nei file jsonJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software... Per fare questo, apri il file .json e sostituisci la posizione corrente con la posizione in cui si trovano le tue immagini.
Nota che tutto questo codice è scritto in Python 2. Apportare le seguenti modifiche se si utilizza un'altra versione di Python:
- In model.py, cambia xrange sulla linea 18 una gamma
- Cambia la linea 19 in model.py con: elenco (self.frontend.state_dict (). Elementi ())[io][1].dati[:] = elenco (mod.state_dict (). Oggetti ())[io][1].dati[:]
- In image.py, sostituire ground_truth con la verità di base
Hai apportato le modifiche?? Ora, Aprire una nuova finestra del terminale e digitare i seguenti comandi:
cd CSRNet-pytorch
python train.py part_A_train.json part_A_val.json 0 0
Ancora, siediti perché ci vorrà del tempo. Può ridurre il numero di epoche nel train.py per velocizzare il processo. Una buona opzione alternativa è scaricare i pesi pre-allenati. da qui se non hai voglia di aspettare.
Finalmente, verifichiamo le prestazioni del nostro modello in dati invisibili. Useremo il val.ipynb per convalidare i risultati. Ricordati di cambiare il percorso con pesi e immagini precedentemente allenati.
#defining the image path
img_paths = []
per percorso in path_sets:
per img_path in glob.glob(os.path.join(il percorso, '*.jpg')):
img_paths.append(img_path)
modello = CSRNet()
#defining the model
model = model.cuda()
#loading the trained weights
checkpoint = torch.load('part_A/0model_best.pth.tar')
model.load_state_dict(posto di blocco['state_dict'])
Controlla il MAE (errore assoluto medio) nelle immagini di prova per valutare il nostro modello:
Abbiamo un valore MAE di 75,69, che è abbastanza buono. Ora esaminiamo le previsioni in un'unica immagine:
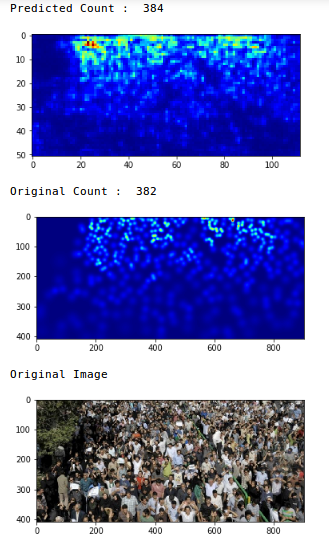 Andare, il conteggio originale era 382 e il nostro modello ha stimato che c'era 384 persone nella foto. Questa è una performance davvero impressionante!!
Andare, il conteggio originale era 382 e il nostro modello ha stimato che c'era 384 persone nella foto. Questa è una performance davvero impressionante!!
Congratulazioni per aver creato il tuo modello di conteggio delle folle!!
Note finali
Ti incoraggio a provare questo approccio su diverse immagini e a condividere i tuoi risultati nella sezione commenti qui sotto.. Il conteggio della folla ha molte applicazioni diverse ed è già adottato da organizzazioni e agenzie governative..
È un'abilità utile da aggiungere al tuo portfolio. Un gran numero di industrie cercherà data scientist in grado di lavorare con algoritmi di conteggio della folla. Imparare, sperimentalo e concediti il dono dell'apprendimento profondo!
Hai trovato questo articolo utile? Sentiti libero di lasciarmi i tuoi suggerimenti e commenti qui sotto, e sarò felice di comunicare con te.
Dovresti anche controllare le risorse qui sotto per imparare ed esplorare il meraviglioso mondo della visione artificiale.:





