Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Ciao! Oggi farò del mio meglio per spiegare intuitivamente come funzionano le reti neurali convoluzionali ricorrenti (CRNN). Quando ho provato per la prima volta a conoscere come funziona CRNN, Ho scoperto che le informazioni erano suddivise su più siti e che diversi livelli di “profondità”, quindi cercherò di spiegarli in modo tale che entro la fine di questo articolo saprò esattamente come funzionano e perché si comportano meglio in alcune categorie rispetto ad altre.
In questo articolo, asumiré que ya sabe un poco sobre cómo funciona una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. semplice. Nel caso tu abbia bisogno di una piccola revisione di come funziona o anche se non sai come funzionano affatto, Vi consiglio di guardare i video ben fatti che spiegano come funzionano che ho linkato alla fine dell'articolo. Fornirò tutte le informazioni che ritieni necessarie per capire intuitivamente come funziona CRNN.
In questo articolo tratteremo i seguenti argomenti, quindi sentiti libero di saltare quelli che già conosci:
- Cosa sono le reti neurali convoluzionali, come funzionano e perché ne abbiamo bisogno?
- Cosa sono le reti neurali ricorrenti, come funzionano e perché ne abbiamo bisogno?
- · Cosa sono e perché abbiamo bisogno di reti neurali ricorrenti convoluzionali? + esempio di riconoscimento del testo scritto a mano
- · Altre letture e link
Cosa sono le reti neurali convoluzionali, come funzionano e perché ne abbiamo bisogno?
La risposta più semplice è l'ultima domanda, Perché abbiamo bisogno di loro?? Per quello, facciamo un esempio. Diciamo che vogliamo scoprire se abbiamo un gatto o un cane nell'immagine. Per semplificare la spiegazione, Pensiamo prima a un'immagine di 3 × 3. In questa immagine, abbiamo una caratteristica importante nel rettangolo blu (come la faccia di un cane, una lettera o qualunque sia la caratteristica importante).
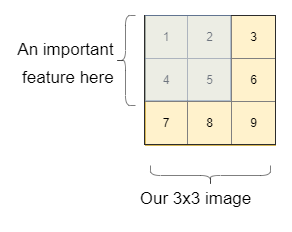
Vediamo come una semplice rete neurale riconoscerebbe l'importanza e il collegamento tra i pixel.
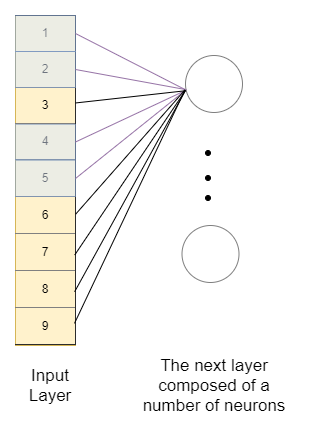
Come possiamo vedere, avremo bisogno “planare” l'immagine per alimentarla a una fitta rete neurale. Così facendo, perdiamo il contesto spaziale nell'immagine della caratteristica completa con lo sfondo e anche i pezzi della caratteristica l'un l'altro. Immagina quanto sarà difficile per la rete neurale imparare che sono correlati. Cosa c'è di più, avremo tanti pesi da allenare, quindi avremo bisogno di più dati e, così, più tempo per allenarli.
Quindi, possiamo vedere più problemi con questo approccio:
- Il contesto spaziale è perso
- Molto più peso per immagini più grandi
- Più pesi comportano più tempo e più dati necessari
Solo se ci fosse un altro modo... Aspetta!! Ci sono! È qui che entrano in gioco le reti neurali convoluzionali per salvare la situazione.. La sua funzione principale è estrarre le caratteristiche rilevanti dall'input (un'immagine, ad esempio) usando i filtri. Questi filtri vengono prima scelti a caso e poi addestrati come fanno i pesi.. Vengono modificati dalla Rete Neurale per estrarre e trovare le caratteristiche più rilevanti.
Concordare, abbiamo finora stabilito che le reti neurali convoluzionali, cosa userò come CNN?, usa i filtri per estrarre le caratteristiche. Ma, Cosa sono esattamente i filtri e come funzionano?
I filtri sono array contenenti diversi valori che scorrono sull'immagine (ad esempio) per analizzare le caratteristiche. Se la matrice è, ad esempio, 3x3x3, la caratteristica estratta sarà di dimensioni 3x3x3. Se la matrice è di dimensioni 5 × 5, la caratteristica che rileverà avrà una dimensione massima di 5 × 5 nell'immagine, e così via. Quando si analizza una finestra di pixel, comprendiamo la moltiplicazione per elementi tra il filtro e la finestra coperta.
Quindi, ad esempio, se abbiamo un'immagine con una dimensione di 6 × 6 e un filtro 3 × 3, possiamo immaginare il filtro che scorre sull'immagine, e ogni volta che atterra in una nuova finestra, le analisi, quello che possiamo vedere rappresentato nell'immagine qui sotto, solo per le prime due righe dell'immagine:
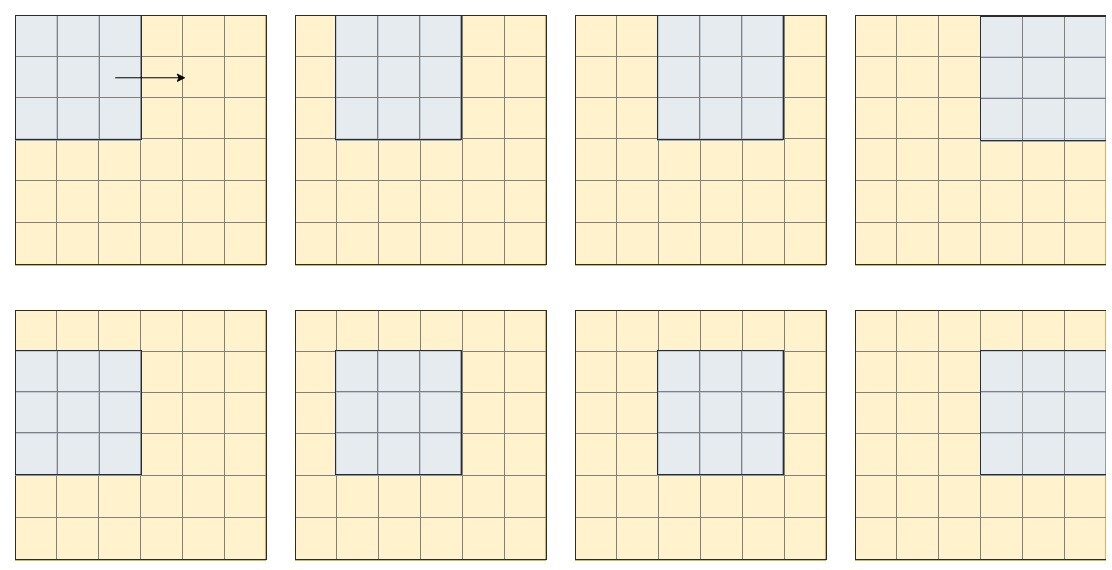
A seconda di cosa dobbiamo estrarre, possiamo cambiare il passaggio del filtro (sia in verticale che in orizzontale, nell'esempio sopra, il filtro fa un passo in entrambe le direzioni).
Dopo aver fatto la moltiplicazione (per elementi), il risultato diventa il nuovo pixel dell'immagine. Quindi, dopo “analizzare” la prima finestra, otteniamo il primo pixel della nostra immagine, e così via. Vediamo che nel caso presentato sopra, l'immagine finale avrà una dimensione di 5 × 5. Per avere l'immagine finale con le stesse dimensioni, possiamo applicare i filtri dopo aver riempito con fantasia l'immagine (aggiungendo una riga e una colonna immaginarie all'inizio e alla fine), ma i dettagli sono per un'altra volta da discutere.
Per vedere ancora meglio come funziona la convoluzione, possiamo vedere esempi di filtri e l'effetto che provocano sull'immagine di output:

Possiamo vedere come i diversi filtri rilevano e “loro estraggono” caratteristiche diverse. La funzione dell'addestramento di una rete neurale di convoluzione è trovare i filtri migliori per estrarre la caratteristica più rilevante per il nostro compito..
Quindi, per concludere la parte sulle reti neurali di convoluzione, possiamo riassumere le informazioni in 3 idee semplici:
- Quali sono: Le reti neurali convoluzionali sono un tipo di reti neurali che utilizzano l'operazione di convoluzione (facendo scorrere un filtro su un'immagine) per estrarre le caratteristiche rilevanti.
- Perché abbiamo bisogno di loro?: lavorare meglio sui dati (invece di usare le normali reti neurali dense) in cui esiste una forte correlazione tra, ad esempio, pixel perché il contesto spaziale non si perde.
- Come funzionano: usa i filtri per estrarre le caratteristiche. I filtri sono matrici che "scivolano" sull'immagine. Vengono modificati nel periodo di formazione per estrarne le caratteristiche più rilevanti.
Cosa sono le reti neurali ricorrenti, come funzionano e perché ne abbiamo bisogno?
Mentre le reti neurali convoluzionali ci aiutano a estrarre le caratteristiche rilevanti nell'immagine, Le reti neurali ricorrenti aiutano la rete neurale a prendere in considerazione le informazioni del passato per fare previsioni o analizzare.
Perciò, se abbiamo, ad esempio, la seguente matrice: {2, 4, 6}, e vogliamo prevedere cosa verrà dopo, podemos usar una Ricorrente neuronale rossoReti neurali ricorrenti (RNN) sono un tipo di architettura di rete neurale progettata per elaborare flussi di dati. A differenza delle reti neurali tradizionali, Le RNN utilizzano connessioni interne che consentono di ricordare le informazioni delle voci precedenti. Questo li rende particolarmente utili in attività come l'elaborazione del linguaggio naturale, Traduzione automatica e analisi di serie storiche, dove il contesto e la sequenza sono centrali per il..., perché, in ogni passo, prenderà in considerazione quello che c'era prima.
Possiamo visualizzare una semplice cella ricorrente, come mostrato nell'immagine seguente:
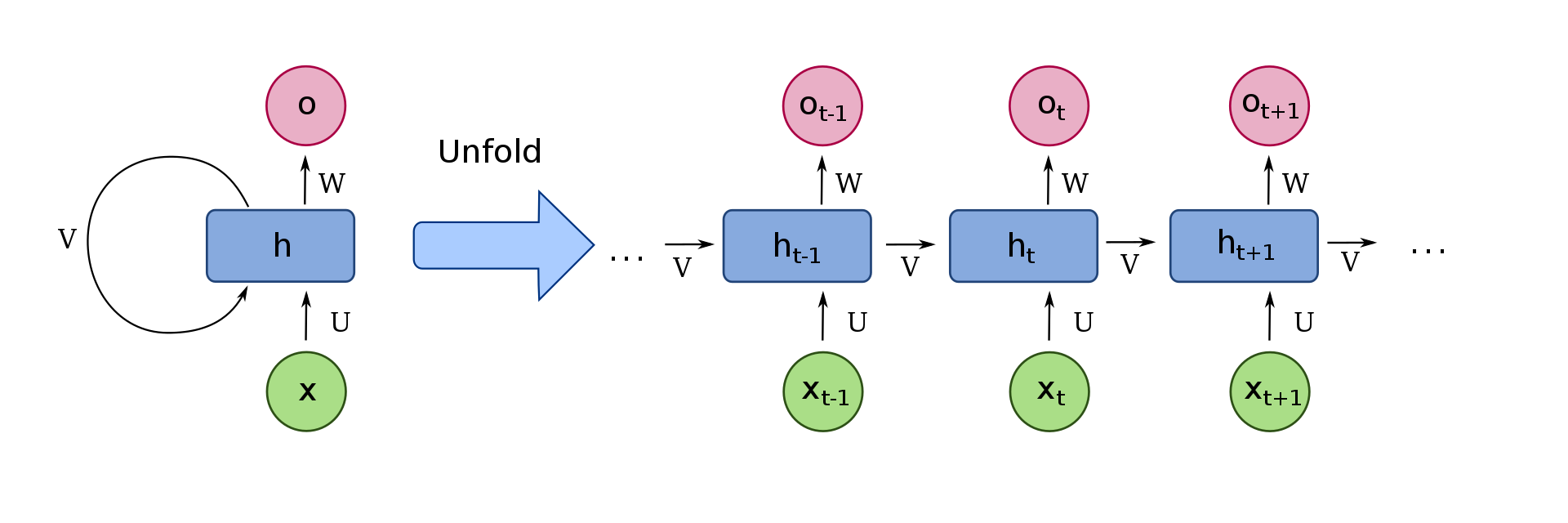
Primo, concentriamoci solo sul lato destro dell'immagine. Qui, XT sono gli ingressi ricevuti nel passo temporale t. Per seguire lo stesso esempio, questi potrebbero essere i numeri della matrice di cui sopra, X0 = 2, X1 = 4, X2 = 6. Per prendere in considerazione ciò che era prima del passare del tempo, la proprietà che li rende parte di una Rete Neurale Ricorrente, dobbiamo ricevere informazioni dal passaggio temporale precedente, che in questa immagine abbiamo rappresentato come v Ogni cella ha una chiamata “stato”, che contiene intuitivamente le informazioni che vengono poi inviate alla cella successiva.
Quindi, ricapitolare, XT è la voce della cella. Dopo, la cellula decide quali sono le informazioni importanti, tenendo conto delle informazioni delle fasi temporali precedenti, ricevuto attraverso la "v", e invialo alla cella successiva. Cosa c'è di più, abbiamo la possibilità se vogliamo restituire questa importante informazione che la cella ha considerato, tramite la “oh” nell'immagine, uscita della cella.
Per rappresentare il suddetto processo in modo più compatto, noi possiamo “piegare” le cellule, rappresentato sul lato sinistro dell'immagine.
Non entreremo nei dettagli sul tipo esatto di celle ricorrenti, poiché ci sono molte opzioni, e spiegare in dettaglio come funzionano richiederebbe troppo tempo. Se siete interessati, Ho lasciato alcuni link che ho trovato molto utili alla fine dell'articolo.
Cosa sono e perché abbiamo bisogno di reti neurali ricorrenti convoluzionali?
+ esempio di riconoscimento del testo scritto a mano
Ora abbiamo tutte le informazioni importanti per capire come funziona una rete convoluzionale ricorrente.
La maggior parte delle volte, il convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. analiza la imagen y la envía a la parte recurrente de las características importantes detectadas. La ricorrente analizza queste caratteristiche nell'ordine, tenendo conto delle informazioni precedenti per capire quali sono alcuni importanti collegamenti tra queste caratteristiche che influenzano l'output.
Per capire un po' di più su come funziona un CRNN in alcune attività, Prendiamo come esempio il riconoscimento del testo scritto a mano.
Immaginiamo di avere immagini che contengono parole e di voler addestrare la NNet a darci quale parola è inizialmente nell'immagine..
Primo, vorremmo che la nostra rete neurale fosse in grado di estrarre caratteristiche importanti per lettere diverse, come loop di “G” oh “io”, o anche cerchi di “un” tu “oh”. Per questo, possiamo usare una rete neurale convoluzionale. Come spiegato sopra, La CNN utilizza i filtri per estrarre le funzionalità importanti (abbiamo visto come filtri diversi hanno effetti diversi sull'immagine iniziale). Certo, questi filtri in pratica rileveranno caratteristiche più astratte che non possiamo davvero capire, ma intuitivamente possiamo pensare a funzionalità più semplici, come menzionato sopra.
Quindi, vorremmo analizzare queste caratteristiche. Diamo un'occhiata al motivo per cui non possiamo decidere quale lettera si basa esclusivamente sulle sue caratteristiche.. Nell'immagine qui sotto, vediamo che la lettera è "a" (da A") UO" (de per).
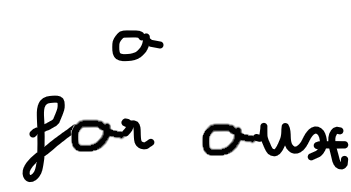
La differenza sta nel modo in cui la lettera è collegata alle altre lettere. Quindi avremmo bisogno di conoscere le informazioni dai luoghi precedenti nell'immagine per essere in grado di determinare la lettera. Suona familiare? È qui che entra in gioco la parte RNN. Analizza ricorsivamente le informazioni estratte dalla CNN, dove l'input per ogni cella potrebbe essere le caratteristiche rilevate in un segmento specifico dell'immagine, come illustrato di seguito, con solo 10 segmenti (meno di quello che useremmo nei modelli reali):
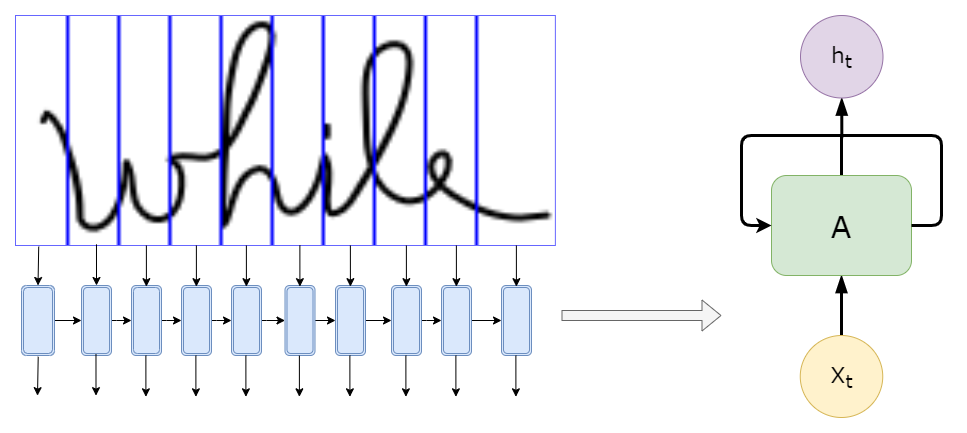
Non alimentiamo l'RNN con l'immagine stessa, come mostrato nell'immagine sopra, ma con le caratteristiche estratte da quello “segmento”.
Potremmo anche vedere che l'elaborazione dell'immagine in avanti è importante tanto quanto l'elaborazione dell'immagine all'indietro., così possiamo aggiungere uno strato di celle che elaborano le caratteristiche nell'altro modo, tenendo conto di entrambi nel calcolo dell'output. O anche in verticale, a seconda del compito da svolgere.
evviva! Finalmente abbiamo l'immagine analizzata: le caratteristiche estratte e analizzate in relazione tra loro. Tutto quello che dobbiamo fare ora è aggiungere un livello che calcola la perdita e un algoritmo che decodifica l'output, per questo, potremmo voler usare un CTC (Classificazione temporale connessionista) per il riconoscimento del testo scritto a mano, ma questo è un argomento interessante di per sé. e penso che meriti un altro articolo.
Conclusioni
In questo articolo, discutiamo brevemente come funzionano le reti neurali ricorrenti convoluzionali, come analizzano ed estraggono le funzionalità e un esempio di come potrebbero essere utilizzate.
La rete neurale convoluzionale estrae le caratteristiche applicando filtri rilevanti e la rete neurale ricorrente analizza queste caratteristiche, tenendo conto delle informazioni ricevute dalle fasi temporali precedenti.





