Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Trovi l'intelligenza artificiale e il machine learning interessanti??
Sei interessato a diventare un ingegnere di machine learning?? Hai imparato linguaggi di programmazione come Python o R, ma fa fatica ad andare avanti? (Questo accade principalmente nel caso degli autodidatti). Trovi parole come Statistiche intimidatorie?, Probabilità e regressione? È assolutamente comprensibile sentirsi così, soprattutto se vieni da un background non tecnico. Ma c'è una soluzione per questo. E questo è …. iniziare. Ricordare, se non inizia mai, non commetterai mai errori e potresti non imparare mai. Quindi inizia in piccolo.
Regressione lineare semplice
Quando usiamo LR?
Creeremo un semplice modello di apprendimento automatico utilizzando la regressione lineare. Ma prima di passare alla parte di codifica, diamo un'occhiata alle basi e alla logica che c'è dietro. La regressione viene utilizzata nell'algoritmo di apprendimento automatico supervisionato, qual'è l'algoritmo più utilizzato al momento. El análisis de regresión es un método en el que establecemos una vinculación entre una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dipendente (e) e una variabile indipendente (X); che ci permette di prevedere e prevedere i risultati. Ti ricordi di aver risolto equazioni come y = mx + c dei tuoi giorni di scuola? Se è così, Congratulazioni. Conosci già la semplice regressione lineare. Se non è così, non è affatto difficile da imparare.
Consideriamo un esempio popolare. Il numero di ore investite nello studio e i voti ottenuti all'esame. In questa circostanza, i voti ottenuti dipendono dal numero di ore che lo studente investe nello studio, perché, i voti ottenuti sono la variabile dipendente y e il numero di ore è la variabile indipendente x. L'obiettivo è sviluppare un modello che ci aiuti a prevedere i voti ottenuti per un nuovo numero di ore.. Lo otterremo usando la regressione lineare.
Per essere molto chiari su questo concetto, consideriamo un altro esempio. In un set di dati con la quantità di calorie consumate e il peso guadagnato, il peso guadagnato dipende dalle calorie consumate da una persona. Perché, il peso guadagnato è la variabile dipendente y e il numero di calorie è la variabile indipendente x.
y = mx + c è l'equazione della retta di regressione che meglio si adatta ai dati e, A volte, inoltre è rappresentato come y = b0 + B1X. Qui,
y è la variabile dipendente, in questa circostanza, i voti ottenuti.
x è la variabile indipendente, in questa circostanza, il numero di ore.
assalire1 è la pendenza della retta di regressione e il coefficiente della variabile indipendente.
c o b0 è l'intersezione della retta di regressione.
La logica è calcolare la pendenza (m) e intercettare (C) con i dati disponibili e quindi potremo calcolare il valore di y per qualsiasi valore di x.
Pacchetti e codici Python richiesti
Ora, Come eseguire la regressione lineare in Python? Dobbiamo importare alcuni pacchetti, vale a dire NumPy lavorare con le matrici, Sklearn eseguire la regressione lineare, e Matplotlib per tracciare la retta di regressione e i grafici. Nota che è quasi impossibile conoscere ogni pacchetto e libreria in Python, soprattutto per i principianti. Perché, Si consiglia di continuare a cercare il pacchetto appropriato quando necessario per un'attività. È più facile ricordare di utilizzare pacchetti con esperienza pratica coinvolta, invece di leggere semplicemente teoricamente la documentazione disponibile in essi.
Passaggio alla parte di codifica. Il primo passo è importare i pacchetti richiesti.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
Considerando che questo è il tuo primo modello di apprendimento automatico, elimineremo alcune complicazioni prelevando un campione molto piccolo, en lugar de utilizar datos de una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... grande. Questo aiuterà anche a vedere chiaramente il risultato nella grafica e ad apprezzare il concetto in modo efficace..
xpuntos = np.array ([10, 11, 12, 13, 14, 15]) .riforma (-1,1)
ypoints = np.array ([53, 52, 60, 63, 72, 70])
Notare che stiamo rimodellando il xpoints avere una colonna e molte righe. Il predittore (X) deve essere un array di array e la soluzione (e) può essere una semplice matrice.
Una variabile Linreg viene creato come istanza di Regressione lineare. Può prendere parametri che sono facoltativi. Non sono necessari per questo esempio, quindi li ignoreremo. Come suggerisce il nome, il .adattarsi() Il metodo si adatta al modello e viene utilizzato per stimare alcuni dei parametri del modello, il che significa che calcola il valore ottimizzato di myc utilizzando i dati forniti.
linreg = regressione lineare()
linreg.fit(xpoints, punti y)
.prevedere() Il metodo viene utilizzato per ottenere la soluzione prevista utilizzando il modello e prende il predittore xpoints come argomento.
y_pred = linreg.predict(xpoints)
Ora, Stampa y_pred e notare che i valori sono abbastanza vicini a punti. Se le risposte previste ed effettive hanno un valore vicino a, significa che il modello è accurato. In un caso ideale, i valori di risposta previsti e reali si sovrapporrebbero.
Il modulo pyplot dalla libreria Matplotlib è stato importato come plt. Quindi possiamo facilmente tracciare i grafici usando .dispersione() che prende xpoints e punti come argomenti. Traccia la vera soluzione. La soluzione prevista viene tracciata usando.trama() funzione. Il grafico può essere etichettato utilizzando.xlabel e .ylabel.
plt.scatter (x punti, punti e)
plt.trama (x punti, y_pred)
plt.xlabel (“x punti”)
plt.ylabel (“punti e”)
plt.mostra ()
plt.mostra () muestra todos los objetos de figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... en este momento activos.
attributi .coef_ e .intercettare_ dà la pendenza che è anche il coefficiente di x, e l'intersezione di y. Significa che y = c = 8.80, circa, quando x = 0 e y = 4.22 (1) + 8.80 = 13.02 (circa) quando x = 1. Nota che nell'output l'intersezione è scalare e il coefficiente è una matrice.
Stampa(linreg.coef_)
Stampa(linreg.intercetta_)
Abbiamo costruito il nostro modello. Ora prova a prevedere la soluzione y_new per un nuovo valore predittivo x_new = 16. Là! Abbiamo un modello in grado di prevedere la soluzione per ogni dato predittore.
x_new = np.array ([16]) .riforma (-1,1)
y_new = linreg.predict (x_new)
stampare (y_new)
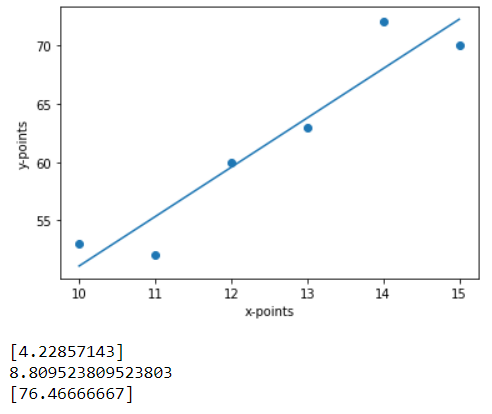
L'immagine sopra è come potrebbe essere il risultato finale. Il 3 le uscite sotto il grafico sono la soluzione al nostro Stampa() dichiarazioni. Allora sono in attesa, intersezione e y_new rispettivamente.
L'equazione della retta di regressione è y = 4.23x + 8,80. Quindi, secondo l'equazione, quando x = 16,
y = 4,23 * (16) + 8,80 = 76,48. La piccola differenza nel calcolo è dovuta ai punti decimali.
Possiamo usare .punto() metodo che campiona x e y come loro 2 argomenti per trovare R2 o il coefficiente di determinazione. Il miglior rapporto qualità-prezzo R2 è 1.0 e può anche assumere valori negativi, visto che il modello potrebbe essere peggiore. Un valore più vicino di R2 un 1.0 indica l'efficienza del nostro modello.
linreg.score(xpoints, punti y)
Esegui il codice e vedrai che il valore di R2 è 0,89, quindi la previsione del modello è affidabile.
Qual è il prossimo?
È semplice come una regressione lineare. Non è l'unico modo, ma mi sembrava il modo più semplice e facile. Non fermarti qui. Quando ti senti a tuo agio con questo, puoi fare un ulteriore passo avanti e considerare un set di dati più ampio. Come esempio, un file CSV. Dovrai lavorare con panda e NumPy in quel caso. Prossimo, puoi testare un modello di regressione logistica lineare o multipla. Continua ad imparare e ad esercitarti.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





