Panoramica
- Qlik è ampiamente associato a potenti dashboard e report di business intelligence.
- Sapevi che puoi utilizzare la potenza di Qlik per eseguire la modellazione predittiva e creare modelli??
- Scopri come farlo con questa guida davvero interessante su come creare un modello di regressione lineare utilizzando Qlik Sense.
introduzione
“Posso utilizzare Qlik Sense per creare un'analisi S S creare un semplice modello di regressione lineare in modo che i miei utenti aziendali possano prevedere i guadagni futuri in base alle vendite target?”
Una domanda intrigante! Qlik è ampiamente associato alla creazione di dashboard e report di business intelligence., non con la modellazione predittiva. Se avessi lo stesso pensiero, non sei solo!
Qlik è come un vento in poppa per qualsiasi leader aziendale. Rende l'analisi e la presentazione dei dati agli utenti finali estremamente facile e veloce. Non sorprende che Qlik venga regolarmente nominata Leader nel Magic Quadrant di Gartner per le piattaforme di Business Intelligence e Analytics..

Quello che mi piace davvero di Qlik è che il suo modello associativo offre la scoperta dei dati in forma libera. Questo aiuta il nostro utente finale a trovare rapidamente tendenze e valori anomali per ottenere informazioni preziose.. Qlik è noto per il suo modello associativo e per l'incredibile velocità con cui rivela le associazioni tra i campi all'interno di un modello di dati..
Con il suo cambio di paradigma di visualizzazione di tutti i dati, inclusi valori anomali, i nostri clienti e le parti interessate possono trovare rapidamente le informazioni per prendere decisioni aziendali critiche. Le applicazioni Qlik abbracciano più settori come:
- Nella sanità, una compagnia di assicurazioni potrebbe voler prevedere il costo futuro dell'assistenza al paziente utilizzando i costi, dati demografici e diagnosi precedenti.
- I difetti del prodotto possono essere previsti utilizzando l'efficienza del processo in base ai difetti precedenti e la precisione delle apparecchiature nel settore manifatturiero.
- Nelle risorse umane, possiamo prevedere il costo futuro del libro paga di un dipendente in base alla sua età ed esperienza.
Pensa alle possibilità, Sono infiniti!
Dopo aver letto questo articolo, puoi indossare il cappello di un data scientist, poiché sia QlikView che Qlik Sense offrono un gran numero di funzioni statistiche che puoi sfruttare per costruire il tuo primo modello predittivo utilizzando la regressione lineare. Iniziamo!
Sommario
- Introduzione alla regressione lineare semplice
- Implementazione della regressione lineare in Qlik
- Confronto dei nostri risultati con un modello creato con Python
Introduzione alla regressione lineare semplice

Fonte: xkcd.com
Iniziamo con il concetto di analisi di regressione. Es una forma de modelado predictivo que revela la relación entre una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... independiente y una dependiente. Questa è forse la tecnica più comune che gli aspiranti professionisti della scienza dei dati imparano per prima..
La regressione viene utilizzata per valutare il contributo di una o più variabili “causando” (variabili indipendenti) a una variabile “causato” (dipendente). Possiamo anche usarlo per prevedere il valore della variabile dipendente dai valori delle variabili indipendenti. Alcuni esempi popolari includono la previsione del prezzo di una casa, lo stipendio di un dipendente, eccetera. (Sono sicuro che la tua mente deve essere piena di idee!!).
Quando c'è una sola variabile indipendente e quando la relazione può essere espressa come una linea retta, la procedura è chiamata regressione lineare semplice.
Una retta può essere definita dall'equazione matematica y = mx + B:
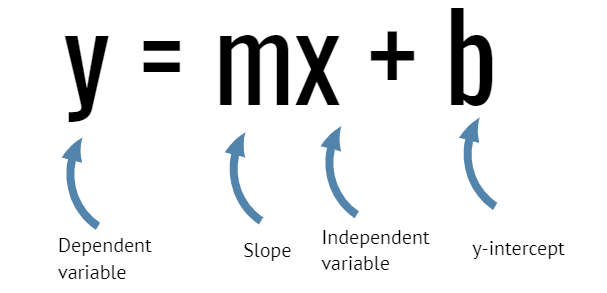
- y è una variabile dipendente ed è rappresentata sull'asse verticale
- x è una variabile indipendente ed è rappresentata sull'asse orizzontale
- m è la pendenza (quantità di variazione in y corrispondente all'aumento di una unità in x)
- b è l'intersezione
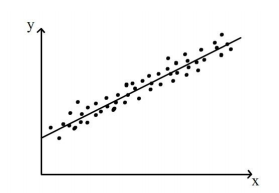 Fonte: http://www.statstutor.ac.uk
Fonte: http://www.statstutor.ac.uk
La procedura di regressione adatta la migliore retta possibile a una matrice di punti dati. Se non è possibile tracciare una singola linea in modo che tutti i punti cadano su di essa, qual è “meglio” linea? Pensaci prima di leggere la risposta.
La linea migliore è quella che riduce al minimo la distanza di tutti i punti dati dalla linea.
Il coefficiente di correlazione indica la forza della relazione tra le variabili indipendenti e dipendenti., mentre il coefficiente di determinazione (r quadrato) spiega in che misura la varianza della variabile indipendente spiega la varianza della variabile dipendente.
Un coefficiente di correlazione vicino a 1 indica una relazione positiva tra la variabile indipendente e dipendente e un coefficiente di determinazione più vicino a 1 indica un buon adattamento dei dati al modello predittivo.
Armati di questa conoscenza, possiamo creare il nostro primo modello di regressione lineare semplice in Qlik Sense o QlikView.
Implementazione della regressione lineare in Qlik
Recentemente, mi sono imbattuto in questo articolo molto interessante che mostra il nesso tra la gravidanza adolescenziale e il tasso di povertà negli Stati Uniti. Vale la pena riflettere su questi fatti sui motivi per cui la gravidanza adolescenziale porta a un più alto tasso di povertà:
- Solo il 38 percentuale di ragazze che hanno avuto un figlio prima 18 anni conseguono il diploma di maturità presso 22
- Due terzi delle madri adolescenti che lasciano la casa di famiglia vivono in condizioni di povertà e una percentuale simile riceve sussidi pubblici nel primo anno di vita del figlio..
- Il settantotto percento dei bambini nati da madri adolescenti mai sposate che non si sono diplomate al liceo vive al di sotto del livello di povertà federale.
È un problema di cui dovremmo essere tutti consapevoli e se possiamo aiutare in qualche modo, dovremmo almeno provare. Sono stato fortunato a trovare un set di dati su questo su Sito web delle statistiche della Pennsylvania State University, STAT462.
Quindi, noi useremo questo set di dati per creare un semplice modello di regressione lineare in Qlik Sense. Vai avanti e salvalo sulla tua macchina. Ecco un'istantanea del set di dati:
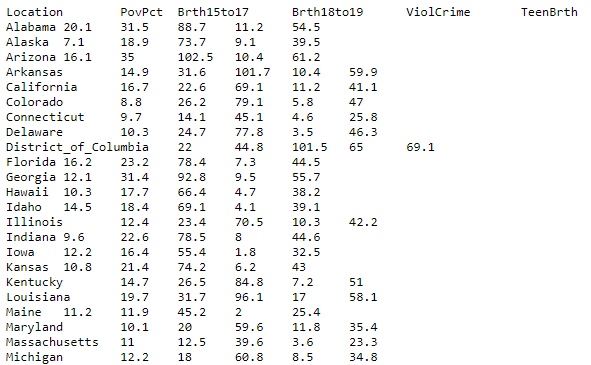
Questo set di dati di dimensione n = 51 è per il 50 stati e il Distretto di Columbia negli Stati Uniti.
Quindi, echemos un vistazo a los pasos y quiero que los siga en Qlik Sense a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que los recorremos.
passo 1: creare un grafico a dispersione
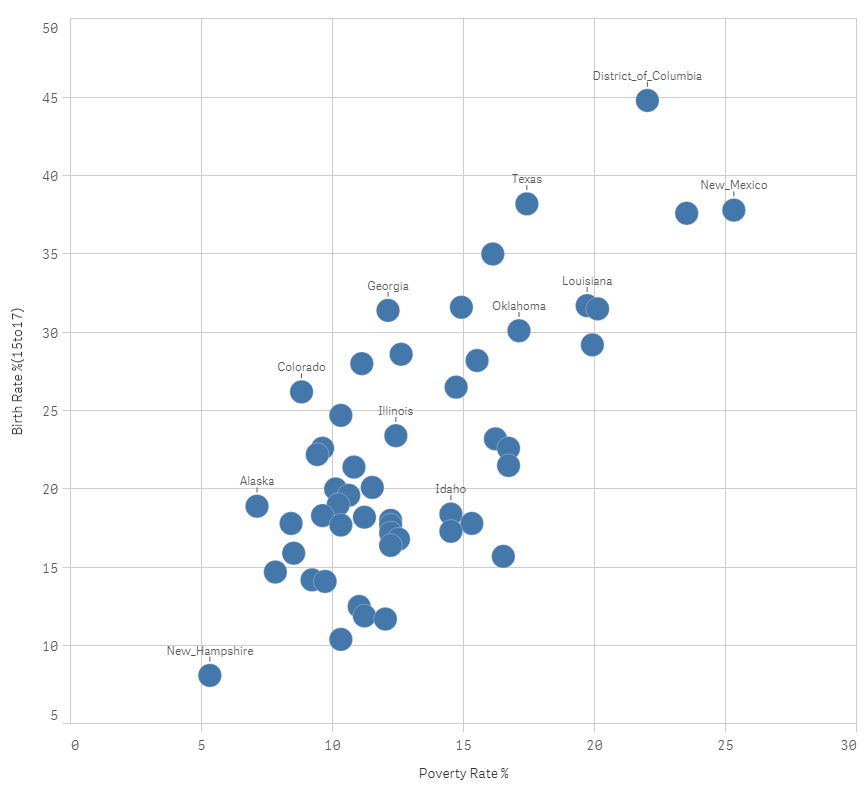
passo 2: Calcola il coefficiente di correlazione
Crea un grafico di testo e immagine con la seguente espressione:
![]()
passo 3: Calcola il coefficiente di determinazione.
Crea un grafico di testo e immagini con questa espressione:
![]()
passo 4: calcola la pendenza
![]()
passo 5: Trova l'intercetta y
![]()
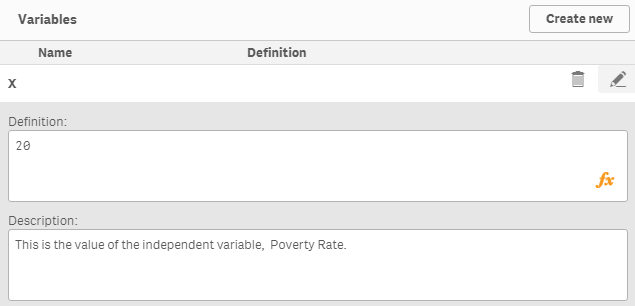
passo 6: creare una variabile x con valore iniziale = 0
Questa variabile ci permetterà di cambiare il valore della variabile indipendente, tasso di natalità (15 un 17), prevedere il tasso di povertà. Fare clic sull'opzione variabile nell'angolo in basso a sinistra dell'editor di fogli:
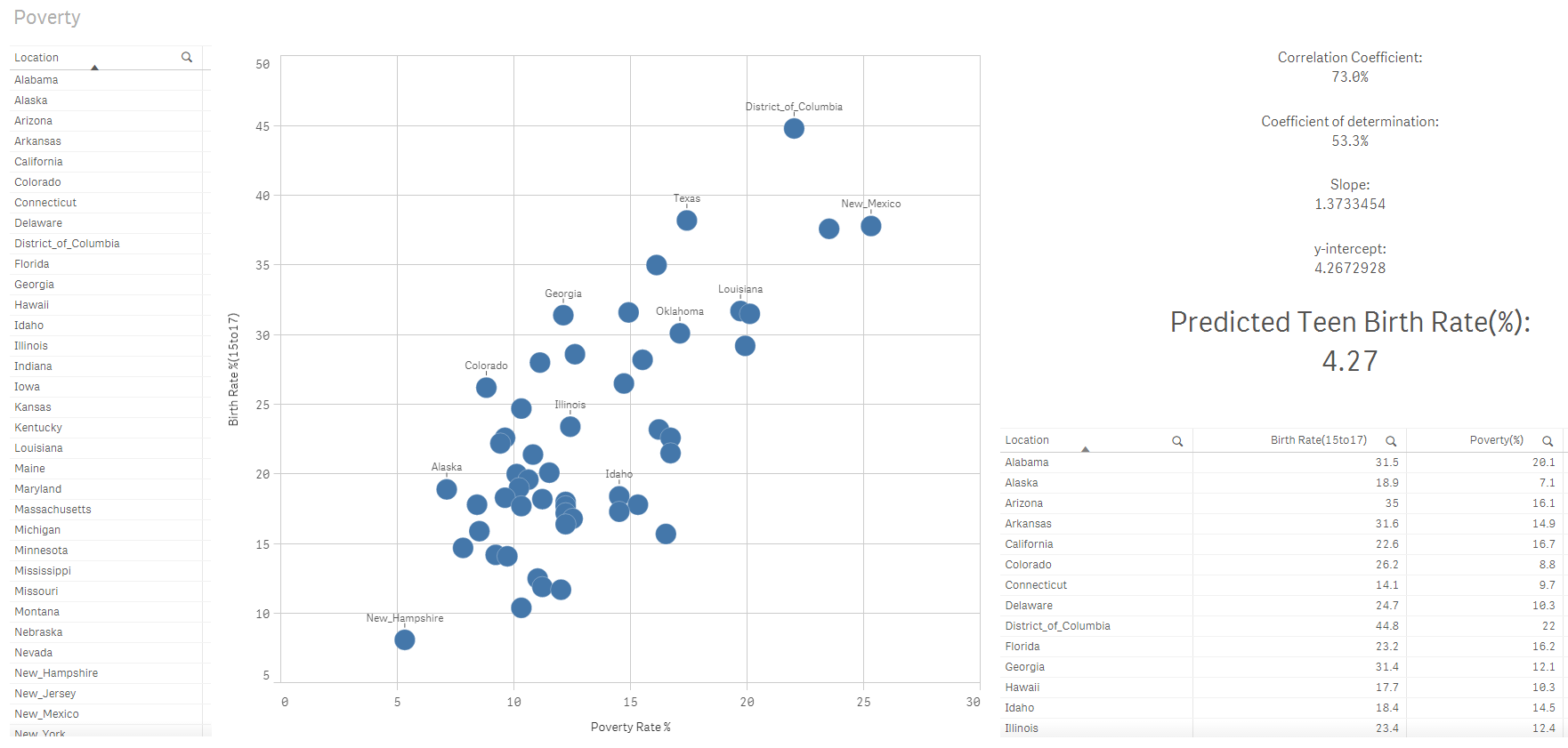
passo 7: Calcola il tasso di natalità previsto per il gruppo di adolescenti (15 un 17)

Come affermato qui, il nostro modello di regressione lineare di Qlik Sense corrisponde all'equazione della linea adattata:
Y = 1.373X + 4,267
Con un tasso di povertà di 0%, il tasso di natalità adolescenziale sarebbe 4,27%. Una variazione di una unità nel valore della variabile indipendente equivale a una variazione di 1,373 nel valore della variabile dipendente.
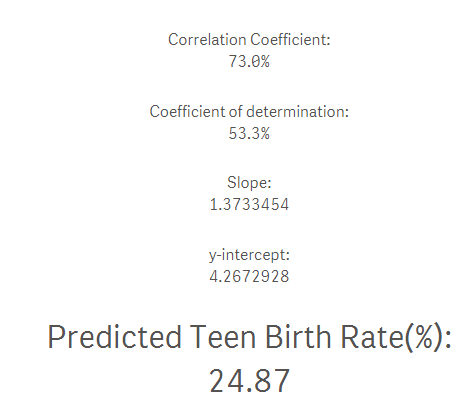
Quale sarebbe il tasso di natalità degli adolescenti se il tasso di povertà fosse? 15%? Questa è la risposta:
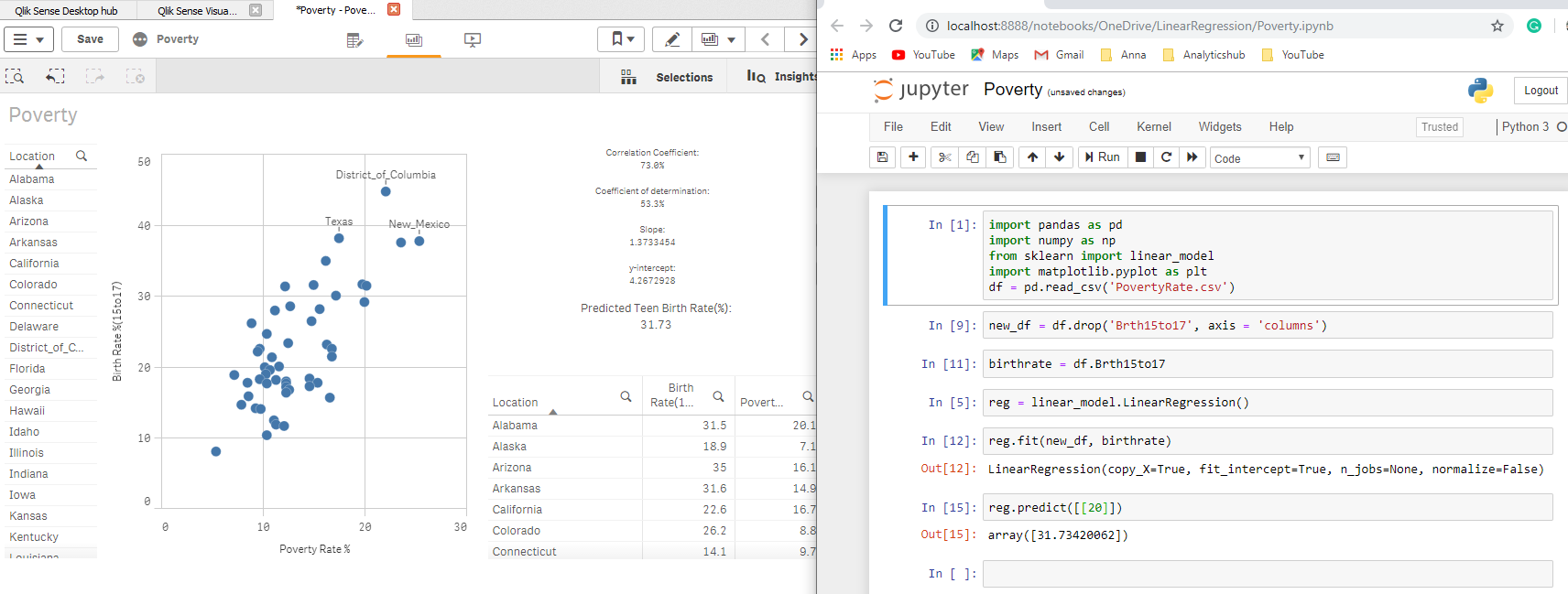
Ora posso combinare il potere del motore associativo per restringere l'elenco degli stati e prevedere il tasso di natalità per una fascia di età di donne da 15 un 17 anni in base alle mie selezioni utilizzando il tasso di povertà del 15%:
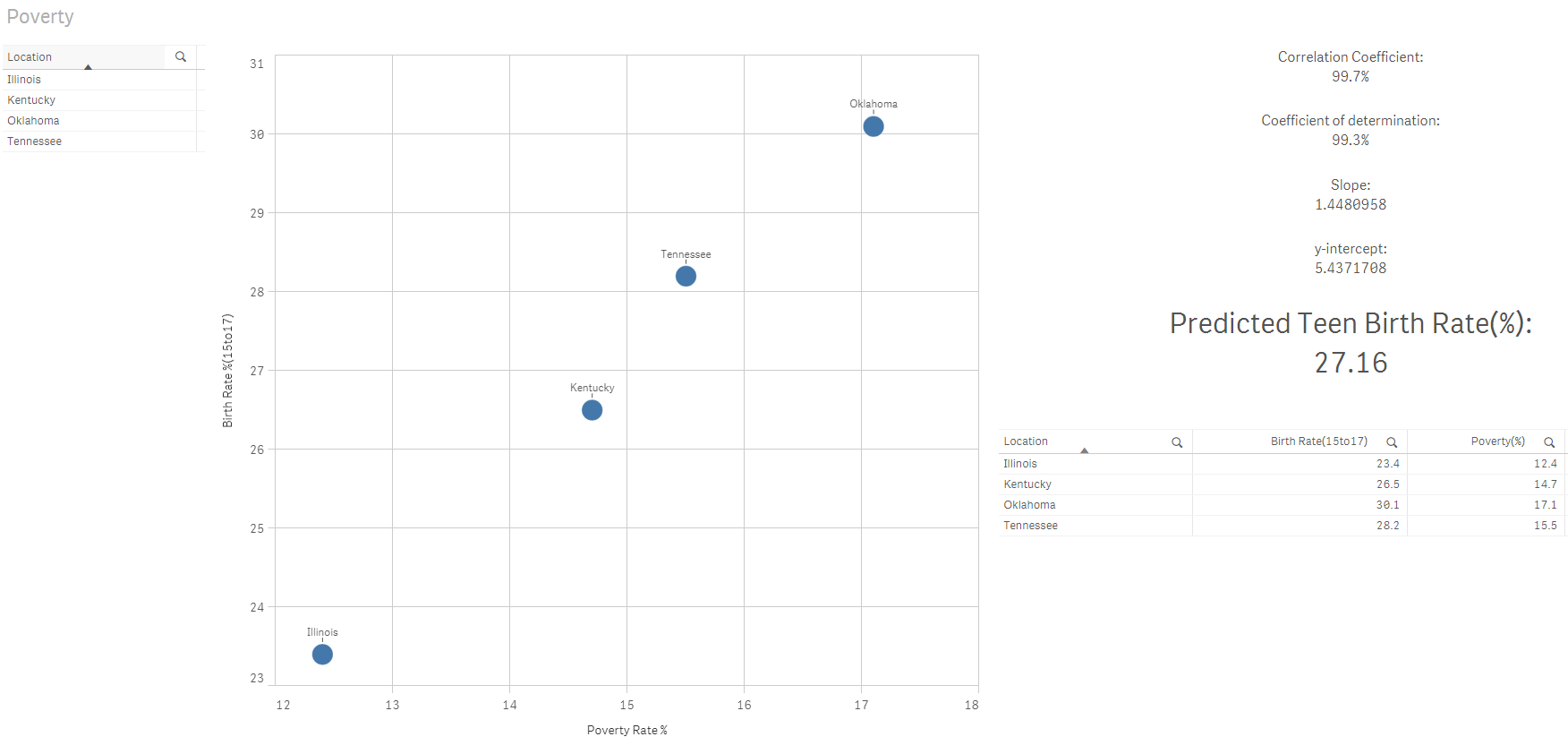
Favoloso! Non ami il potere di Qlik??
Confronto dei nostri risultati con un modello creato con Python
Prossimo, creeremo un modello di regressione semplice simile in Python usando le librerie Pandas e scikit-learn. Voglio confrontare l'accuratezza del modello predittivo che creiamo in Qlik Sense con quello che creeremo in Python.
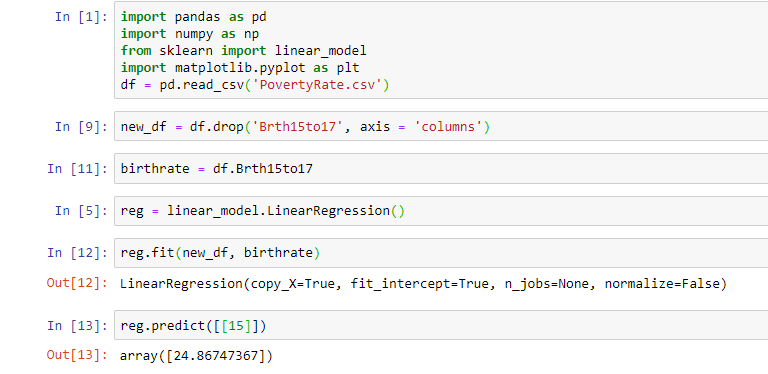
Il risultato del nostro semplice modello di regressione Python corrisponde a quello di Qlik Sense. Confrontiamo il valore predittivo del nostro modello di regressione lineare di Qlik Sense con quello che abbiamo creato in Python:
Note finali
Possiamo creare un semplice modello di regressione per mostrare lo scenario “Cosa succede se” in Qlik Sense se prima confermiamo che la relazione tra la variabile indipendente e quella dipendente è positiva o negativa utilizzando una funzione di correlazione incorporata per vedere la relazione .
Cosa c'è di più, assicurarsi che i dati siano adatti per la modellazione utilizzando il coefficiente di determinazione (R-quadrato). Se un valore è più vicino a 1, quindi i nostri dati sono adatti per la modellazione di regressione semplice in Qlik Sense.
Fammi sapere i tuoi suggerimenti e commenti per questo articolo nella sezione commenti qui sotto..
Circa l'autore
Shilpan Patel – Cofondatore, Analyticshub.io Y Qlik Luminary 2018, 2019

Shilpan è un luminare di Qlik ed è appassionato di consentire agli studenti di sviluppare il loro pieno potenziale attraverso l'apprendimento permanente e il mentoring. Crede che il modo migliore per imparare e padroneggiare un'abilità sia farlo. Ha più di 15 anni di esperienza in dati e analisi, e ha insegnato e guidato migliaia di studenti.





