Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
Panoramica
- Ogni componente di base e fondamentale richiesto per l'analisi del sentiment.
- Ho usato un approccio semplice per spiegare tutte le basi, in modo che anche un lettore principiante possa avere una comprensione completa di tutti i concetti.
- Temi: Pre-elaborazione del testo, Corpus di vocaboli, Estrazione delle caratteristiche (Rappresentazione sparsa e dizionario delle frequenze), Modello di regressione logistica per l'analisi del sentiment.
L'analisi del sentimento è una tecnica di apprendimento automatico supervisionata utilizzata per analizzare e prevedere la polarità dei sentimenti all'interno di un testo (o positivo o negativo).
Viene spesso utilizzato da aziende e aziende per comprendere l'esperienza dei propri utenti, emozioni, risposte, eccetera. in modo che possano migliorare la qualità e la flessibilità dei loro prodotti e servizi.
Ora, approfondiamo la comprensione di come gli ingegneri di machine learning utilizzano questa tecnica di analisi del sentimento per esaminare il sentimento da vari testi.
Raccolta dati
"ALTRI DATI, MEGLIO! “
Esistono così tante origini dati aperte che possono essere utilizzate per addestrare i modelli ML, quindi è una scelta personale raccogliere dati da soli o utilizzare set di dati aperti per addestrare il nostro algoritmo.
I set di dati basati su testo sono generalmente distribuiti come JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.. o CSV formati, quindi per usarli, possiamo recuperare i dati in una lista Python o in un dizionario / oggetto frame di dati.
I dati devono essere suddivisi in treno, validazione e set di test in un modo comune di 60% 20% 20% oh 70% 15% 15%.
Il popolare set di dati di Twitter può essere scaricato da qui.
Tubatura
Ogni attività di machine learning deve avere un OleodottoPipeline è un termine che viene utilizzato in una varietà di contesti, principalmente nella tecnologia e nella gestione dei progetti. Si riferisce a un insieme di processi o fasi che consentono il flusso continuo di lavoro dal concepimento di un'idea alla sua realizzazione finale. Nel campo dello sviluppo software, ad esempio, Una pipeline può includere la programmazione, Test e distribuzione, garantendo così una maggiore efficienza e qualità nel.... Le pipeline vengono utilizzate per dividere i flussi di lavoro di machine learning in parti modulari indipendenti, riutilizzabili che possono quindi essere collegati insieme per migliorare continuamente l'accuratezza del modello e ottenere un algoritmo di successo.
Seguiremo una struttura di base della pipeline per il nostro problema, in modo che un lettore possa facilmente comprendere ogni parte della pipeline utilizzata nel nostro flusso di lavoro. La nostra pipeline includerà i seguenti passaggi:
- Pre-elaborazione del testo e costruzione del vocabolario: Eliminazione di testi indesiderati (parole vuote), punteggiatura, URL, identificatori, eccetera. che non hanno valore affettivo. E poi aggiungi parole uniche preelaborate a un vocabolario.
- Estrazione delle caratteristiche: Iterando attraverso ogni esempio di dati per estrarre le caratteristiche utilizzando un dizionario di frequenza e infine creare una serie di caratteristiche.
- Modello di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....: Utilizzeremo quindi la nostra matrice di funzionalità per addestrare un modello di regressione logistica per utilizzare quel modello per prevedere i sentimenti..
- Modello di prova: Utilizzando il nostro modello addestrato per ottenere le previsioni da dati che non hai mai visto.
Pre-trattamento dei dati
È un passo importante nel nostro portafoglio di progetti. La pre-elaborazione del testo può essere utilizzata per rimuovere parole e spartiti dai dati di testo che non hanno valore affettivo, poiché la pre-elaborazione del testo può migliorare significativamente il nostro tempo di formazione, poiché la dimensione dei nostri dati sarà ridotta e sarà limitata a parole che hanno un valore affettivo. La pre-elaborazione include la gestione di
-
Per le parole
Parole che non hanno valore / peso semantico o sentimentale in una frase. ad esempio: e, è, il, tu, eccetera.
Come elaborarli? Creeremo un elenco che include tutte le possibili stopword come
['noi stessi', 'la sua', 'tra', 'te stesso', 'ma', 'ancora', 'là', 'di', 'una volta', 'durante', 'fuori', 'molto', 'avendo', 'insieme a', 'essi', 'possedere', 'un', 'essere', 'alcuni', 'per', 'fare', 'suo', 'il vostro', 'tale', 'in', 'di', 'maggior parte', 'si', 'Altro', 'spento', 'è', 'S', 'sono', 'o', 'chi', 'come', 'a partire dal', 'lui', 'ogni', 'il', 'loro stessi', 'fino a', 'sotto', 'sono', 'noi', 'queste', 'tuo', 'il suo', 'attraverso', 'assistente', 'né', 'me', 'erano', 'sua', 'Di più', 'lui stesso', 'questo', 'fuori uso', 'dovrebbe', 'Nostro', 'i loro', 'mentre', 'sopra', 'entrambi', 'su', 'a', 'nostro', 'aveva', 'lei', 'Tutti', 'no', 'quando', 'a', 'qualunque', 'prima', 'loro', 'stesso', 'e', 'stato', 'avere', 'in', 'volere', 'Su', 'fa', 'voi stessi', 'poi', 'Quello', 'perché', 'che cosa', 'terminato', 'perché', 'così', 'Potere', 'fatto', 'non', 'Ora', 'sotto', 'lui', 'tu', 'se stessa', 'ha', 'Appena', 'dove', 'pure', 'soltanto', 'io stesso', 'quale', 'quelli', 'io', 'dopo', 'pochi', 'chi', 'T', 'essendo', 'Se', 'il loro', 'mio', 'contro', 'un', 'di', 'facendo', 'esso', 'come', 'ulteriore', 'era', 'qui', 'di']
Ora itereremo attraverso ogni esempio nei nostri dati e rimuoveremo ogni parola dai nostri dati che è presente nell'elenco delle parole non significative.
-
punteggi
I segni di punteggiatura sono simboli che usiamo per enfatizzare il nostro testo. ad esempio:! , @, #, $, eccetera.
Come elaborarli? Li elaboreremo in modo simile a come abbiamo elaborato le stopword, creeremo un elenco di essi ed elaboreremo ogni esempio con quell'elenco.
-
URL e identificatori
Gli URL sono i collegamenti che iniziano con la dichiarazione del protocollo HTTP, ad esempio. 'https: //….’ e gli identificatori vengono utilizzati per menzionare le persone sui social media, ad esempio. '@Nome utente’ entrambi condividono un significato sentimentale nullo.
Come elaborarli? Elaborali creando una funzione "process_handles_urls" ()’ che prenderà i dati dal nostro treno ed eliminerà le parole che iniziano con 'https: //’ O '@’ di ogni esempio.
-
Derivato
La derivazione è un processo di riduzione di una parola alla sua radice di base. Ad esempio, 'giro’ è una parola chiave di turno, giro, giro, eccetera. Poiché la parola radice offre lo stesso valore affettivo per tutte le sue parole suffisse, possiamo ridurre ogni parola alla sua radice di base, che può ridurre le dimensioni del nostro vocabolario e il tempo di formazione. così come.
Come elaborarli? Elaborarli creando una "funzione do_stemming" ()’ che prenderà i dati e ricaverà le parole da ogni esempio.
-
Involucro inferiore
Dobbiamo usare maiuscole e minuscole simili per ogni parola nei dati per rappresentare "Parola", 'PAROLA', 'parola’ dovrebbe esserci un solo caso da seguire, vale a dire, minuscolo, questo può anche aiutare a ridurre le dimensioni del vocabolario ed eliminare la ripetizione delle parole.
Come elaborarli? scorrere ogni esempio, usa il metodo .inferiore () per convertire ogni pezzo di testo in minuscolo.
Corpus di vocaboli
Dopo la preelaborazione dei dati, è ora di creare un vocabolario che memorizzi ogni parola unica e assegni un valore numerico a ogni parola diversa (questo è anche chiamato tokenizzazione).
Useremo questo dizionario di vocabolario per l'estrazione delle caratteristiche.
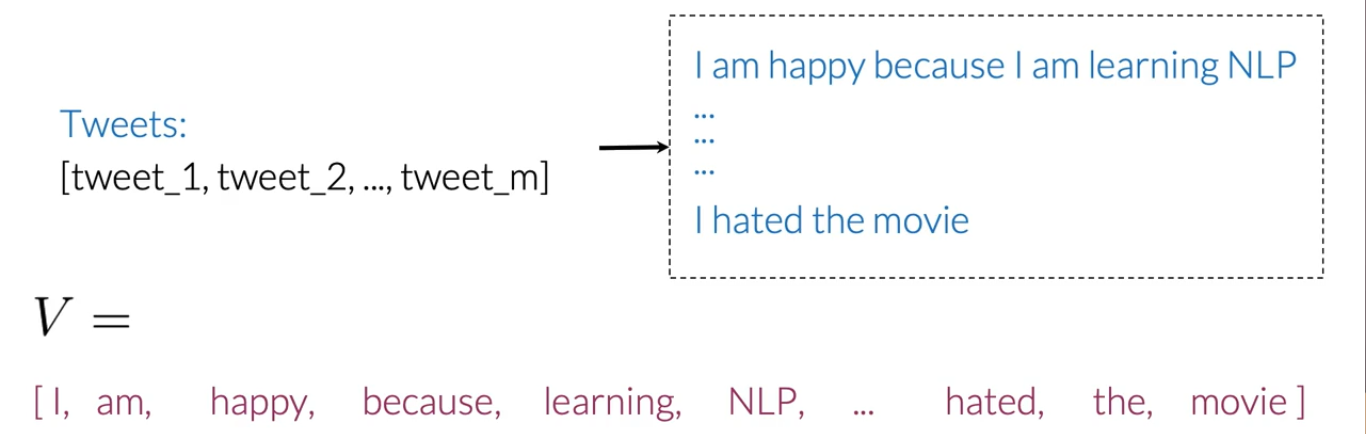
Estrazione delle caratteristiche
Uno dei problemi, quando si lavora con l'elaborazione del linguaggio, è che gli algoritmi di apprendimento automatico non possono funzionare direttamente sul testo non elaborato. Quindi, abbiamo bisogno di alcune tecniche di estrazione delle caratteristiche per convertire il testo in un array (o vettore) caratteristiche numeriche.
Facciamo alcuni esempi di tweet positivi e negativi:

NOTA: L'esempio sopra non viene elaborato, quindi lo elaboreremo prima di passare a ulteriori passaggi.
Scarsa rappresentazione
È un approccio ingenuo estrarre caratteristiche da un testo. Secondo la rappresentazione sparsa, possiamo creare una serie di caratteristiche iterando i dati completi, e per ogni parola, nell'esempio di testo che assegneremo 1 nella posizione di quella parola nell'elenco dei vocaboli e per le parole che non si verificano, NOI ‘ io assegnerò 0. Quindi, la nostra matrice delle caratteristiche avrà righe = frasi totali nei nostri dati e colonne = parole totali nel vocabolario.

Svantaggi:
- Ottimo tempo di allenamento
- Ottimo tempo di previsione
Dizionario di frequenza
Un dizionario di frequenza tiene traccia delle frequenze positive e negative di ogni parola nei nostri dati.

Frequenza positiva: il Numero di volte in cui una parola appare nelle frasi con un sentimento positivo.
Frequenza negativa: il Numero di volte in cui una parola appare in frasi con sentimenti negativi.
Estrazione delle caratteristiche con il dizionario delle frequenze:
Utilizzo del dizionario delle frequenze per l'estrazione delle funzioni, possiamo ridurre le dimensioni di ogni riga che rappresenta ogni frase di una matrice di caratteristiche (vale a dire, pari al numero di parole del vocabolario in caso di sottorappresentazione) in tre dimensioni.
Le caratteristiche dei dati di un testo vengono estratte con il dizionario delle caratteristiche utilizzando le seguenti formule:

Il processo sembra quasi:


Ora abbiamo un vettore di funzionalità tridimensionale per il nostro tweet che assomiglia a questo:
Xm = [1,8,11]
Ora itereremo attraverso ogni esempio per estrarre le caratteristiche da ogni esempio e poi useremo quelle caratteristiche per creare la matrice delle caratteristiche che possiamo usare per l'addestramento.. Alla fine, abbiamo una serie di caratteristiche come:

Regressione logistica per l'analisi del sentiment
La regressione logistica modella le probabilità di problemi di classificazione con due possibili esiti. È un'estensione del modello di regressione lineare per problemi di classificazione.
Usi della regressione logistica una funzione sigmoide per mappare l'output della nostra funzione lineare (?TX) Entra 0 e 1 con qualche soglia (in genere 0.5) distinguere tra due classi, quindi se h> 0.5 è una classe positiva, e se h <0.5 è una classe negativa. (Spiegare la regressione logistica completa va oltre lo scopo di questo articolo.)

Modello di analisi del sentiment di formazione
La formazione del nostro modello seguirà i seguenti passaggi:
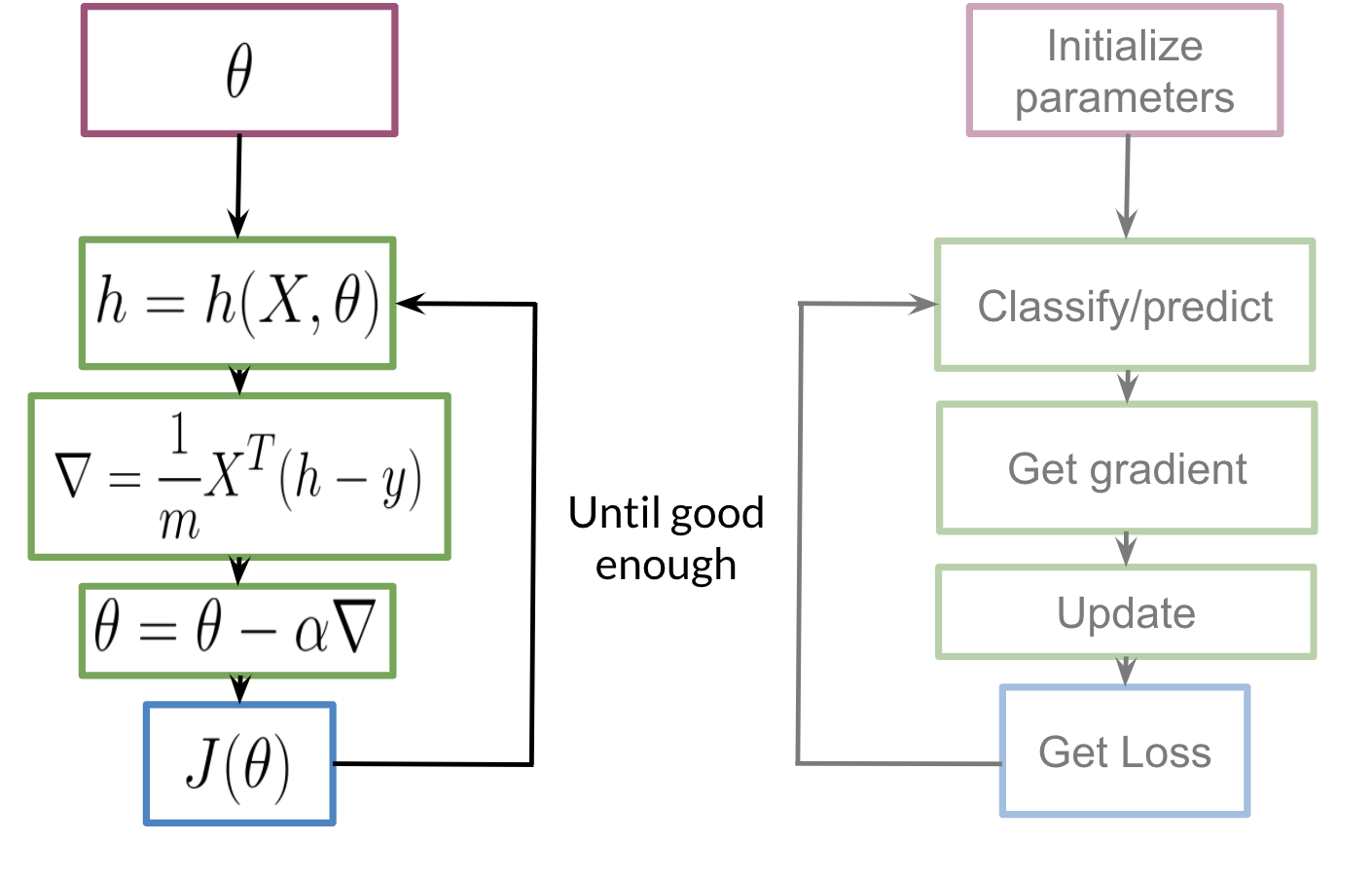
Inizializziamo il nostro parametro θ, che possiamo usare nel nostro sigmoide, Quindi calcoliamo il gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... che utilizzeremo per aggiornare θ e quindi calcolare il costo. Continueremo a ripetere i passaggi fino a quando il costo non sarà ridotto al minimo / convergere.
Testare il nostro modello
Per testare il nostro modello utilizzeremo il nostro set di convalida e seguiremo i seguenti passaggi:
- Dividi i dati in X_validation (testo) e Y_validation (sentimento).
- Usa l'estrazione delle caratteristiche per X_validation per trasformare i testi in caratteristiche numeriche.
- Trova il vettore h (= sigmoide (?TX)) per ogni testo nel set di convalida.
- Assegna una funzione per ottenere le classi effettive durante il confronto con una soglia.
- Trova la precisione delle nostre previsioni.

Riepilogo
Sono contento che tu sia arrivato fino a qui! Se sei un principiante nell'elaborazione del linguaggio naturale, Spero di poterti dare un'idea di come funzionano le cose sotto il cofano e renderti in grado di affrontare argomenti più complessi e avanzati e, se sei un professionista, Spero di essere riuscito a rispolverare le tue basi.
L'elaborazione del linguaggio naturale è un vasto dominio dell'intelligenza artificiale, le sue applicazioni sono utilizzate in vari paradigmi, come i chatbot, analisi del sentimento, traduzione automatica, correzione automatica, eccetera. Esistono diverse piattaforme e articoli di e-learning, lavori, eccetera. distribuzione gratuita che può essere utile per far avanzare ulteriormente il viaggio.
Riferimenti: Specializzazione in elaborazione del linguaggio naturale





