Panoramica
- Ecco una rapida introduzione alla creazione di pipeline ML con PySpark
- La capacità di creare queste pipeline di apprendimento automatico è un'abilità indispensabile per qualsiasi aspirante scienziato dei dati.
- Questo è un articolo pratico con un approccio al codice strutturato di PySpark, Quindi prepara il tuo IDE Python preferito!
introduzione
Prenditi un momento per riflettere su questo.: Quali sono le competenze che un aspirante data scientist deve possedere per ottenere una posizione nel settore??
UN apprendimento automatico Il progetto ha molti componenti mobili che devono riunirsi prima di poterlo eseguire con successo. La capacità di sapere come costruire una pipeline di machine learning end-to-end è una risorsa preziosa. Come scienziato dei dati (aspirante o stabilito), dovresti sapere come funzionano queste pipeline di machine learning.
Questo è, in poche parole, la fusione di due discipline: scienza dei dati e ingegneria del software. Questi due vanno di pari passo per uno scienziato dei dati. Non si tratta solo di costruire modelli, dobbiamo avere le competenze software per costruire sistemi di livello aziendale.

Quindi, in questo articolo, ci concentreremo sull'idea di base alla base della creazione di queste pipeline di apprendimento automatico utilizzando PySpark. Questo è un articolo pratico, quindi avvia il tuo IDE Python preferito e iniziamo!!
Nota: Questa è la parte 2 dalla mia serie PySpark per principianti. Puoi dare un'occhiata all'articolo introduttivo qui sotto:
Sommario
- Eseguire operazioni di base su un frame di dati Spark
- Leggi un file CSV
- Definire lo schema
- Esplorare i dati usando PySpark
- Controlla le dimensioni dei dati
- Descrivi i dati
- Conteggio valori mancanti
- Trova il conteggio dei valori univoci in una colonna
- Codifica le variabili categoriali usando PySpark
- Indicizzazione delle stringhe
- Una codifica a caldo
- assemblatore di vettore
- Costruire pipeline di machine learning con PySpark
- Trasformatori e stimatori
- Esempi di tubi
Eseguire operazioni di base su un frame di dati Spark
Un passaggio essenziale (e prima) in qualsiasi progetto di data science è comprendere i dati prima di costruirne uno Apprendimento automatico modello. La maggior parte degli aspiranti alla scienza dei dati inciampa qui, semplicemente non passano abbastanza tempo a capire con cosa stanno lavorando. C'è una tendenza a correre e costruire modelli, un errore che deve evitare.
Seguiremo questo principio in questo articolo.. Seguirò sempre un approccio strutturato per assicurarci di non perdere alcun passaggio critico.
Primo, tomemos un momento y comprendamos cada variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... con la que trabajaremos aquí. Useremo un set di dati di a Partita di cricket India vs Bangladesh. Vediamo le diverse variabili che abbiamo nel set di dati:
- Pastella: Identificazione univoca della pastella (totale)
- Battitore_Nome: Il nome del battitore (Corda)
- Giocatore di bowling: Identificazione univoca del bowler (totale)
- Nome_giocatore: Nome del giocatore di bocce (Corda)
- Commento: Descrizione dell'evento come trasmesso (catena)
- Dettaglio: Un'altra catena che descrive gli eventi come finestre e consegne extra (Catena)
- Licenziato: Identificazione univoca della pastella se scartata (Corda)
- ID: ID coda univoco (catena)
- isball: Se la consegna era legale o meno (booleano)
- isconfine: Se il battitore ha raggiunto un limite o meno (binario)
- Iswicket: Se il battitore ha sparato o no (binario)
- Su: Circa il numero (Doppio)
- carriere: Funziona su quella particolare puntata (totale)
- Timestamp: Ora in cui i dati sono stati registrati (marca temporale)
Quindi iniziamo, essere d'accordo?
Leggi un file CSV
Quando accendiamo Spark, il SparkSession La variabile è opportunamente disponibile sotto il nome ‘Scintilla – scintilla'. Possiamo usarlo per leggere vari tipi di file, come CSV, JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.., TESTO, eccetera. Questo ci permette di salvare i dati come un frame di dati Spark.
Per impostazione predefinita, tratta il tipo di dati di tutte le colonne come una stringa. Puoi controllare i tipi di dati usando il printSchema funzione in frame di dati:

Definire lo schema
Ora, non vogliamo che tutte le colonne nel nostro set di dati vengano trattate come stringhe. Quindi, Cosa possiamo fare al riguardo?
Possiamo definire lo schema personalizzato per il nostro frame di dati in Spark. Per questo, dobbiamo creare un oggetto di Tipo di struttura che ha un elenco di StructField. Ed ovviamente, dovremmo definire StructField con un nome di colonna, il tipo di dati della colonna e se i valori null sono consentiti o meno per la particolare colonna.
Fare riferimento al seguente frammento di codice per capire come creare questo schema personalizzato:
Rimuovi colonne dai dati
In qualsiasi progetto di machine learning, abbiamo sempre delle colonne che non servono per risolvere il problema. Sono sicuro che anche tu hai già affrontato questo dilemma, sia nell'industria o in a hackathon online.
Nel nostro caso, possiamo usare la funzione drop per rimuovere la colonna dai dati. Utilizzare il asterisco

pipeline di apprendimento automatico pyspark
Esplorare i dati usando PySpark
Controlla le dimensioni dei dati
A differenza dei panda, I frame di dati Spark non hanno la funzione di forma per controllare le dimensioni dei dati. Anziché, possiamo usare il codice qui sotto per controllare le dimensioni del set di dati:
Descrivi i dati scintille descrivere La funzione ci fornisce la maggior parte dei risultati statistici come media, contare, minimo, massimo e deviazione standard. Puoi usare il astratto

pipeline di apprendimento automatico pyspark
Conteggio valori mancanti
È strano quando otteniamo un set di dati senza valori mancanti. Riesci a ricordare l'ultima volta che è successo??
È importante controllare il numero di valori mancanti presenti in tutte le colonne. Conoscere il conteggio ci aiuta a gestire i valori mancanti prima di creare qualsiasi modello di machine learning con quei dati..

pipeline di apprendimento automatico pyspark
Conteggi del valore di una colonna A differenza dei panda, non abbiamo il value_counts () funzione nei frame di dati Spark. Puoi usare il raggruppare per
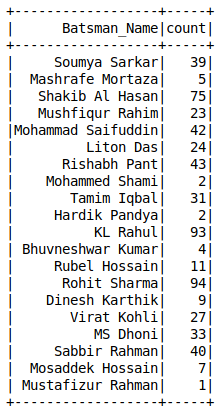
pipeline di apprendimento automatico pyspark
Codifica le variabili categoriali usando PySpark
La maggior parte degli algoritmi di apprendimento automatico accetta dati solo in forma numerica. Perciò, è essenziale convertire in numeri qualsiasi variabile categoriale presente nel nostro set di dati.
Ricorda che non possiamo semplicemente rimuoverli dal nostro set di dati, in quanto possono contenere informazioni utili. Sarebbe un incubo perderlo solo perché non vogliamo capire come usarli!!
Vediamo alcuni dei metodi per codificare le variabili categoriali usando PySpark.
Indicizzazione delle stringhe
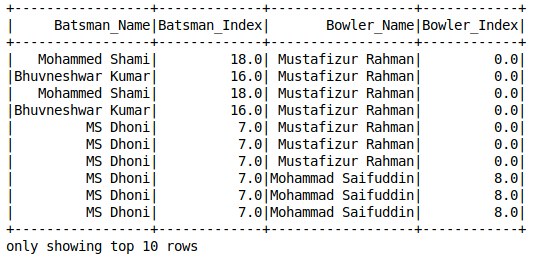
pipeline di apprendimento automatico pyspark
Codifica One-Hot
La codifica one-hot è un concetto che ogni data scientist dovrebbe conoscere. Mi sono fidato di lui diverse volte quando si trattava di valori mancanti. È un salvavita! Ecco l'avvertimento: Spark's OneHotEncoder
non codifica direttamente la variabile categoriale. Primo, dobbiamo usare String Indexer per convertire la variabile in forma numerica e quindi usare OneHotEncoderEstimator
per codificare più colonne del set di dati.
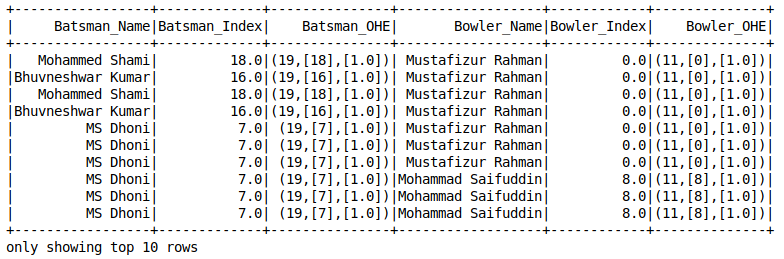
pipeline di apprendimento automatico pyspark
assemblatore di vettore
Un assemblatore di vettori combina un determinato elenco di colonne in un'unica colonna vettoriale.
Questo viene in genere utilizzato alla fine delle fasi di esplorazione e pre-elaborazione dei dati. In questa fase, di solito lavoriamo con alcune funzionalità grezze o trasformate che possono essere utilizzate per addestrare il nostro modello. Vector Assembler li converte in una singola colonna di funzionalità per addestrare il modello di apprendimento automatico

pipeline di apprendimento automatico pyspark
Costruire pipeline di machine learning con PySpark
Un progetto di machine learning di solito prevede passaggi come la pre-elaborazione dei dati, estrazione delle caratteristiche, adattare il modello e valutare i risultati. Dobbiamo eseguire molte trasformazioni sui dati in sequenza. Come puoi immaginare, tenerne traccia può diventare un compito noioso.
È qui che entrano in gioco le pipeline di machine learning..
un pipelinePipeline è un termine che viene utilizzato in una varietà di contesti, principalmente nella tecnologia e nella gestione dei progetti. Si riferisce a un insieme di processi o fasi che consentono il flusso continuo di lavoro dal concepimento di un'idea alla sua realizzazione finale. Nel campo dello sviluppo software, ad esempio, Una pipeline può includere la programmazione, Test e distribuzione, garantendo così una maggiore efficienza e qualità nel... nos permite mantener el flujo de datos de todas las transformaciones relevantes que se requieren para alcanzar el resultado final. Dobbiamo definire le fasi della pipeline che fungono da catena di comando per l'esecuzione di Spark. Qui,
cada etapa es un transformador o un stimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati.....
Trasformatori e stimatori Come suggerisce il nome, trasformatori
convertire un frame di dati in un altro aggiornando i valori correnti di una particolare colonna (come convertire le colonne categoriali in numeriche) o mappandolo su altri valori usando una logica definita. Uno stimatore implementa il adattarsi() metodo in un frame di dati e produce un modello. Ad esempio, Regressione logistica è uno stimatore che addestra un modello di classificazione quando chiamiamo il adattarsi()
metodo.
Capiamolo con l'aiuto di alcuni esempi.
Esempi di tubi

pipeline di apprendimento automatico pyspark
- Abbiamo creato il data frame. Supponiamo di dover trasformare i dati nel seguente ordine: fase 1: Etichetta Codifica o Stringa Indice la colonna
- Categoria 1 Fase 2: Etichetta Codifica o Stringa Indice la colonna
- categoria_2 stage_3: One-Hot Encode la columna indexada
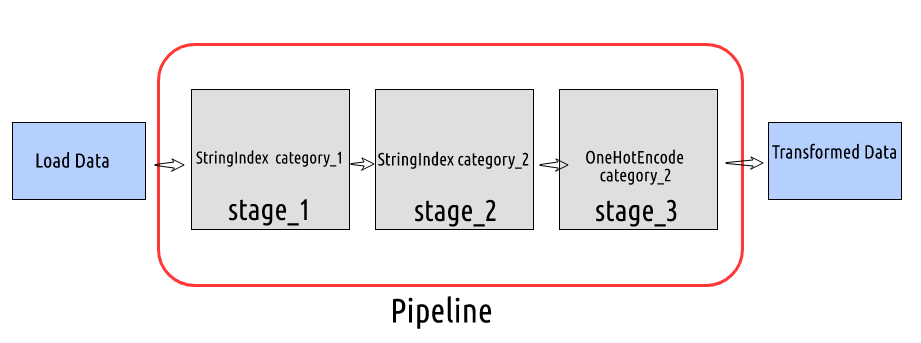
pipeline di apprendimento automatico pyspark In ogni fase, passeremo il nome della colonna di input e output e configureremo la pipeline passando le fasi definite nell'elenco di Tubatura
oggetto.

pipeline di apprendimento automatico pyspark
Ora, Facciamo un esempio più complesso di come configurare una pipeline. Qui, trasformeremo i dati e costruiremo un modello di regressione logistica.

pipeline di apprendimento automatico pyspark
- Ora, supponiamo che questo sia l'ordine della nostra canalizzazione: fase 1: Etichetta Codifica o Stringa Indice la colonna
- feature_2 Fase 2: Etichetta Codifica o Stringa Indice la colonna
- feature_3 stage_3: One Hot Encode la colonna indicizzata di feature_2 e
- feature_3
- stage_4: Creare un vettore di tutte le caratteristiche necessarie per addestrare un modello di regressione logistica
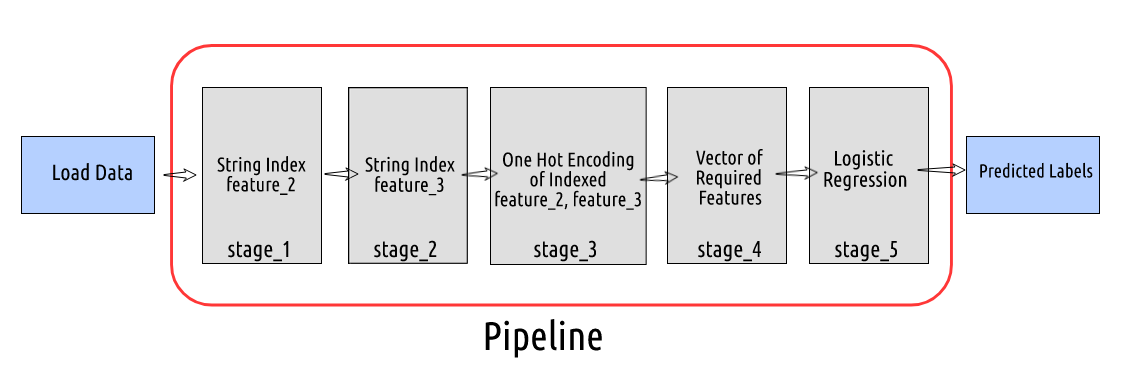
pipeline di apprendimento automatico pyspark
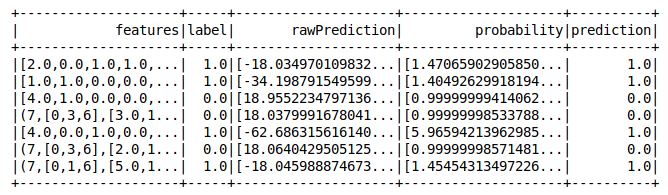
pipeline di apprendimento automatico pyspark
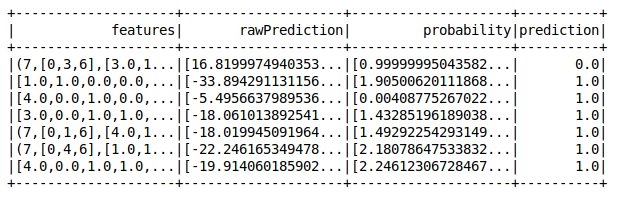
pipeline di apprendimento automatico pyspark
Perfetto!
Note finali
Questo era un articolo breve ma intuitivo su come costruire pipeline di machine learning usando PySpark. Lo ribadirò di nuovo perché è così importante: devi sapere come funzionano questi tubi. Questa è una parte importante del tuo ruolo di scienziato dei dati..
Hai mai lavorato a un progetto di machine learning end-to-end?? Oppure hai fatto parte di un team che ha costruito questi tubi in un ambiente industriale?? Connettiamoci nella sezione commenti qui sotto e discutiamo.
Ci vediamo nel prossimo articolo su questa serie PySpark per principianti. Buon apprendimento!
Imparentato





