introduzione
Con la crescente necessità di amministratori di data science, abbiamo bisogno di strumenti che eliminino il fastidio di fare scienza dei dati e lo rendano divertente. Non tutti sono disposti a imparare a programmare, anche se mi piacerebbe imparare / applicare la scienza dei dati. È qui che gli strumenti basati su GUI possono tornare utili..
Oggi, Ti presenterò un altro strumento basato su GUI: arancia. Questo strumento è ideale per i principianti che desiderano visualizzare schemi e comprendere i propri dati senza sapere effettivamente come codificare.
Nel mio articolo precedente, Ti ho presentato un altro strumento KNIME basato su GUI. Se non vuoi imparare a programmare ma applica ancora la scienza dei dati, puoi provare uno di questi strumenti.
Alla fine di questo tutorial, sarai in grado di prevedere quale persona di un determinato gruppo di persone ha diritto a un prestito con Orange.
Sommario:
- Perché arancione??
- Configurazione del sistema:
- Creare il tuo primo flusso di lavoro
- Familiarizza con le basi
- Dichiarazione problema
- Importazione dei file di dati
- Capire i dati
- Come pulisci i tuoi dati??
- Allena il tuo primo modello
1. Perché arancione??
Orange è una piattaforma creata per il mining e l'analisi in un flusso di lavoro basato su GUI. Ciò significa che non è necessario sapere come codificare per poter lavorare con Orange ed estrarre dati., elaborare i numeri e ottenere informazioni.
Può eseguire attività che vanno dalla visualizzazione di base alla manipolazione dei dati, trasformazioni e data mining. Consolida tutte le funzioni dell'intero processo in un unico flusso di lavoro.
La parte migliore e l'elemento di differenziazione di Orange è che ha delle immagini meravigliose. Puoi provare le sagome, mappe di calore, mappe geografiche e tutti i tipi di visualizzazioni disponibili.

2. Configurazione del sistema
Orange viene integrato con lo strumento Anaconda se lo hai installato in precedenza. Altrimenti, segui questi passaggi per scaricare Orange.
passo 1: e un https://orange.biolab.si e fai clic su Scarica.
passo 2: Installa la piattaforma e configura la directory di lavoro per Orange per archiviare i tuoi file.
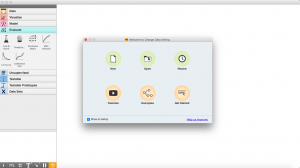
Ecco come appare la home page di Orange. Ha opzioni che ti permettono di creare nuovi progetti, apri i progetti recenti o visualizza i campioni e inizia.
Prima di approfondire come funziona Orange, Definiamo alcuni termini chiave per aiutarci a capire:
- Un widget è il punto di elaborazione di base di qualsiasi manipolazione dei dati. Puoi eseguire una serie di azioni a seconda di ciò che scegli nel selettore del widget a sinistra dello schermo.
- Un flusso di lavoro è la sequenza di passaggi o azioni che esegui sulla tua piattaforma per svolgere un determinato compito.
Puoi anche andare su “Esempi di flusso di lavoro” nella schermata principale per vedere più flussi di lavoro dopo aver creato il primo.
Per adesso, clicca su “Nuovo” e iniziamo a creare il tuo primo flusso di lavoro.
3. Crea il tuo primo flusso di lavoro
Questo è il primo passo verso la costruzione di una soluzione a qualsiasi problema.. Dobbiamo prima capire quali passi dobbiamo compiere per raggiungere il nostro obiettivo finale. Dopo aver cliccato “Nuovo” nel passaggio precedente, questo è quello che avrei dovuto creare.

Questo è il tuo flusso di lavoro vuoto in Orange. Ora, sei pronto per esplorare e risolvere qualsiasi problema trascinando qualsiasi widget dal menu widget al tuo flusso di lavoro.
4. Familiarizza con le basi
Orange è una piattaforma che può aiutarci a risolvere la maggior parte dei problemi di data science di oggi. Argomenti che vanno dalle visualizzazioni più basilari a addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... È anche possibile valutare ed eseguire un Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso... nei set di dati:
4.1 Problema
Il problema che stiamo cercando di risolvere in questo tutorial è il problema pratico. Previsione del prestito cui si può accedere tramite questo link su Datahack.
4.2 Importazione di file di dati
Iniziamo con il primo e necessario passaggio per comprendere i nostri dati e fare previsioni: importando i nostri dati
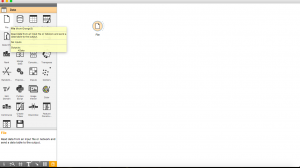
passo 1: Fare clic sulla scheda “Dati” nel menu di selezione del widget e trascina il widget “File” al nostro flusso di lavoro vuoto.
passo 2: Fare doppio clic sul widget “File” e seleziona il file che vuoi caricare nel flusso di lavoro. In questo articolo, come impareremo a risolvere il problema pratico della previsione del prestito, importerò il set di dati di allenamento da esso.
passo 3: Una volta che puoi vedere la struttura del tuo set di dati usando il widget, torna chiudendo questo menu.
passo 4: Ora che abbiamo i dettagli .csv non elaborati, dobbiamo convertirli in un formato che possiamo usare nel nostro mining. Fare clic sulla linea tratteggiata intorno al widget “File” e trascina, e quindi fare clic in un punto qualsiasi dello spazio vuoto.
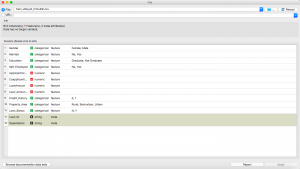
passo 5: Come abbiamo bisogno di una tabella di dati per visualizzare meglio i nostri risultati, clicchiamo sul widget “Tabella dati”.
passo 6: Ora fai doppio clic sul widget per visualizzare la sua tabella.
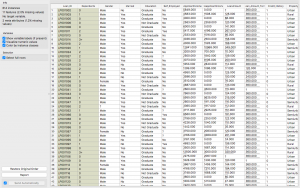
purificato! Non è così?
Ora visualizziamo alcune colonne per trovare modelli interessanti nei nostri dati..
4.3 Capire i nostri dati
4.3.1 Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative....
Fare clic sul semicerchio davanti al widget “File” e trascinalo in uno spazio vuoto nel flusso di lavoro e seleziona il widget “Diagramma di dispersione”.
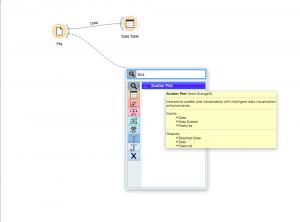
Dopo aver creato un widget grafico a dispersione, fai doppio clic su di esso ed esplora i tuoi dati in questo modo. Puoi selezionare gli assi X e Y, colori, forme, dimensioni e molte altre manipolazioni.
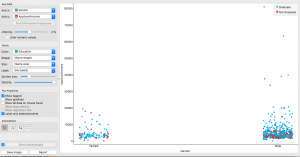
La trama che ho esplorato è una trama di genere per reddito, con i colori stabiliti nei livelli di istruzione. Come possiamo vedere negli uomini, La fascia di reddito più alta appartiene naturalmente ai laureati!
Anche se nelle donne, vediamo che molte delle laureate guadagnano poco o niente. Qualsiasi motivo specifico? Scopriamolo utilizzando il Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate.....
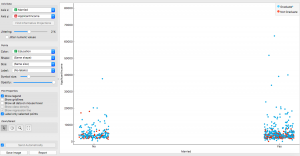
Una possibile ragione che ho trovato era il matrimonio. Un gran numero di laureati sposati è risultato appartenere a gruppi a reddito più basso; questo può essere dovuto a responsabilità familiari o sforzi extra. Ha perfettamente senso, verità?
4.3.2 Distribuzione
Un altro modo per visualizzare le nostre distribuzioni sarebbe il widget “distribuzioni”. Fare nuovamente clic sul semicerchio e trascinare per trovare il widget “distribuzioni”.
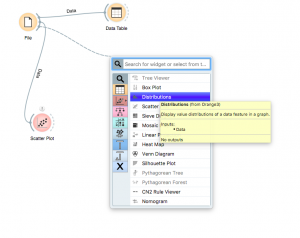
Ora fai doppio clic su di esso e visualizza!
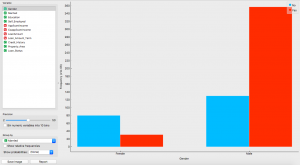
Quella che vediamo è una distribuzione molto interessante. Abbiamo più uomini sposati che donne nel nostro set di dati.
4.3.3 Schema del setaccio
In che modo il reddito è correlato ai livelli di istruzione?? I laureati sono pagati più degli studenti universitari??
Visualizziamo usando un diagramma a setaccio.
Fare clic e trascinare dal widget “File” e cerca “Schema del setaccio”.
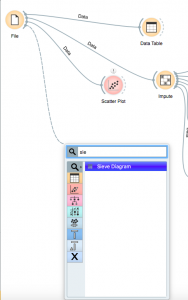
Una volta indossato, fai doppio clic su di esso e seleziona i tuoi assi.
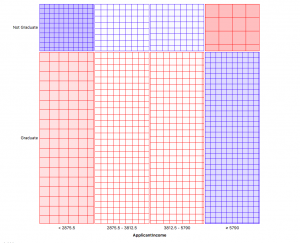
Questo grafico divide le sezioni di distribuzione in 4 contenitori. Le sezioni possono essere esaminate passandoci sopra con il mouse.
Ad esempio, laureati e laureandi si dividono 78% di 22%. Dopo, suddivisioni del 25% ciascuno dividendo il reddito del richiedente in 4 gruppi uguali. Ecco il compito per te, generare informazioni da questi grafici e condividerle nella sezione commenti.
Vediamo ora come pulire i nostri dati per iniziare a costruire il nostro modello.
5. Come pulisci i tuoi dati??
Qui, per scopi di pulizia, imputeremo i valori mancanti. L'imputazione è un passaggio molto importante per comprendere e utilizzare al meglio i nostri dati.
Fare clic sul widget “File” e trascina per trovare il widget “Imputare”.
Quando fai doppio clic sul widget dopo averlo posizionato, vedrai che ci sono una varietà di metodi di imputazione che puoi usare. Puoi anche usare metodi predefiniti o scegliere metodi individuali per ogni classe separatamente.
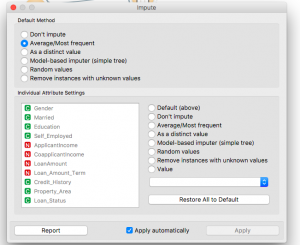
Qui, Ho selezionato il metodo predefinito come Medio per i valori numerici e Più frequente per i valori basati su testo (categorico).
È possibile selezionare tra una varietà di imputazioni come:
- Valore diverso
- Valori casuali
- Elimina le righe con valori mancanti
- Basato su modelli
Le altre cose che puoi includere nel tuo approccio all'addestramento del tuo modello sono l'estrazione e la generazione di feature.. Per una migliore comprensione, segui questo articolo sull'esplorazione dei dati e sull'ingegneria delle funzionalità (https://www.analyticsvidhya.com/blog/2016/01/guide -data-scan /)
6. Allena il suo primo modello
A partire dalle basi, prima addestreremo un modello lineare che comprenda tutte le caratteristiche solo per capire come selezionare e costruire modelli.
passo 1: Primo, Dobbiamo stabilire un variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... per applicare la Regressione Logistica ad esso.
passo 2: Vai al widget “File” e fai doppio clic su di esso.
passo 3: Ora, fare doppio clic su Stato_prestito colonna e selezionala come variabile di destinazione. Fare clic su Applica.
passo 4: Una volta che abbiamo impostato la nostra variabile target, trova i dati del widget puliti “Imputare” come segue e posiziona il widget “Regressione logistica”.
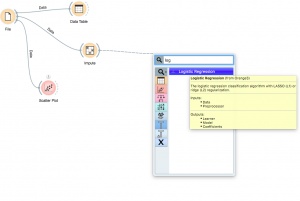
passo 5: Fare doppio clic sul widget e selezionare l'icona regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.... Cosa vuoi fare.
- Regressione della cresta:
- Eseguire la regolarizzazione L2, vale a dire, aggiunge una sanzione equivalente a quadrato di magnitudo coefficienti
- Obiettivo di minimizzazione = LS Obj + un * (somma dei quadrati dei coefficienti)
- Regressione ad anello:
- Eseguire la regolarizzazione L1, vale a dire, aggiunge una sanzione equivalente a valore assoluto della grandezza coefficienti
- Obiettivo di minimizzazione = LS Obj + un * (somma del valore assoluto dei coefficienti)
Per una migliore comprensione di questi, visita il link sulle regressioni Ridge e Lasso https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
Ho scelto Ridge per la mia analisi, puoi scegliere tra i due.
passo 6: Prossimo, clicca sul widget “Imputare” oh “Regressione logistica” e trova il widget “Test e punteggio”. Assicurati di collegare entrambi dati e modello per testare il widget.
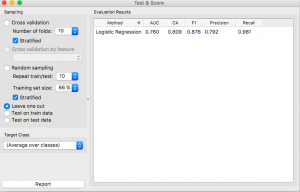
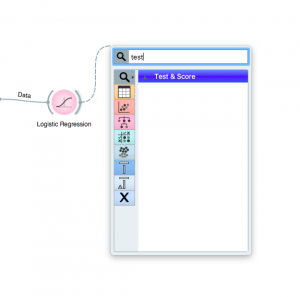 passo 7: Ora, clicca sul widget “Test e punteggio” per vedere come sta andando il tuo modello.
passo 7: Ora, clicca sul widget “Test e punteggio” per vedere come sta andando il tuo modello.
passo 8: Per visualizzare meglio i risultati, trascina e rilascia dal widget “Test e punteggio” trovare “Matrice di confusione”.
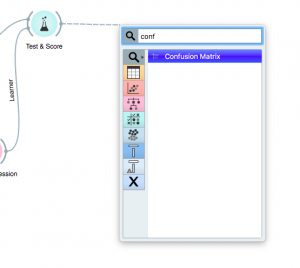
passo 9: Una volta posizionato, cliccaci sopra per vedere i tuoi risultati.
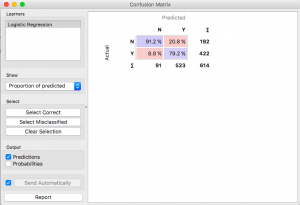
In questo modo, puoi provare diversi modelli e vedere con che precisione funzionano.
Proviamo a valutare, Come funzionerebbe una foresta casuale?? Cambia il metodo di modellazione in Random Forest e guarda la matrice di confusione.
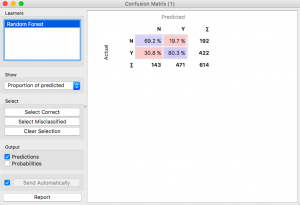
Sembra decente, ma la regressione logistica ha funzionato meglio.
Possiamo riprovare con una macchina vettoriale di supporto.
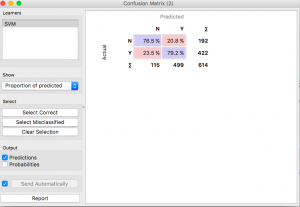
Meglio della foresta casuale, ma ancora non buono come il modello di regressione logistica.
Qualche volta, i metodi più semplici sono i migliori, Non è così?
Ecco come sarebbe il tuo flusso di lavoro finale una volta terminato l'intero processo.
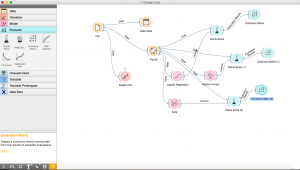
Per chi vuole lavorare in gruppo, possono anche esportare i tuoi flussi di lavoro e inviarli ad amici che possono lavorare al tuo fianco.
Il file risultante ha l'estensione (.come) e può essere aperto in qualsiasi altra configurazione Orange.
Note finali
Orange è una piattaforma che può essere utilizzata per quasi tutti i tipi di analisi, ma la cosa più importante, per immagini belle e facili. In questo articolo, esploriamo come visualizzare un set di dati. È stato anche eseguito un modello predittivo, utilizzando un predittore di regressione logistica, SVM e un predittore forestale casuale per trovare lo stato del prestito per ogni persona di conseguenza.
Spero che questo tutorial ti abbia aiutato a scoprire aspetti del problema che potresti non aver capito o che non hai capito prima. È molto importante comprendere la pipeline della scienza dei dati e i passaggi che intraprendiamo per addestrare un modello, E questo dovrebbe sicuramente aiutarti a costruire presto modelli predittivi migliori!!





