Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
“Fa parte del tirocinio di editor di contenuti”
“Ogni volta che vado al cinema, è magico, non importa cosa sia”. – Steven Spielberg
Tutti amano i film, indipendentemente dalla tua età, sesso, corsa, colore o posizione geografica. Tutti, in qualche modo, siamo collegati gli uni agli altri attraverso questo incredibile mezzo. tuttavia, la cosa più interessante è il fatto che unico le nostre scelte e combinazioni sono in termini di preferenze sui film. Ad alcune persone piacciono i film di genere specifico, o suspense, romanticismo o fantascienza, mentre altri si concentrano sui principali attori e registi. Quando teniamo conto di tutto questo, è incredibilmente difficile generalizzare un film e dire che piacerebbe a tutti. Ma con tutto quello che ha detto, Si vede ancora che film simili piacciono a una parte specifica della società.
Quindi questo è dove noi, come scienziati dei dati, entriamo in gioco ed estraiamo il succo da tutto modelli di comportamento non solo dal pubblico ma anche dai film stessi. Quindi, senza più preamboli, passiamo subito alle basi di un sistema di raccomandazione.
Che cos'è un sistema di raccomandazione?
Basta mettere un Sistema di raccomandazione è un programma di filtraggio il cui obiettivo principale è quello di prevedere il “qualificazione” o la “preferenza” da un utente a uno specifico elemento o elemento del dominio. Nel nostro caso, questo elemento specifico del dominio è un film, così, l'obiettivo principale del nostro sistema di raccomandazione è filtrare e prevedere solo quei film che un utente preferirebbe dati alcuni dati sull'utente stesso.
-
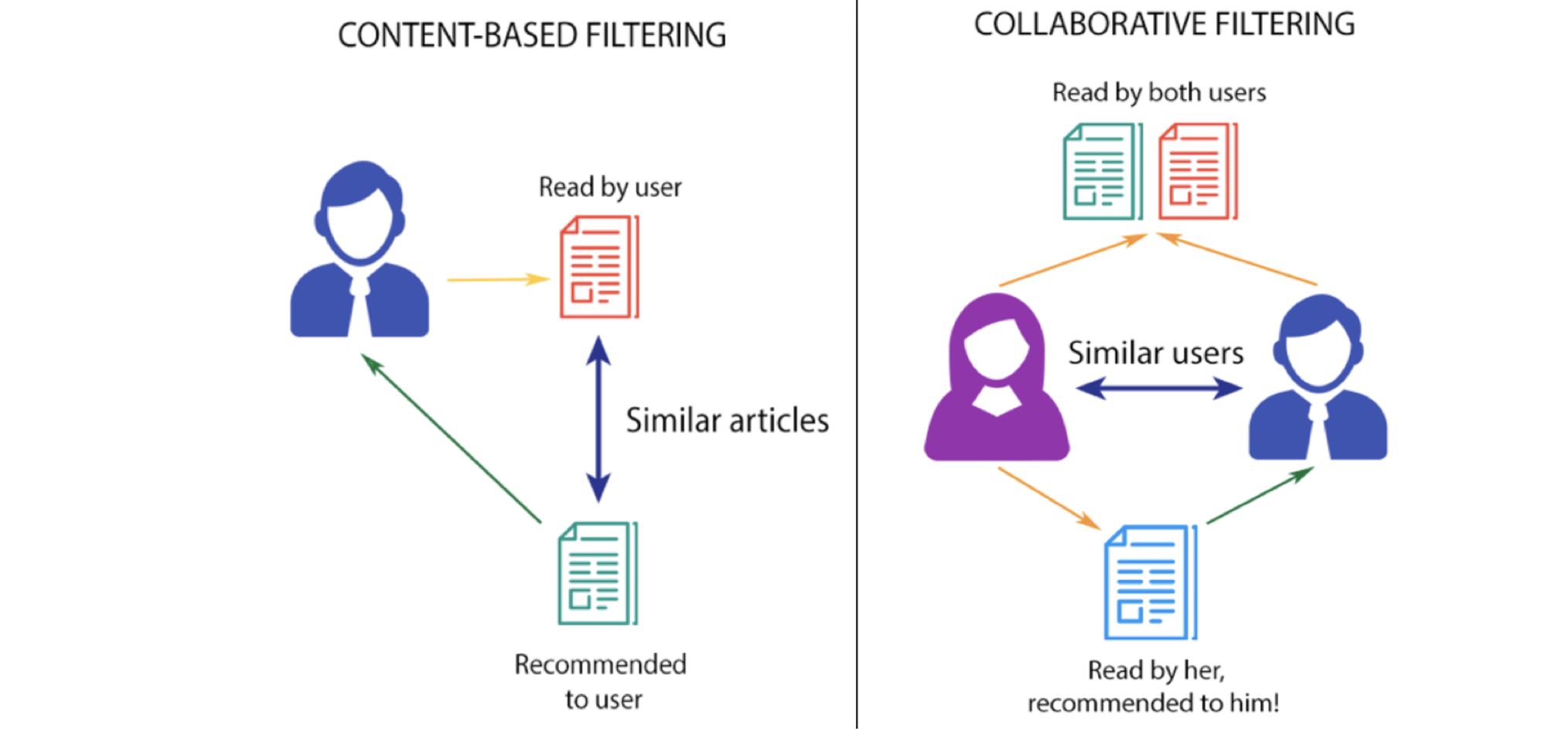
filtraggio basato sul contenuto
Questa strategia di filtraggio si basa sui dati forniti sugli articoli. L'algoritmo consiglia prodotti che sono simile a cui è piaciuto un utente nel Ultimo. Questa somiglianza (somiglianza generalmente coseno) è calcolato dai dati che abbiamo sugli elementi, così come le preferenze passate dell'utente.
Ad esempio, se a un utente piacciono film come "The Prestige"’ allora possiamo consigliarti i "film di Christian Bale"’ o film del genere 'Thriller’ o forse anche film diretti da "Christopher Nolan". Il sistema di raccomandazione controlla le preferenze passate dell'utente e trova il film “Il prestigio”, luego intenta encontrar películas similares a la que utiliza la información disponible en la Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti...., come i principali attori, direttore, il genere del film, la casa di produzione, ecc y, sulla base di queste informazioni, Cerca film come "The Prestige".
Svantaggi
- Prodotti diversi non ottengono molto esposizione all'utente.
- Le attività non possono essere espanse perché l'utente non ci prova diversi tipi di prodotti.
-
Filtraggio collaborativo
Questa strategia di filtraggio si basa sulla combinazione del comportamento dell'utente e sul confronto e contrasto con Altri utenti comportamento nel database. La storia di tutti gli utenti gioca un ruolo importante in questo algoritmo. La principale differenza tra il filtraggio basato sul contenuto e il filtraggio collaborativo è che in quest'ultimo, il interazione di tutti gli utenti con gli articoli influenza l'algoritmo di raccomandazione, mentre solo per il filtro basato sul contenuto dati dell'utente interessato è preso in considerazione.
Esistono diversi modi per implementare il filtraggio collaborativo, ma il concetto principale da capire è quello nel filtraggio collaborativo multiplo I dati dell'utente influenzano l'esito della raccomandazione. e non dipende da solo un dato utente modellare.
Ci sono 2 tipi di algoritmi di filtraggio collaborativo:
-
Filtraggio collaborativo basato sull'utente
L'idea di base qui è trovare utenti che hanno modelli di preferenza precedenti simili In che modo l'utente 'A’ e poi consiglia gli articoli che sono piaciuti a quegli utenti simili a 'A’ ancora non l'ho trovato. Questo si ottiene facendo a serie di elementi che ogni utente ha valutato, visto, mi piace o cliccato a seconda del compito da svolgere, e quindi calcolare il punteggio di somiglianza tra gli utenti e infine consigliare elementi che l'utente in questione non conosce, ma quello ad utenti simili a lui / gli piace.
Ad esempio, sì all'utente 'A’ gli piace "Batman Begins", 'Lega della Giustizia’ e "I Vendicatori"’ mentre l'utente 'B’ gli piace "Batman Begins", 'Lega della Giustizia’ e 'Thor', quindi hanno interessi simili perché sappiamo che questi film appartengono al genere dei supereroi. Perciò, c'è un'alta probabilità che l'utente 'A’ come 'Thor’ e all'utente 'B’ ti piace "The Avengers".
Svantaggi
- Le persone sono volubile vale a dire, il tuo gusto cambia di volta in volta e poiché questo algoritmo si basa sulla somiglianza dell'utente, in grado di rilevare modelli di somiglianza iniziale tra 2 utenti che dopo un po' potrebbero avere preferenze completamente diverse.
- Ci sono molti più utenti che elementi così, è molto difficile mantenere matrici così grandi e, così, devono essere ricalcolati molto regolarmente.
- Questo algoritmo è molto suscettibile a attacchi di scellini dove falsi profili utente costituiti da schemi di preferenza distorti vengono utilizzati per manipolare decisioni chiave.
-
Filtraggio collaborativo basato su elementi
Il concetto in questo caso è cerca film simili invece di utenti simili e poi consigliare film simili a quelli che 'A’ ha avuto in passato le tue preferenze. Questo viene fatto trovando ogni coppia di elementi che sono stati valutati / visti / gli piaccio / cliccato dallo stesso utente, quindi misurare la somiglianza di quelli valutati / visti / è piaciuto / cliccato su tutti gli utenti che hanno valutato / loro videro / Mi piacevano / hanno cliccato su entrambi, e infine consigliandoli in base ai punteggi di somiglianza.
Qui, ad esempio, prendiamo 2 film A’ e B’ e controlliamo le tue valutazioni da tutti gli utenti che hanno valutato entrambi i film e in base alla somiglianza di queste valutazioni, e in base a questa somiglianza di valutazione da parte degli utenti che hanno valutato entrambi, troviamo film simili. Quindi, se gli utenti più comuni hanno valutato 'A’ e B’ allo stesso modo ed è altamente probabile che 'A’ e B’ sono simili, così, se qualcuno ha visto e apprezzato 'A', dovrebbe essere raccomandato 'B’ e viceversa.
Vantaggi rispetto al filtraggio collaborativo basato sull'utente
- A differenza del gusto della gente, i film non cambiano.
- Di solito ce ne sono molti meno articoli che persone, così, è più facile mantenere e calcolare le matrici.
- Gli attacchi con lo scellino sono molto più difficili perché gli articoli non possono essere contraffatti.
-
Iniziamo a codificare il nostro sistema di consigli sui film.
In questa implementazione, quando l'utente cerca un film, raccomanderemo il 10 i migliori film simili usando il nostro sistema di consigli sui film. Noi useremo filtraggio collaborativo basato su elementi algoritmo per il nostro scopo. Il set di dati utilizzato in questa dimostrazione è il movielens-piccolo set di dati.
Metti i dati al lavoro
Primo, dobbiamo importare le librerie che utilizzeremo nel nostro sistema di consigli sui film. Cosa c'è di più, importeremo il dataset aggiungendo il percorso del CSV record.
importare panda come pd import numpy as np from scipy.sparse import csr_matrix from sklearn.neighbors import NearestNeighbors import matplotlib.pyplot as plt import seaborn as sns movies = pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv") valutazioni = pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")
Ahora que hemos agregado los datos, echemos un vistazo a los archivos usando el dataframe.head () comando para imprimir las primeras 5 filas del conjunto de datos.
Echemos un vistazo al conjunto de datos de películas:
movies.head()
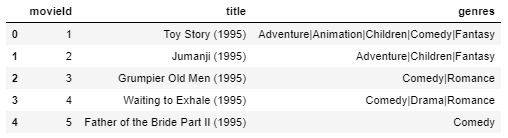
El conjunto de datos de la película tiene
- movieId: una vez que se realiza la recomendación, obtenemos una lista de todos los movieId similares y obtenemos el título de cada película de este conjunto de datos.
- géneros – Che cos'è no requerido para este enfoque de filtrado.
ratings.head()
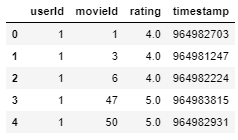
Il set di dati delle valutazioni ha
- ID utente: unico per ogni utente.
- movieId: con questa funzione, prendiamo il titolo del film dal set di dati del film.
- valutazione – Valutazioni date da ciascun utente a tutti i film che utilizzano questo, stiamo per prevedere il 10 i migliori film simili.
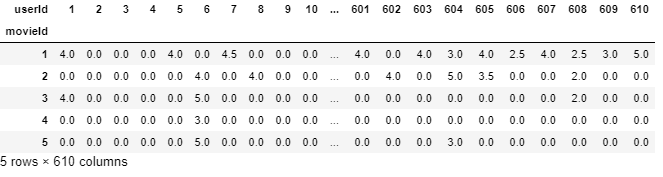
Qui, possiamo vedere che userId 1 avere Visto movieId 1 e 3 ed entrambi hanno segnato con 4.0, ma ha Non valutato movieId 2 assolutamente. Questa interpretazione è più difficile per estrarre da questo frame di dati. Perciò, per rendere le cose più facili da capire e con cui lavorare, creeremo un nuovo frame di dati in cui ogni colonna rappresenterebbe ogni ID utente univoco e ogni riga rappresenterebbe ogni ID film univoco.
final_dataset = ratings.pivot(index='movieId',colonne="ID utente",valori="valutazione") final_dataset.head()
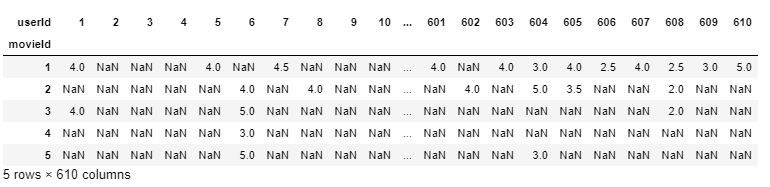
Ora, è molto più facile da interpretare rispetto a userId 1 ID film valutato 1 & 3 4.0 ma non ha valutato movieId 3,4,5 assolutamente (così, sono rappresentati come NaN) e, così, mancano i tuoi dati di valutazione.
Risolviamo questo e imputare NaN con 0 per rendere le cose comprensibili all'algoritmo e anche rendere i dati più rassicuranti alla vista.
final_dataset.fillna(0,inplace=Vero) final_dataset.head()
Rimuovi il rumore dai dati
Nel mondo reale, i voti sono molto scarso e i punti dati vengono raccolti principalmente da very film popolari e utenti molto coinvolti. Non vogliamo film che sono stati valutati da un piccolo numero di utenti perché lo è non credibile abbastanza. Nello stesso modo, utenti che hanno valutato solo una manciata di film non va neanche preso in considerazione.
Quindi, con tutto ciò che è stato preso in considerazione e alcuni esperimenti per tentativi ed errori, ridurremo il rumore aggiungendo alcuni filtri per il set di dati finale.
- Per valutare un film, un minimo di 10 gli utenti avrebbero dovuto votare un film.
- Per valutare un utente, un minimo di 50 i film avrebbero dovuto votare per l'utente.
Vediamo come sono questi filtri
Aggiungendo il numero di utenti che hanno votato e il numero di film che sono stati votati.
no_user_voted = ratings.groupby('ID film')['valutazione'].agg('contare')
no_movies_voted = ratings.groupby('ID utente')['valutazione'].agg('contare')
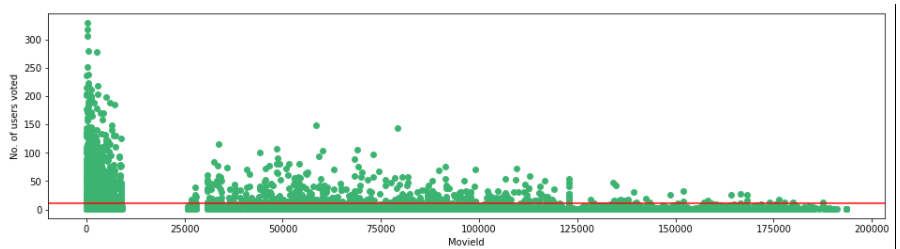
Visualizziamo il numero di utenti che hanno votato con la nostra soglia di 10.
F,ax = plt.sottotrame(1,1,figsize=(16,4))
# giudizi['valutazione'].complotto(bambino = 'storico')
plt.scatter(no_user_voted.index,no_user_voted,colore="medioseagreen")
plt.axhline(y = 10, colore ="R")
plt.xlabel("ID film")
plt.ylabel('No. degli utenti votati')
plt.mostra()
Apportare le modifiche necessarie secondo la soglia stabilita.
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].indice,:]
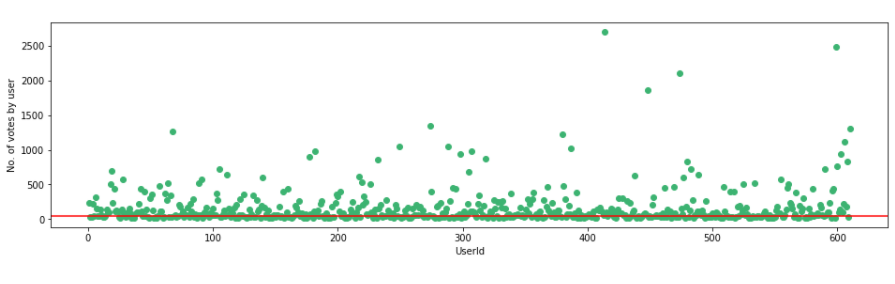
Visualizziamo il numero di voti di ogni utente con la nostra soglia di 50.
F,ax = plt.sottotrame(1,1,figsize=(16,4))
plt.scatter(no_movies_voted.index,no_movies_voted,colore="medioseagreen")
plt.axhline(y = 50, colore ="R")
plt.xlabel('ID utente')
plt.ylabel('No. di voti per utente')
plt.mostra()
Effettuare le modifiche necessarie secondo la soglia stabilita.
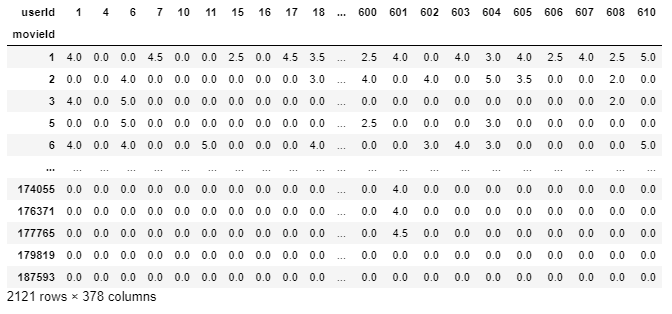
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].indice] set_data_finale
Elimina la carenza
Il nostro final_dataset ha dimensioni di 2121 * 378 dove la maggior parte dei valori sono scarsi. Stiamo usando solo un piccolo set di dati, ma per il set di dati originale dell'obiettivo a pellicola di grandi dimensioni che ha più di 100000 caratteristiche, il nostro sistema potrebbe esaurire le risorse computazionali quando alimentato al modello. Per ridurre la dispersione usiamo la funzione csr_matrix dalla libreria scipy.
Farò un esempio di come funziona:
campione = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]]) scarsità = 1.0 - ( np.count_nonzero(campione) / galleggiante(misura di prova) ) Stampa(scarsità)

csr_sample = csr_matrix(campione) Stampa(csr_campione)

Come potete vedere, no hay un valor escaso en csr_sample y los valores se asignan como indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... de filas y columnas. per la fila 0 e la seconda colonna, il valore è 3.
Applicazione del metodo csr_matrix al set di dati:
csr_data = csr_matrix(final_dataset.values) final_dataset.reset_index(inplace=Vero)
Modella il sistema di consigli sui film
Useremo l'algoritmo KNN per calcolare la somiglianza con distanza coseno metrica che è molto veloce e più preferibile di coefficiente di Pearson.
knn = Vicini più vicini(metrica="coseno", algoritmo='bruto', n_vicini=20, n_jobs=-1) knn.fit(csr_data)
Fare la funzione di raccomandazione
Il principio di funzionamento è molto semplice. Per prima cosa controlliamo se la voce del nome del film è nel database y si lo es usamos nuestro sistema de recomendaciones para encontrar películas similares y ordenarlos en función de su distancia de similitud y generar solo el superiore 10 películas con sus distancias de la película de entrada.
def get_movie_recommendation(movie_name): n_movies_to_reccomend = 10 movie_list = movies[movies['titolo'].str.contiene(movie_name)] se len(movie_list): movie_idx= movie_list.iloc[0]['ID film'] movie_idx = final_dataset[set_data_finale['ID film'] == movie_idx].indice[0] distanze , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1) rec_movie_indices = sorted(elenco(cerniera lampo(indices.squeeze().elencare(),distances.squeeze().elencare())),key=lambda x: X[1])[:0:-1] recommend_frame = [] for val in rec_movie_indices: movie_idx = final_dataset.iloc[valore[0]]['ID film'] idx = movies[movies['ID film'] == movie_idx].index recommend_frame.append({'Title':movies.iloc[idx]['titolo'].valori[0],'Distance':valore[1]}) df = pd.DataFrame(recommend_frame,indice=intervallo(1,n_movies_to_reccomend+1)) return df else: Restituzione "No movies found. Please check your input"
¡Finalmente, recomendaremos algunas películas!
get_movie_recommendation('Uomo di ferro')
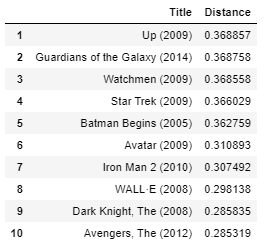
Personalmente, Penso che i risultati siano abbastanza buoni. Tutti i film in alto sono supereroe o animazione film ideali per bambini come il film d'ingresso “Uomo di ferro”.
Proviamo un altro:
get_movie_recommendation('ricordo')
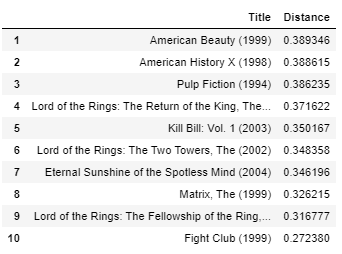
Tutti i migliori film 10 figlio serio e coscienzioso film come "Memento" stesso, quindi penso che il risultato, in questo caso, È anche buono.
Il nostro modello funziona abbastanza bene: un sistema di raccomandazione di film basato sul comportamento dell'utente. Perciò, concludiamo qui il nostro filtraggio collaborativo. Puoi ottenere il blocco note di distribuzione completo qui.





