Panoramica
- Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
- Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data..
introduzione
Attualmente, Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data. 4 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.. Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data., Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.:
9.176 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
1.023 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
5.036 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
86,497 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
86,302 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
2.957.983 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.
Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.: Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.! Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data. 2020 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data. 44 Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data.. Hadoop è tra gli strumenti più popolari nell'ingegneria dei dati e nello spazio Big Data. 44 * 10 ^ 21!
Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data.. Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data. 40 anni. Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data., Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data., Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data..

Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data., chiamata Ecosistema HadoopEl ecosistema Hadoop es un marco de trabajo de código abierto diseñado para el procesamiento y almacenamiento de grandes volúmenes de datos. Se compone de varios componentes clave, como Hadoop Distributed File System (HDFS) para almacenamiento y MapReduce para procesamiento. Cosa c'è di più, incluye herramientas complementarias como Hive, Pig y HBase, que facilitan la gestión, análisis y consulta de datos. Este ecosistema es fundamental en el ámbito del Big Data y la.... Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data., Questa enorme quantità di dati generata a un ritmo feroce e in tutti i tipi di formati è ciò che oggi chiamiamo Big Data..
Quindi, in questo articolo, cercheremo di capire questo ecosistema e scomporre le sue componenti.
Sommario
- Problema con i sistemi tradizionali
- Cos'è Hadoop??
- Componenti dell'ecosistema Hadoop
- HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni.. (sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop)
- Mappa piccola
- HILO
- HBaseHBase è un database NoSQL progettato per gestire grandi volumi di dati distribuiti in cluster. In base al modello a colonne, Consente un accesso rapido e scalabile alle informazioni. HBase si integra facilmente con Hadoop, il che lo rende una scelta popolare per le applicazioni che richiedono un'elevata quantità di archiviazione ed elaborazione dei dati. La sua flessibilità e capacità di crescita lo rendono ideale per i progetti di big data....
- Maiale
- Alveare
- SqoopSqoop es una herramienta de código abierto diseñada para facilitar la transferencia de datos entre bases de datos relacionales y el ecosistema Hadoop. Permite la importación de datos desde sistemas como MySQL, PostgreSQL y Oracle a HDFS, así como la exportación de datos desde Hadoop a estas bases de datos. Sqoop optimiza el proceso mediante la paralelización de las operaciones, lo que lo convierte en una solución eficiente para el...
- canale artificiale
- Kafka
- guardiano dello zoo
- Scintilla – scintilla
- Fasi del trattamento dei Big Data
Problema con i sistemi tradizionali
Per sistemi tradizionali, Mi riferisco a sistemi come database relazionali e data warehouse. Le organizzazioni li hanno usati per l'ultimo 40 anni per archiviare e analizzare i tuoi dati. Ma i dati che vengono generati oggi non possono essere gestiti da questi database per i seguenti motivi:
- La maggior parte dei dati generati oggi è semistrutturata o non strutturata. Ma i sistemi tradizionali sono stati progettati per gestire solo dati strutturati con righe e colonne ben progettate.
- I database delle relazioni sono scalabili verticalmente, il che significa che è necessario aggiungere più elaborazione, memoria e archiviazione sullo stesso sistema. Questo può essere molto costoso
- I dati archiviati oggi sono in diversi silos. Raccoglierli e analizzarli per i modelli può essere un compito molto difficile..
Quindi, come gestiamo i big data? È qui che entra in gioco Hadoop!!
Cos'è Hadoop??
Le persone di Google hanno anche affrontato le sfide sopra menzionate quando volevano classificare le pagine su Internet.. Hanno scoperto che i database relazionali erano molto costosi e poco flessibili. Quindi, hanno escogitato la loro nuova soluzione. Hanno creato il file system di google (GFS).
GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali. GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali, GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali. GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali Apache Hadoop.
GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali. GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali.
GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali:
- GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali
- GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali, GFS è un file system distribuito che supera gli svantaggi dei sistemi tradizionali scala orizzontale
- Crea e salva repliche di dati in questo modo tollerante agli errori
- Questo economico ya que todos los nodos del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... son hardware básico que no es más que máquinas económicas
- Hadoop usa il concetto di località dei dati per elaborare i dati sui nodi in cui sono archiviati invece di spostare i dati attraverso la rete, riducendo così il traffico
- Maggio gestire qualsiasi tipo di dato: strutturato, semistrutturato e non strutturato. Questo è estremamente importante oggi perché la maggior parte dei nostri dati (email, Instagram, Twitter, Dispositivi IoT, eccetera.) non hanno un formato definito.
Ora, vediamo i componenti dell'ecosistema Hadoop.
Componenti dell'ecosistema Hadoop
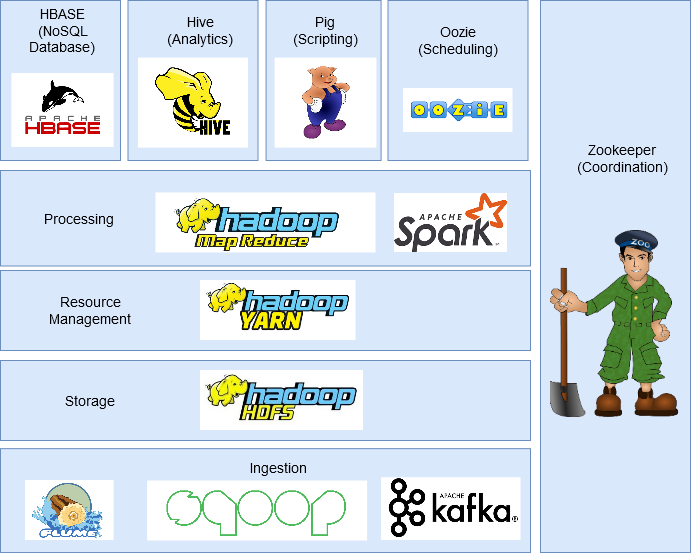
In questa sezione, discuteremo le diverse componenti dell'ecosistema Hadoop.
HDFS (File system distribuito Hadoop)

È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file..
È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file. 128 MB (È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file.) È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file..
È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file.: NodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... de nombre y Nodo de datos.
- È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file. È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file.. È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file..
- È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file. è lui nodo esclavoIl "nodo esclavo" es un concepto utilizado en redes y sistemas distribuidos que se refiere a un dispositivo o componente que opera bajo la dirección de un nodo principal o "nodo maestro". Este tipo de arquitectura permite una gestión centralizada, donde el nodo esclavo ejecuta tareas específicas, recopilando datos o ejecutando procesos, mientras el nodo maestro coordina las operaciones de todo el sistema para optimizar el rendimiento y la eficiencia.... que almacena los bloques de datos y hay más de uno por clúster. È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file.. È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file..
Mappa piccola

È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file., È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file. È il componente di archiviazione di Hadoop che memorizza i dati sotto forma di file. Introdotto da Google e semplifica la distribuzione di un lavoro e l'esecuzione in parallelo su un cluster. Fondamentalmente, dividere una singola attività in più attività ed elaborarle su macchine diverse.
In parole povere, funziona in modo divide et impera ed esegue processi sulle macchine per ridurre il traffico di rete.
Ha due fasi importanti.: Mappa e riduci.
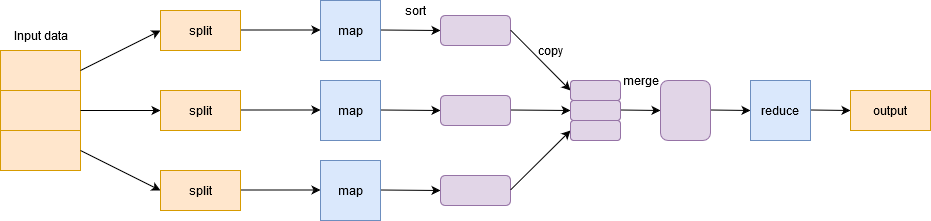
fase cartografica filtro, raggruppare e ordinare i dati. I dati di input sono divisi in multipli divisioni. Ogni attività della mappa funziona su una porzione di dati in parallelo su macchine diverse e genera una coppia chiave-valore. L'uscita di questa fase è azionata dal ridurre il compito ed è conosciuto come il ridurre la fase. Aggiungi i dati, riassumere il risultato e memorizzarlo in HDFS.
HILO

FILATOYARN è un gestore di pacchetti per JavaScript che consente l'installazione e la gestione efficiente delle dipendenze nei progetti di sviluppo. Sviluppato da Facebook, Si caratterizza per la sua velocità e sicurezza rispetto ad altri gestori. YARN utilizza un sistema di cache per ottimizzare le installazioni e fornisce un file di blocco per garantire la coerenza delle versioni delle dipendenze tra i diversi ambienti di sviluppo.... o Yet Another Resource Negotiator administra los recursos en el clúster y administra las aplicaciones a través de Hadoop. hadoop-yarn-1-8796831, hadoop-yarn-1-8796831, hadoop-yarn-1-8796831, hadoop-yarn-1-8796831, hadoop-yarn-1-8796831. hadoop-yarn-1-8796831.
HBase

HBase es una Banca dati NoSQLI database NoSQL sono sistemi di gestione dei dati che si caratterizzano per la loro flessibilità e scalabilità. A differenza dei database relazionali, Utilizzare modelli di dati non strutturati, come documenti, chiave-valore o grafica. Sono ideali per le applicazioni che richiedono la gestione di grandi volumi di informazioni e un'elevata disponibilità, come nel caso dei social network o dei servizi cloud. La sua popolarità è cresciuta in... basada en columnas. hadoop-yarn-1-8796831. hadoop-yarn-1-8796831 / hadoop-yarn-1-8796831.
Maiale

MaialeIl maiale, un mammifero addomesticato della famiglia dei Suidi, È noto per la sua versatilità in agricoltura e nella produzione alimentare. Originario dell'Asia, Il suo allevamento si è diffuso in tutto il mondo. I maiali sono onnivori e hanno un'elevata capacità di adattarsi a vari habitat. Cosa c'è di più, svolgono un ruolo importante nell'economia, Fornitura di carne, cuoio e altri prodotti derivati. Anche la loro intelligenza e il loro comportamento sociale sono ... fue desarrollado para analizar grandes conjuntos de datos y supera la dificultad de escribir mapas y reducir funciones. Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni.: Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni..
Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni.. Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni.. Internamente, el código escrito en Pig se convierte en funciones de Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data.... y lo hace muy fácil para los programadores que no dominan Java.
Alveare

AlveareHive è una piattaforma di social media decentralizzata che consente ai suoi utenti di condividere contenuti e connettersi con gli altri senza l'intervento di un'autorità centrale. Utilizza la tecnologia blockchain per garantire la sicurezza e la proprietà dei dati. A differenza di altri social network, Hive consente agli utenti di monetizzare i propri contenuti attraverso ricompense in criptovalute, che incoraggia la creazione e lo scambio attivo di informazioni.... es un sistema de almacenamiento de datos distribuido desarrollado por Facebook. Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni., Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni.. Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni. (HQL), Pig è stato sviluppato per analizzare grandi set di dati e supera la difficoltà di scrivere mappe e ridurre le funzioni.. Questo rende molto facile per i programmatori scrivere funzioni MapReduce usando semplici query HQL..
Sqoop

Molte applicazioni archiviano ancora i dati in database relazionali, lo que las convierte en una Origine datiUN "Origine dati" si riferisce a qualsiasi luogo o supporto in cui è possibile ottenere informazioni. Queste fonti possono essere sia primarie che, come sondaggi ed esperimenti, come secondario, come banche dati, articoli accademici o rapporti statistici. La scelta corretta di una fonte di dati è fondamentale per garantire la validità e l'affidabilità delle informazioni nella ricerca e nell'analisi.... muy importante. Perciò, Sqoop svolge un ruolo importante nel portare i dati dai database relazionali a HDFS.
I comandi scritti in Sqoop vengono convertiti internamente in attività MapReduce in esecuzione su HDFS. Funziona con quasi tutti i database relazionali come MySQL, Postgres, SQLite, eccetera. Può anche essere utilizzato per esportare dati da HDFS a RDBMS.
canale artificiale

FlumeFlume es un software de código abierto diseñado para la recolección y transporte de datos. Utiliza un enfoque basado en flujos, lo que permite mover datos de diversas fuentes hacia sistemas de almacenamiento como Hadoop. Su arquitectura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... es un servicio de código abierto, affidabile e disponibile che viene utilizzato per raccogliere, aggiungere e spostare in modo efficiente grandi quantità di dati da più origini dati a HDFS. Puoi raccogliere dati in tempo reale e in modalità batch. Ha un'architettura flessibile ed è tollerante ai guasti con più meccanismi di ripristino..
Kafka

Esistono molte app che generano dati e un numero proporzionale di app che consumano tali dati. Ma collegarli individualmente è un compito difficile. È qui che entra in gioco Kafka. È tra le applicazioni che generano dati (produttori) e app che consumano dati (consumatori).
Kafka è distribuito e partizionato, replicaciónLa replicación es un proceso fundamental en biología y ciencia, que se refiere a la duplicación de moléculas, células o información genética. En el contexto del ADN, la replicación asegura que cada célula hija reciba una copia completa del material genético durante la división celular. Este mecanismo es crucial para el crecimiento, desarrollo y mantenimiento de los organismos, así como para la transmisión de características hereditarias en las generaciones futuras.... y tolerancia a fallas incorporados. Può gestire lo streaming di dati e consente inoltre alle aziende di analizzare i dati in tempo reale..
Oozie

OozieOozie es un sistema de gestión de trabajos orientado a flujos de datos, diseñado para coordinar trabajos en Hadoop. Permite a los usuarios definir y programar trabajos complejos, integrando tareas de MapReduce, Maiale, Hive y otros. Oozie utiliza un enfoque basado en XML para describir los flujos de trabajo y su ejecución, facilitando la orquestación de procesos en entornos de big data. Su funcionalidad mejora la eficiencia en el procesamiento... es un sistema de programación de flujo de trabajo que permite a los usuarios vincular trabajos escritos en varias plataformas como MapReduce, Alveare, Maiale, eccetera. Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce. Ad esempio, Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce.
guardiano dello zoo

Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce, Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce. Perciò, guardiano dello zoo"guardiano dello zoo" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales.... es la herramienta perfecta para resolver el problema.
Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce, Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce, Oozie è un sistema di pianificazione del flusso di lavoro che consente agli utenti di collegare lavori scritti su più piattaforme come MapReduce, fornire sincronizzazione distribuita e fornire servizi di gruppo nel cluster.
Scintilla – scintilla

Spark è un framework alternativo a Hadoop basato su Scala, ma supporta varie applicazioni scritte in Java, Pitone, eccetera. Rispetto a MapReduce, fornisce un'elaborazione in memoria che rappresenta un'elaborazione più rapida. Oltre all'elaborazione batch offerta da Hadoop, può anche gestire l'elaborazione in tempo reale.
Cosa c'è di più, Spark ha il suo ecosistema:

- Nucleo Scintilla è il motore di esecuzione principale per Spark e altre API basate su di esso
- API di Spark SQL consente di eseguire query sui dati strutturati archiviati in DataFrames o tabelle Hive
- API di streaming consente a Spark di gestire i dati in tempo reale. Può essere facilmente integrato con una varietà di fonti di dati come Flume, Kafka e Twitter.
- MLlib è una libreria di apprendimento automatico scalabile che ti consentirà di eseguire attività di data science sfruttando contemporaneamente le proprietà di Spark
- GraficoX è un motore di calcolo grafico che consente agli utenti di creare, trasforma e ragiona in modo interattivo su dati strutturati in grafici su larga scala e viene fornito con una libreria di algoritmi comuni
Fasi del trattamento dei Big Data
Con così tanti componenti all'interno dell'ecosistema Hadoop, può essere abbastanza intimidatorio e difficile da capire cosa fa ogni componente. Perciò, è più facile raggruppare alcuni dei componenti in base a dove si trovano nella fase di elaborazione dei Big Data.
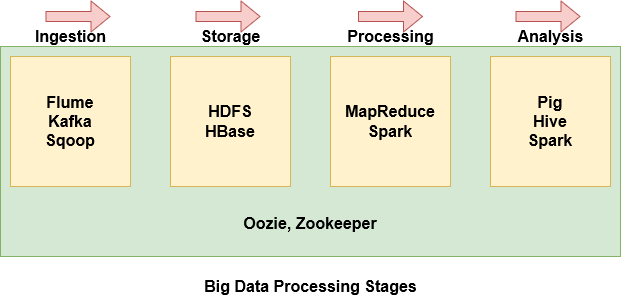
- Flume, big-data-processing-stages-1854353
- big-data-processing-stages-1854353. big-data-processing-stages-1854353
- big-data-processing-stages-1854353
- Maiale, big-data-processing-stages-1854353.
- big-data-processing-stages-1854353. big-data-processing-stages-1854353, big-data-processing-stages-1854353.
- big-data-processing-stages-1854353.
Note finali
big-data-processing-stages-1854353, big-data-processing-stages-1854353.
Ti incoraggio a dare un'occhiata ad altri articoli sui Big Data che potresti trovare utili:





