Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
I vari metodi di apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... Utilizzano i dati per addestrare gli algoritmi delle reti neurali a eseguire una serie di attività di apprendimento automatico, come la classificazione di diverse classi di oggetti. Le reti neurali convoluzionali sono algoritmi di deep learning molto potenti per l'analisi delle immagini. Questo articolo spiegherà come costruire, addestrare e valutare le reti neurali convoluzionali.
Imparerai anche come migliorare la tua capacità di apprendere dai dati e come interpretare i risultati dell'allenamento.. Deep Learning ha diverse applicazioni come l'elaborazione delle immagini, elaborazione del linguaggio naturale, eccetera. Viene utilizzato anche nelle scienze mediche, Media e intrattenimento, Auto Autonome, eccetera.
Cos'è la CNN?
La CNN è un potente algoritmo per l'elaborazione delle immagini. Questi algoritmi sono attualmente i migliori algoritmi che abbiamo per l'elaborazione automatica delle immagini.. Molte aziende usano questi algoritmi per fare cose come identificare gli oggetti in un'immagine.
Le immagini contengono dati di combinazione RGB. Matplotlib può essere usato per importare un'immagine in memoria da un file. Il computer non vede un'immagine, tutto ciò che vedi è una serie di numeri. Le immagini a colori sono memorizzate in array tridimensionali. Le prime due dimensioni corrispondono all'altezza e alla larghezza dell'immagine (il numero di pixel). L'ultimo dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... corrisponde ai colori rosso, verde e blu presenti in ogni pixel.
Tre strati di CNN
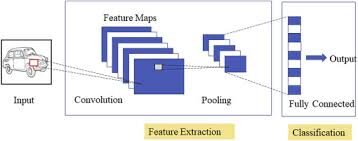
Reti neurali convoluzionali specializzate per applicazioni di riconoscimento di immagini e video. La CNN viene utilizzata principalmente in attività di analisi delle immagini come il riconoscimento delle immagini, rilevamento di oggetti e segmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.....
Ci sono tre tipi di strati nelle reti neurali convoluzionali:
1) copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale..: in un neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. tipico, ogni neurone di input è connesso al livello nascosto successivo. e la CNN, solo una piccola regione dei neuroni del livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche.... Si collega allo strato nascosto dei neuroni.
2) Livello di raggruppamento: il livello di raggruppamento viene utilizzato per ridurre la dimensionalità della mappa delle caratteristiche. Ci saranno più livelli di attivazione e raggruppamento all'interno del livello nascosto della CNN.
3) Strato completamente connesso: Livelli completamente connessi forma l'ultimo copertine In rete. L'ingresso al livello completamente connesso è l'output del raggruppamento o convoluzione finale Copertura frontale, che viene appiattito e poi introdotto nel livello completamente connesso.
Set di dati MNIST
In questo articolo, lavoreremo sul riconoscimento degli oggetti nei dati delle immagini utilizzando il set di dati MNIST per il riconoscimento delle cifre scritte a mano.
Il set di dati MNIST è costituito da immagini di cifre da una varietà di documenti scansionati. Ogni immagine è un quadrato di 28 X 28 pixel. In questo set di dati, sono utilizzati 60.000 immagini per addestrare il modello e 10.000 immagini per testare il modello. Ci sono 10 cifre (0 un 9) oh 10 classi da prevedere.

Caricamento del set di dati MNIST
Installa la libreria TensorFlow e importa il set di dati come addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e test.
Tracciare l'output di esempio dell'immagine
!pip install tensorflow
from keras.datasets import mnist
import matplotlib.pyplot as plt
(X_treno,y_train), (X_test, y_test)= mnist.load_data()
plt.sottotrama()
plt.imshow(X_treno[9], cmap=plt.get_cmap('grigio'))
Produzione:
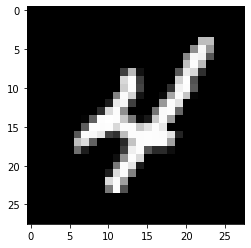
Modello di deep learning con percettroni multistrato con MNIST
In questo modello, creeremo un semplice modello di rete neurale con un singolo livello nascosto per il set di dati MNIST per il riconoscimento delle cifre scritte a mano.
Un percettrone è un modello a singolo neurone che è l'elemento costitutivo di reti neurali più grandi.. Il percettrone multistrato è costituito da tre strati, vale a dire, il livello di input, il livello nascosto e il Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati..... Il livello nascosto non è visibile al mondo esterno. Sono visibili solo il livello di input e il livello di output. Per tutti i modelli DL, I dati devono essere di natura numerica.
passo 1: importare librerie di chiavi
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
passo 2: rimodellare i dati
Ogni immagine ha una dimensione di 28X28, quindi c'è 784 pixel. Quindi, il livello di output ha 10 Partenze, lo strato nascosto ha 784 neuroni e lo strato di input ha 784 Biglietti. Dopo, il set di dati viene convertito in un tipo di dati float.
number_pix=X_train.shape[1]*X_train.shape[2]
X_train=X_train.reshape(X_train.shape[0], numero_pix).come tipo('float32')
X_test=X_test.reshape(X_test.shape[0], numero_pix).come tipo('float32')
passo 3: normalizzare i dati
I modelli NN generalmente richiedono dati in scala. In questo frammento di codice, i dati sono normalizzati da (0-255) un (0-1) E la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... è codificato in un unico utilizzo per un'analisi successiva. La variabile target ha un totale di 10 Lezioni (0-9)
X_train=X_train/255
X_test=X_test/255
y_train= np_utils.to_categorical(y_train)
y_test= np_utils.to_categorical(y_test)
num_classes=y_train.shape[1]
Stampa(num_classi)
Produzione:
10
Ora, Creeremo una funzione NN_model e la compileremo
passo 4: Definire la funzione del modello
def nn_model():
modello=Sequenziale()
modello.aggiungi(Denso(numero_pix, input_dim=number_pix, attivazione = 'rileggere'))
mode.add(Denso(num_classi, attivazione='softmax'))
modello.compila(perdita="categorical_crossentropy", ottimizzatore="Adamo", metriche=['precisione'])
modello di ritorno
Ci sono due livelli, Uno è un livello nascosto con il Funzione di attivazione ReLuLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. è definito come ( F(X) = massimo(0, X) ), il che significa che produce un output pari a zero per i valori negativi e un incremento lineare per i valori positivi. La sua capacità di mitigare il problema dello sbiadimento del gradiente lo rende una scelta preferita nelle architetture profonde.... e l'altro è il livello di output che utilizza il Funzione SoftMaxLa funzione softmax è uno strumento matematico utilizzato nel campo dell'apprendimento automatico, soprattutto nelle reti neurali. Converte un vettore di valore in una distribuzione di probabilità, Assegnazione di probabilità a ciascuna classe in problemi di multi-classificazione. La sua formula normalizza gli output, garantire che la somma di tutte le probabilità sia uguale a uno, consentendo un'interpretazione efficace dei risultati. È essenziale nell'ottimizzazione della....
passo 5: Eseguire il modello
modello=nn_model()
model.fit(X_treno, y_train, validation_data=(X_test,y_test),epoche=10, batch_size=200, verboso=2)
punteggio= modello.valutare(X_test, y_test, verboso=0)
Stampa('L'errore è: %.2F%%'%(100-punto[1]*100))
Produzione:
Epoca 1/10 300/300 - 11S - perdita: 0.2778 - precisione: 0.9216 - val_loss: 0.1397 - val_accuracy: 0.9604 Epoca 2/10 300/300 - 2S - perdita: 0.1121 - precisione: 0.9675 - val_loss: 0.0977 - val_accuracy: 0.9692 Epoca 3/10 300/300 - 2S - perdita: 0.0726 - precisione: 0.9790 - val_loss: 0.0750 - val_accuracy: 0.9778 Epoca 4/10 300/300 - 2S - perdita: 0.0513 - precisione: 0.9851 - val_loss: 0.0656 - val_accuracy: 0.9796 Epoca 5/10 300/300 - 2S - perdita: 0.0376 - precisione: 0.9892 - val_loss: 0.0717 - val_accuracy: 0.9773 Epoca 6/10 300/300 - 2S - perdita: 0.0269 - precisione: 0.9928 - val_loss: 0.0637 - val_accuracy: 0.9797 Epoca 7/10 300/300 - 2S - perdita: 0.0208 - precisione: 0.9948 - val_loss: 0.0600 - val_accuracy: 0.9824 Epoca 8/10 300/300 - 2S - perdita: 0.0153 - precisione: 0.9962 - val_loss: 0.0581 - val_accuracy: 0.9815 Epoca 9/10 300/300 - 2S - perdita: 0.0111 - precisione: 0.9976 - val_loss: 0.0631 - val_accuracy: 0.9807 Epoca 10/10 300/300 - 2S - perdita: 0.0082 - precisione: 0.9985 - val_loss: 0.0609 - val_accuracy: 0.9828 L'errore è: 1.72%
Nei risultati del modello, è visibile all'aumentare del numero di epoche, migliora la precisione. L'errore è da 1,72%, minore è l'errore, maggiore è la precisione del modello.
Modello di rete neurale convoluzionale utilizzando MNIST
In questa sezione, creeremo semplici modelli CNN per MNIST che dimostrino livelli convoluzionali, raggruppare i livelli e abbandonare i livelli.
passo 1: importa tutte le librerie necessarie
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
passo 2: Configurare il seed per la riproducibilità e caricare i dati MNIST
seed=10
np.random.seed(seme)
(X_treno,y_train), (X_test, y_test)= mnist.load_data()
passo 3: Convertire i dati in valori mobili
X_train=X_train.reshape(X_train.shape[0], 1,28,28).come tipo('float32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).come tipo('float32')
passo 4: normalizzare i dati
X_train=X_train/255
X_test=X_test/255
y_train= np_utils.to_categorical(y_train)
y_test= np_utils.to_categorical(y_test)
num_classes=y_train.shape[1]
Stampa(num_classi)
Una classica architettura CNN sembra sotto:
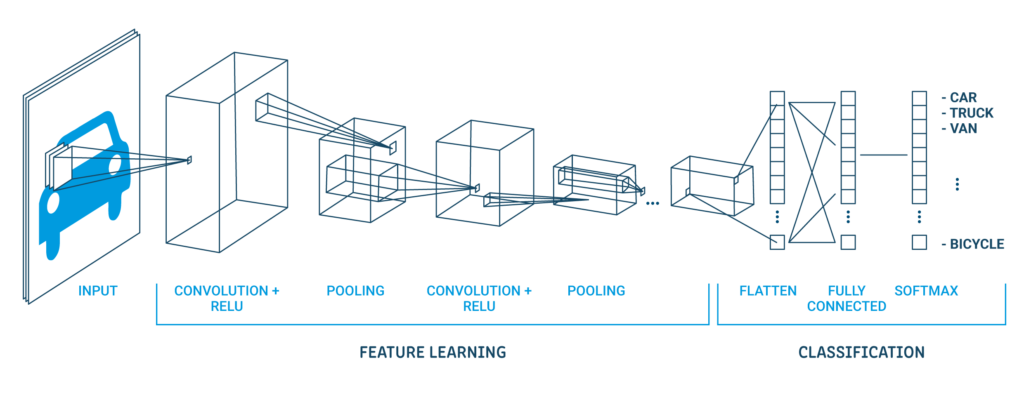
| Livello di output (10 Partenze) |
| Mantello nascosto (128 neuroni) |
| Strato piatto |
| Mantello dell'abbandono 20% |
| Livello di raggruppamento massimo 2 × 2 |
| copertina convolutiva 32 mappe, 5 × 5 |
| Livello visibile 1x28x28 |
Il primo livello nascosto è un livello convoluzionale chiamato Convolution2D. Smaltire 32 mappe di funzionalità con dimensioni 5 × 5 e funzione di macinazione. Questo è il livello di input. Quello che segue è il livello di pooling che assume il valore massimo chiamato MaxPooling2D. In questo modello, è configurato come una dimensione del pool di 2 × 2.
En la capa de abandono ocurre la regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni..... È configurato per escludere casualmente il 20% neuroni di strato per evitare il sovradattamento. Il quinto livello è il livello appiattito che converte i dati della matrice 2D in un vettore chiamato Flatten. Consente l'elaborazione completa dell'output da un livello standard completamente connesso.
Prossimo, lo strato completamente connesso viene utilizzato con 128 neuronas y la funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... del rectificador. Finalmente, il livello di output ha 10 neuroni per 10 classi e una funzione trigger softmax per generare previsioni simili alla probabilità per ogni classe.
passo 5: Eseguire il modello
def cnn_model():
modello=Sequenziale()
modello.aggiungi(Conv2D(32,5,5, imbottitura='uguale',input_shape=(1,28,28), attivazione = 'rileggere'))
modello.aggiungi(MaxPooling2D(pool_size=(2,2), imbottitura='uguale'))
modello.aggiungi(Ritirarsi(0.2))
modello.aggiungi(Appiattire())
modello.aggiungi(Denso(128, attivazione = 'rileggere'))
modello.aggiungi(Denso(num_classi, attivazione='softmax'))
modello.compila(perdita="categorical_crossentropy", ottimizzatore="Adamo", metriche=['precisione'])
modello di ritorno
modello=cnn_model()
model.fit(X_treno, y_train, validation_data=(X_test,y_test),epoche=10, batch_size=200, verboso=2)
punteggio= modello.valutare(X_test, y_test, verboso=0)
Stampa('L'errore è: %.2F%%'%(100-punto[1]*100))
Produzione:
Epoca 1/10 300/300 - 2S - perdita: 0.7825 - precisione: 0.7637 - val_loss: 0.3071 - val_accuracy: 0.9069 Epoca 2/10 300/300 - 1S - perdita: 0.3505 - precisione: 0.8908 - val_loss: 0.2192 - val_accuracy: 0.9336 Epoca 3/10 300/300 - 1S - perdita: 0.2768 - precisione: 0.9126 - val_loss: 0.1771 - val_accuracy: 0.9426 Epoca 4/10 300/300 - 1S - perdita: 0.2392 - precisione: 0.9251 - val_loss: 0.1508 - val_accuracy: 0.9537 Epoca 5/10 300/300 - 1S - perdita: 0.2164 - precisione: 0.9325 - val_loss: 0.1423 - val_accuracy: 0.9546 Epoca 6/10 300/300 - 1S - perdita: 0.1997 - precisione: 0.9380 - val_loss: 0.1279 - val_accuracy: 0.9607 Epoca 7/10 300/300 - 1S - perdita: 0.1856 - precisione: 0.9415 - val_loss: 0.1179 - val_accuracy: 0.9632 Epoca 8/10 300/300 - 1S - perdita: 0.1777 - precisione: 0.9433 - val_loss: 0.1119 - val_accuracy: 0.9642 Epoca 9/10 300/300 - 1S - perdita: 0.1689 - precisione: 0.9469 - val_loss: 0.1093 - val_accuracy: 0.9667 Epoca 10/10 300/300 - 1S - perdita: 0.1605 - precisione: 0.9493 - val_loss: 0.1053 - val_accuracy: 0.9659 L'errore è: 3.41%
Nei risultati del modello, è visibile all'aumentare del numero di epoche, migliora la precisione. L'errore è 3.41%, errore inferiore maggiore precisione del modello.
Spero che ti sia piaciuto leggere e sentiti libero di usare il mio codice per testarlo per i tuoi scopi. Cosa c'è di più, se c'è qualche commento sul codice o solo sul post del blog, non esitate a contattarmi a [e-mail protetta]
I media mostrati in questo articolo sull'elaborazione delle immagini della CNN non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





