Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Nell'elaborazione del linguaggio naturale, l'estrazione delle funzionalità è uno dei passaggi banali da compiere per comprendere meglio il contesto di ciò con cui abbiamo a che fare. Dopo aver pulito e normalizzato il testo iniziale, dobbiamo trasformarlo nelle sue caratteristiche per usarlo nel modellismo. Usiamo un metodo particolare per assegnare pesi a parole particolari all'interno del nostro documento prima di modellarle. Abbiamo optato per la rappresentazione numerica delle singole parole, poiché è facile per il computer elaborare i numeri; in tali casi, abbiamo optato per l'incorporamento di parole.

Fonte: https://www.analyticsvidhya.com/blog/2020/06/nlp-project-information-extraction/
In questo articolo, Discuteremo i vari metodi di incorporamento di parole e di estrazione di caratteristiche che vengono praticati nell'elaborazione del linguaggio naturale..
Estrazione delle caratteristiche:
Borsa di parole:
In questo metodo, prendiamo ogni documento come una raccolta o una borsa che contiene tutte le parole. L'idea è di analizzare i documenti. Il documento qui si riferisce a un'unità. Nel caso volessimo trovare tutti i tweet negativi durante la pandemia, ogni tweet qui è un documento. Per ottenere il sacchetto delle parole eseguiamo sempre tutti quei passaggi precedenti come la pulizia, derivazione, lematizzazione, ecc ... Quindi generiamo un insieme di tutte le parole disponibili prima di inviarlo al modello.
“L'ingresso è la parte migliore del calcio” -> {'iscrizione', 'meglio', 'parte', 'calcio'}
Possiamo ottenere parole ripetute all'interno del nostro documento. Una rappresentazione migliore è una forma vettoriale, che può dirci quante volte ogni parola può apparire in un documento. Quanto segue è chiamato matrice dei termini del documento ed è mostrato di seguito:

Fonte: https://qphs.fs.quoracdn.net/main-qimg-27639a9e2f88baab88a2c575a1de2005
Ci informa sulla relazione tra un documento e i termini. Ciascuno dei valori nella tabella si riferisce al termine frequenza. Per trovare la somiglianza, elegimos la misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de similitud del coseno.
TF-IDF:
Un problema che incontriamo con l'approccio della borsa delle parole è che tratta tutte le parole allo stesso modo, ma in un documento, c'è un'alta probabilità che certe parole vengano ripetute più frequentemente di altre. In un reportage sulla vittoria di Messi in Copa América, la parola Messi sarebbe stata ripetuta più frequentemente. Non possiamo dare a Messi lo stesso peso di qualsiasi altra parola in quel documento. Nel rapporto, se prendiamo ogni frase come un documento, possiamo contare il numero di documenti ogni volta che appare Messi. Questo metodo è chiamato frequenza del documento.
Quindi dividiamo la frequenza del termine per la frequenza del documento di quella parola. Questo ci aiuta con la frequenza di comparsa dei termini in quel documento e inversamente al numero di documenti in cui appare. Perciò, abbiamo il TF-IDF. L'idea è di assegnare pesi particolari alle parole che ci dicono quanto siano importanti nel documento.
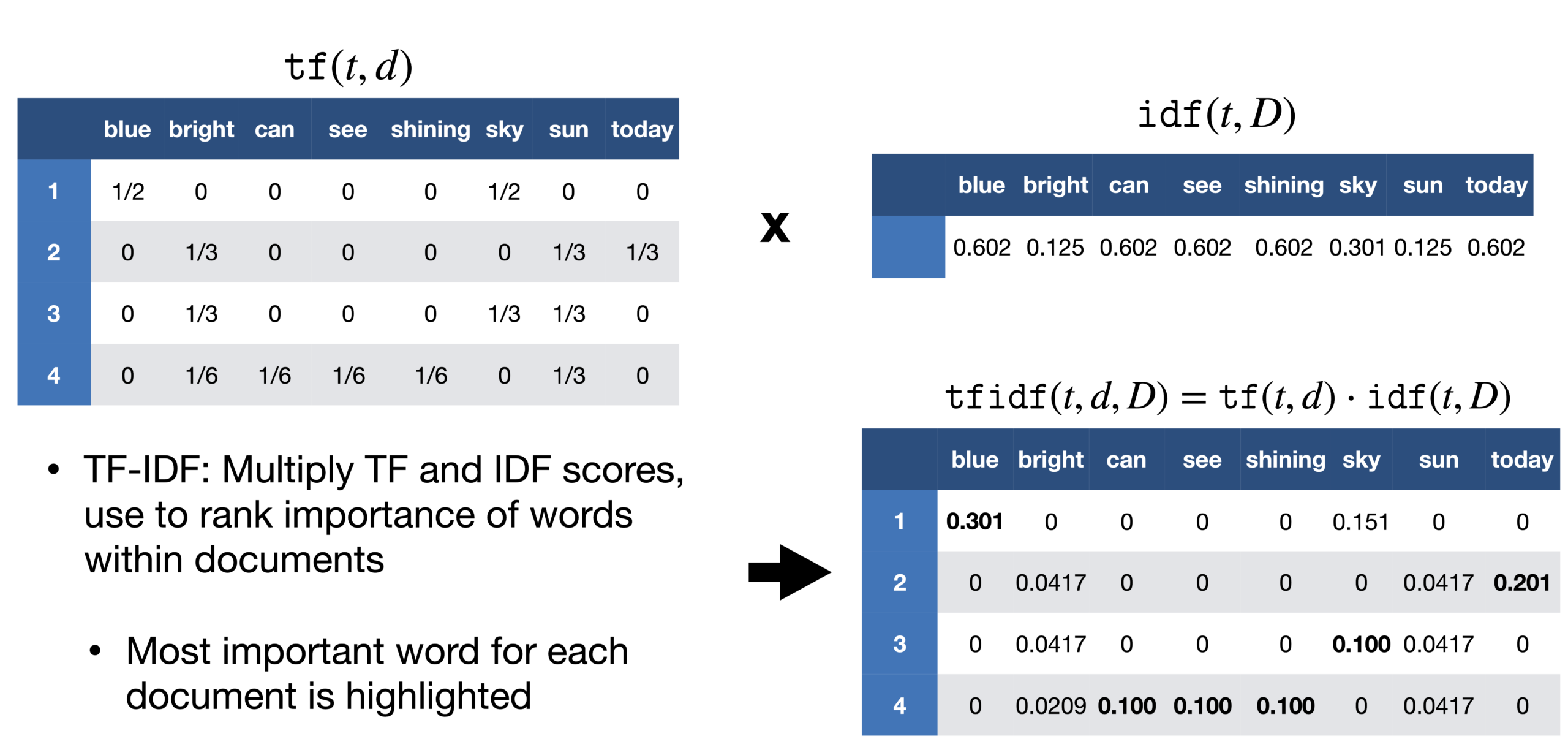
Fonte: https://sci2lab.github.io/ml_tutorial/tfidf/
Codifica one-hot:
Per una migliore analisi del testo che vogliamo elaborare, dobbiamo creare una rappresentazione numerica di ogni parola. Questo può essere risolto utilizzando il metodo di codifica One-hot. Qui trattiamo ogni parola come una classe e in un documento, ovunque sia la parola, noi assegniamo 1 nella tabella e tutte le altre parole in quel documento ottengono 0. Questo è simile alla borsa delle parole, ma qui teniamo ogni parola in una borsa.
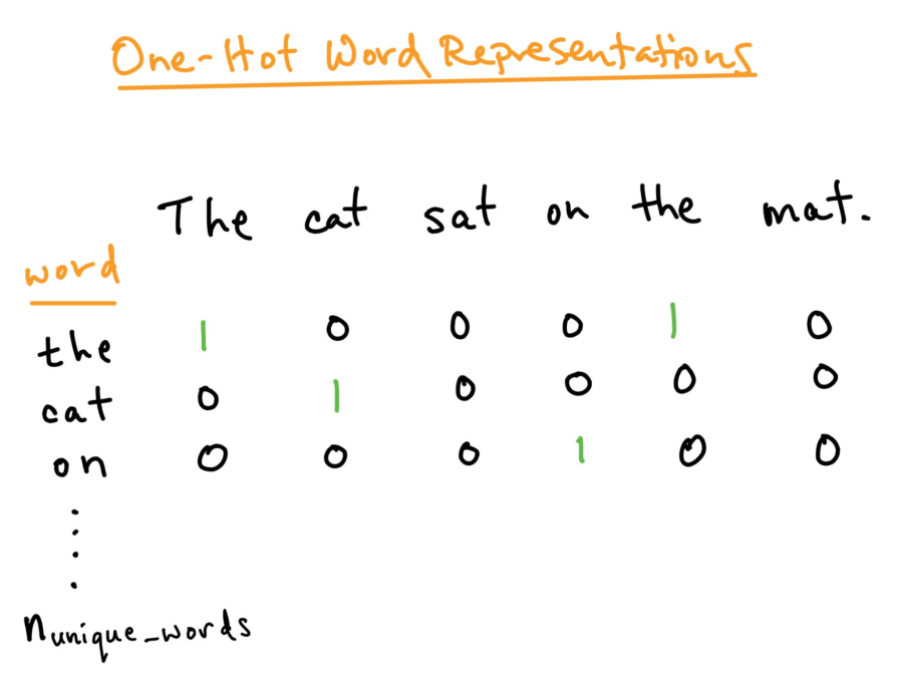
Fonte: https: //versodatascience.com/word-embedding-in-nlp-one-hot-encoding-and-skip-gram-neural-network-81b424da58f2
Incorporamento di parole:
La codifica one-hot funziona bene quando abbiamo un piccolo set di dati. Quando c'è un vocabolario enorme, possiamo codificarlo usando questo metodo poiché la complessità aumenta molto. Abbiamo bisogno di un metodo in grado di controllare la dimensione delle parole che rappresentiamo. Lo facciamo limitandolo a un vettore di dimensione fissa. Vogliamo trovare un intarsio per ogni parola. Vogliamo che ci mostri alcune proprietà. Ad esempio, se due parole sono simili, devono essere più vicini l'uno all'altro nella rappresentazione, e due parole opposte se le loro coppie esistono, entrambi devono avere la stessa differenza di distanza. Questi ci aiutano a trovare i sinonimi, analogie, eccetera.
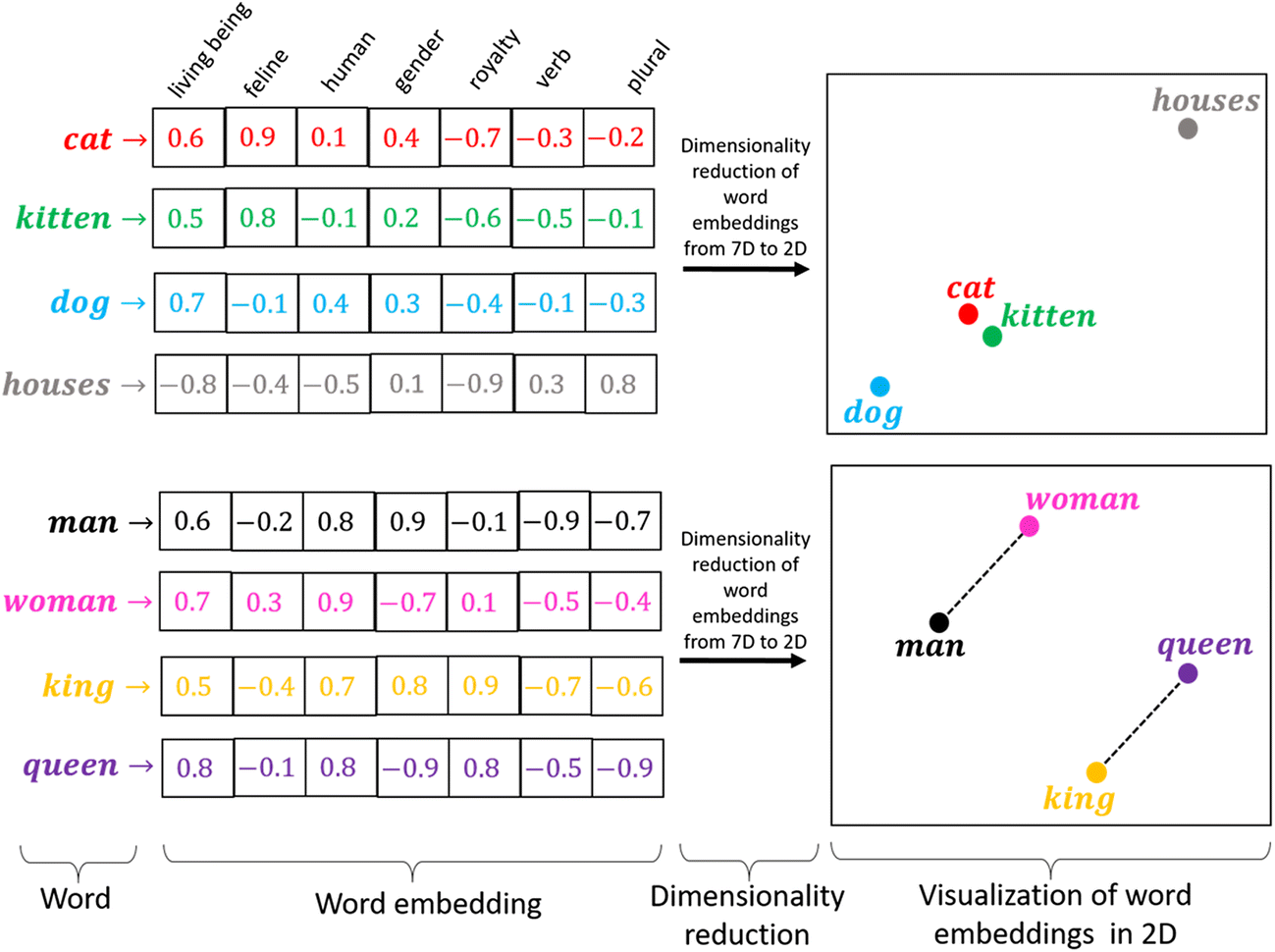
Fonte: https://miro.medium.com/max/1400/1*sAJdxEsDjsPMioHyzlN3_A.png
Parola2Vec:
Word2Vec è ampiamente utilizzato nella maggior parte dei modelli di PNL. Trasforma la parola in vettori. Word2vec è una rete a due livelli che elabora il testo con le parole. L'input è nel corpus di testo e l'output è un insieme di vettori: i vettori delle caratteristiche rappresentano le parole in quel corpus. Si bien Word2vec no es una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. profunda, convertire il testo in una forma di calcolo univoca per reti neurali profonde. Lo scopo e il vantaggio di Word2vec è raccogliere vettori delle stesse parole nello spazio vettoriale. Vale a dire, trova somiglianze matematiche. Word2vec crea vettori che vengono distribuiti utilizzando display numerici di elementi di parole, caratteristiche come il contesto delle singole parole. Lo fa senza intervento umano.
Con abbastanza dati, uso e condizioni, Word2vec può fare le previsioni più accurate sul significato di una parola in base alle apparizioni passate. Quella congettura può essere usata per formare parole e combinazioni di parole (ad esempio, "Grande", vale a dire, "Grande" per dire che "piccolo" è "piccolo"), o raggruppa i testi e separali per argomento. Queste raccolte possono costituire la base per la ricerca, analisi emotiva e raccomandazioni in vari campi, come la ricerca scientifica, scoperta legale, e-commerce e gestione delle relazioni con i clienti. Il risultato della rete Word2vec è un glossario in cui ogni elemento ha un vettore allegato, che può essere incorporato in una rete di lettura profonda o semplicemente chiesto di trovare la relazione tra le parole.
Word2Vec può catturare molto bene il significato contestuale delle parole. Ci sono due gusti. In uno dei metodi, ci vengono date le parole vicine chiamate sacco continuo di parole (CBoW), e in cui ci viene data la parola di mezzo chiamata skip-gram e prevediamo le parole vicine. Una volta ottenuta una serie di pesi precedentemente allenati, possiamo salvarlo e questo può essere utilizzato in seguito per la vettorizzazione delle parole senza la necessità di trasformarlo di nuovo. Li memorizziamo in una tabella di ricerca.
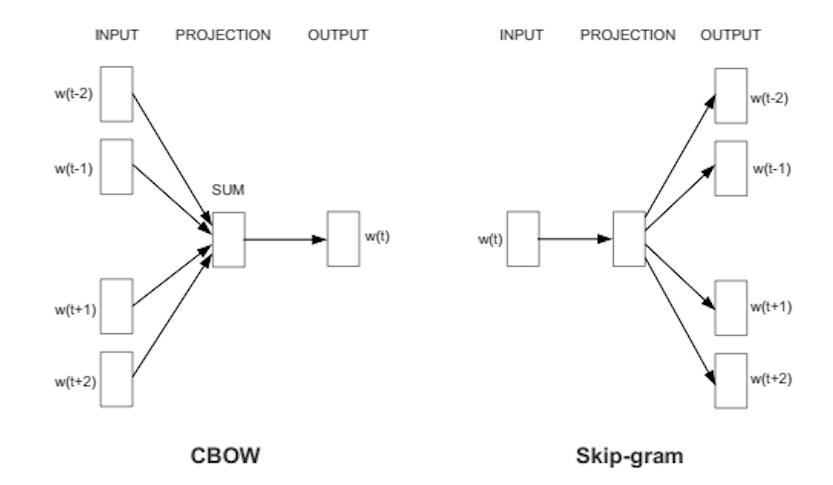
Fonte: https://wiki.pathmind.com/word2vec
Guanto:
Guanto – vettore globale per la rappresentazione della parola. Se utiliza un algoritmo de Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso... de Stanford para generar palabras integradas combinando una matriz de palabras para la co-ocurrencia de palabras de la matriz del corpus. Il testo incorporato pop-up mostra una formattazione di linea attraente per una parola nello spazio vettoriale. Il modello GloVe è addestrato sulla matrice di co-occorrenza globale di livello zero, che mostra quanto spesso le parole si trovano in un particolare corpus. Il completamento di questa matrice richiede un passaggio per l'intera azienda per raccogliere le statistiche. Per un grande corpus, è transazioneIl "transazione" si riferisce al processo mediante il quale avviene uno scambio di merci, servizi o denaro tra due o più parti. Questo concetto è fondamentale in campo economico e giuridico, poiché implica l'accordo reciproco e la considerazione di termini specifici. Le transazioni possono essere formali, come contratti, o informale, e sono essenziali per il funzionamento dei mercati e delle imprese.... puede costar una computadora, ma è una spesa una tantum in futuro. La formazione post-follow-up è molto più veloce perché il numero di voci non di matrice è solitamente molto inferiore al numero totale di voci nel corpus.
Quella che segue è una rappresentazione visiva degli intarsi di parole:
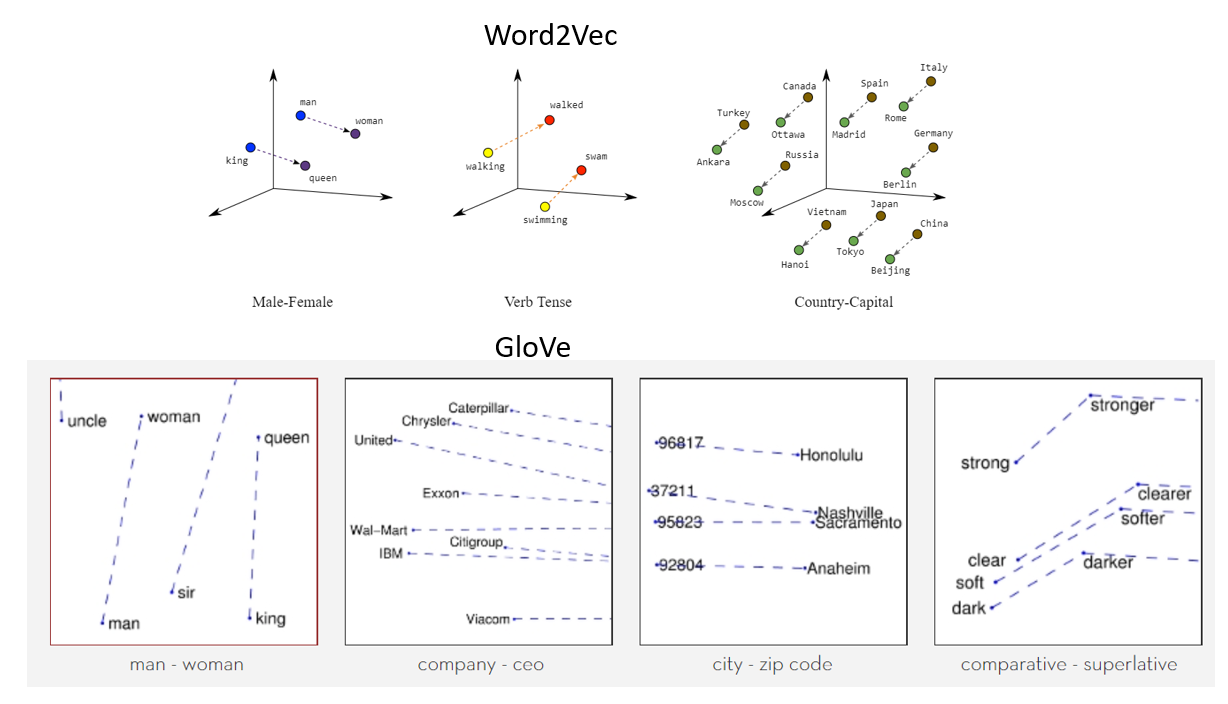
Fonte: https://miro.medium.com/max/1400/1*gcC7b_v7OKWutYN1NAHyMQ.png
Riferimenti:
1. Immagine – https://www.develandoo.com/blog/do-robots-read/
2. https://nlp.stanford.edu/projects/glove/
3. https://wiki.pathmind.com/word2vec
4. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
conclusione:

Fonte: https: //medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
A proposito di me: Soy un estudiante de investigación interesado en el campo del apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... y el procesamiento del lenguaje natural y actualmente estoy realizando un posgrado en Inteligencia Artificial.
Sentiti libero di connetterti con me su:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698





