Panoramica
- Ulteriori informazioni sull'etichettatura delle parti vocali (POS),
- Comprendere l'analisi della dipendenza e l'analisi del distretto
introduzione
La conoscenza delle lingue è la porta della saggezza.
– Ruggero Bacone
Sono rimasto stupito che Ruggero Bacone ha dato la citazione di cui sopra nel XIII secolo, e tiene ancora, Non è così? Sono sicuro che tutti saranno d'accordo con me.
Oggi, il modo di intendere le lingue è molto cambiato dal XIII secolo. Ora lo chiamiamo linguistica ed elaborazione del linguaggio naturale. Ma la sua importanza non è diminuita; Invece, è aumentato enormemente. Tu sai perché? Perchè è Applicazioni sono stati uccisi e uno di questi è il motivo per cui sei atterrato su questo articolo.

Ognuna di queste applicazioni implica complesse tecniche di PNL e, per capirli, è necessaria una buona conoscenza delle basi della PNL. Perciò, prima di passare ad argomenti complessi, è importante mantenere i fondamenti corretti.
Ecco perché ho creato questo articolo in cui tratterò alcuni concetti di base della PNL.: etichettatura di una parte del discorso (POS), Analisi delle dipendenze e analisi distrettuale nell'elaborazione del linguaggio naturale. Comprenderemo questi concetti e li implementeremo anche in Python. Iniziamo!
Sommario
- Etichettare una parte del discorso (POS)
- Analisi delle dipendenze
- Analisi dei collegi elettorali
Etichettare una parte del discorso (POS)
Nei nostri giorni di scuola, tutti abbiamo studiato le parti del discorso, che include nomi, pronomi, aggettivi, verbi, eccetera. Le parole che appartengono a varie parti del discorso formano una frase. Conoscere la parte vocale delle parole in una frase è importante per capirla.
Questa è la ragione per la creazione del concetto di etichettatura POS.. Sono sicuro che ormai avrai indovinato cos'è il tagging POS. Comunque, lasciatemi spiegare.
Etichettare una parte del discorso (POS) è il processo di assegnazione di tag diversi noti come tag POS alle parole in una frase che ci parla della parte vocale della parola.
In termini generali, ci sono due tipi di tag POS:
1. Tag POS universali: Questi tag sono usati nelle dipendenze universali (FUORI) (ultima versione 2), un progetto che sta sviluppando annotazioni treebank coerenti tra le lingue per molte lingue. Questi tag si basano sul tipo di parole. Ad esempio, SOSTANTIVO (nome comune), ADJ (aggettivo), ADV (avverbio).
Elenco etichette POS universale
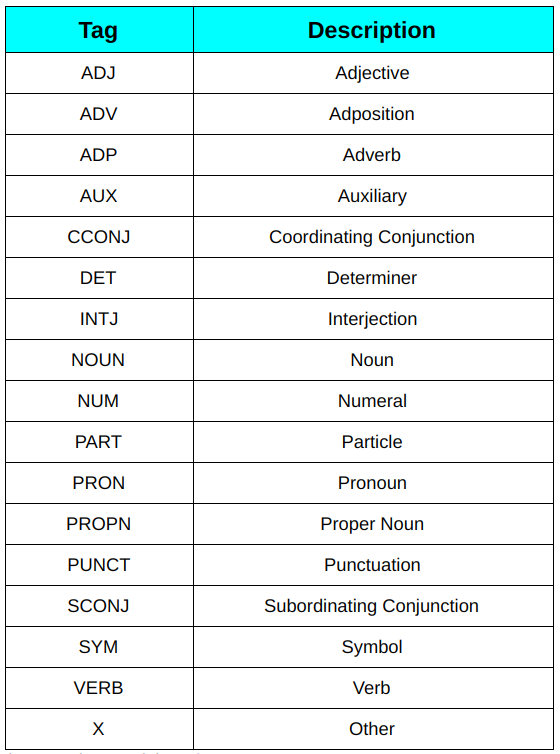
Puoi leggere di più su ciascuno di essi qui.
2. Etichette dettagliate del punto vendita: Queste etichette sono il risultato della divisione delle etichette POS universali in più etichette, come NNS per i nomi comuni al plurale e NN per i nomi comuni al singolare rispetto a NOUN per i nomi comuni in inglese. Questi tag sono specifici della lingua. Puoi dare un'occhiata alla lista completa qui.
Ora sai cosa sono le etichette del punto vendita e cos'è l'etichettatura del punto vendita. Quindi, scriviamo il codice Python per le frasi di tagging POS. Per questo scopo, Ho usato Spacy qui, ma ci sono altre librerie come NLTK e Stanza, che può anche essere usato per fare lo stesso.

Nell'esempio di codice sopra, ho caricato lo spazio it_web_core_sm modello e l'ho usato per ottenere i tag POS. Puoi vedere che pos_ restituisce i tag POS universali, e etichetta_ restituisce tag POS dettagliati per le parole nella frase.
Analisi delle dipendenze
L'analisi delle dipendenze è il processo di analisi della struttura grammaticale di una frase basata sulle dipendenze tra le parole in una frase.
Nell'analisi delle dipendenze, più etichette rappresentano la relazione tra due parole in una frase. Questi tag sono i tag di dipendenza. Ad esempio, nella frase “tempo piovoso”, la parola piovoso modificare il significato del sostantivo clima. Perciò, c'è una dipendenza dal clima -> piovoso in cui il clima comportati come lui testa e il piovoso funge da dipendente oh ragazzo. Questa dipendenza è rappresentata da condizione etichetta, che rappresenta il modificatore dell'aggettivo.
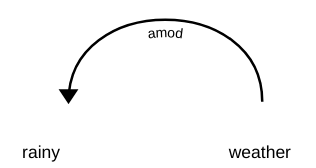
Allo stesso modo, ci sono molte dipendenze tra le parole in una frase, ma nota che una dipendenza coinvolge solo due parole in cui una funge da capo e l'altra funge da bambino. Di seguito, ci sono 37 Relazioni di dipendenza universale utilizzate nella dipendenza universale (versione 2). Puoi dare un'occhiata a tutti qui. A parte questi, ci sono anche molti tag specifici per la lingua.
Ora usiamo Spacy e troviamo le dipendenze in una frase.

Nell'esempio di codice sopra, il dip_ restituisce il tag di dipendenza di una parola e testa di testo restituisce il rispettivo testa parola. Se hai notato, nella foto sopra, la parola prendo ha un tag di dipendenza di RADICE. Questo tag è assegnato alla parola che funge da intestazione per molte parole in una frase, ma non è figlia di nessun'altra parola. In genere, è il verbo principale della frase simile a 'prendere'’ in questo caso.
Ora sai quali tag di dipendenza e quale parola principale, secondario e radice sono. Ma analizzare non significa generare un albero di analisi?
sì, stiamo generando l'albero qui, ma non lo stiamo visualizzando. L'albero generato dall'analisi delle dipendenze è noto come albero delle dipendenze. Ci sono diversi modi per visualizzarlo, ma per semplicità, noi useremo DISLOCAMENTO che viene utilizzato per visualizzare l'analisi delle dipendenze.

Nella foto sopra, le frecce rappresentano la dipendenza tra due parole in cui la parola alla punta della freccia è il bambino e la parola alla fine della freccia è la testa. La radice della parola può fungere da intestazione per più parole in una frase, ma non è figlia di nessun'altra parola. Puoi vedere sopra che la parola "ha preso"’ ha più frecce in uscita ma nessuna in entrata. Perciò, è la radice della parola. Una cosa interessante della parola radice è che se inizi a tracciare le dipendenze in una frase, può arrivare alla radice della parola, non importa da quale parola cominci.
Ora che conosci l'analisi delle dipendenze, Impariamo un altro tipo di analisi noto come analisi costitutiva.
Analisi dei collegi elettorali
L'analisi costitutiva è il processo di analisi delle frasi suddividendole in sottofrasi note anche come costituenti.. Queste sottofrasi appartengono a una specifica categoria grammaticale come NP (frase nominale) il VP (frase verbale).
Capiamo con l'aiuto di un esempio. Supponiamo di avere la stessa frase che ho usato negli esempi precedenti, vale a dire, “Mi ci sono volute più di due ore per tradurre alcune pagine dall'inglese”. e ho eseguito un'analisi elettorale su di esso. Quindi, l'albero di analisi costitutivo di questa frase è dato da:
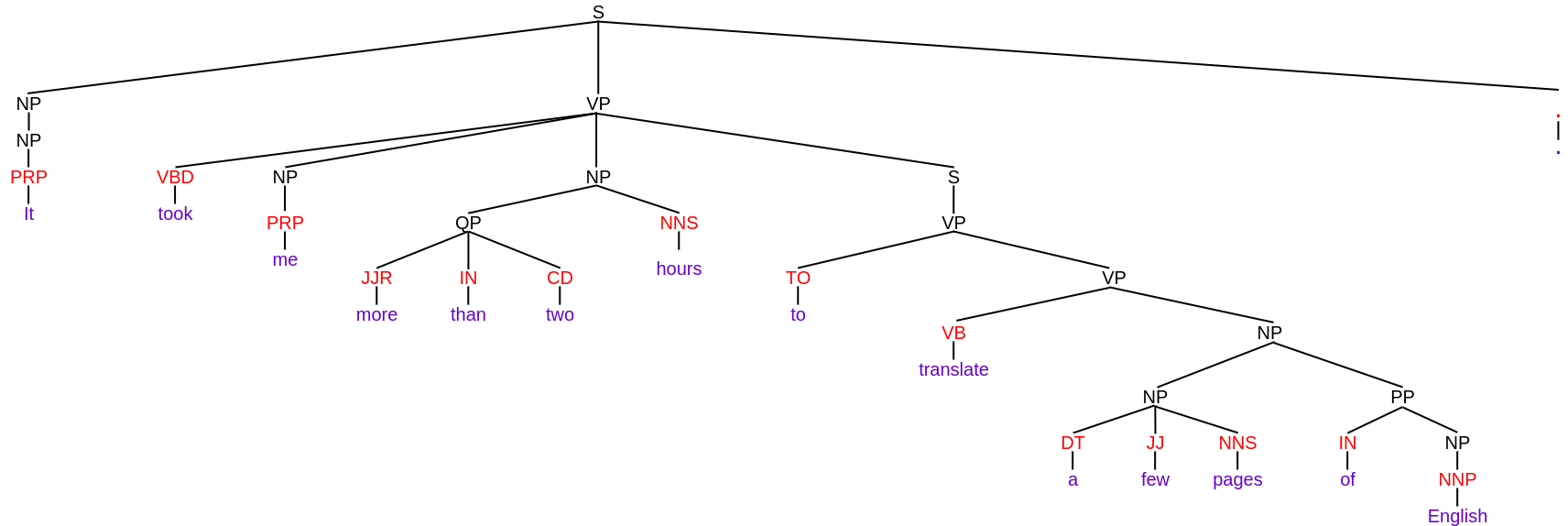
Nell'albero sopra, le parole della frase sono scritte in viola e i tag POS sono scritti in rosso. Tranne questi, è tutto scritto in nero, che rappresenta i componenti. Puoi vedere chiaramente come l'intera frase è suddivisa in sottofrasi fino a quando non rimangono solo le parole nei terminali. Cosa c'è di più, ci sono diverse etichette per indicare componenti come
- VP per frase verbale
- NP per frasi nominali
Queste sono le etichette costituenti. Puoi leggere su diverse etichette costituenti qui.
Ora sai cos'è l'analisi elettorale, quindi è tempo di programmare in Python. Ora, spaCy non fornisce un'API ufficiale per l'analisi dei componenti. Perciò, useremo il Analizzatore neurale di Berkeley. È un'implementazione Python di parser basata su Analisi della circoscrizione con un coder attento di ACL 2018.
Puoi anche usare StanfordParser con Stanza o NLTK per questo scopo, ma qui ho usato Berkely Neural Parser. Per usare questo, dobbiamo prima installarlo. Puoi farlo eseguendo il seguente comando.
!pip install benepar
Quindi devi scaricare il benepar_en2 modello.
Potresti aver notato che sto usando TensorFlow 1.x qui perché attualmente, benepar non è compatibile con TensorFlow 2.0. Ora è il momento di analizzare i distretti elettorali.

Qui, _.parse_string genera l'albero di analisi come una stringa.
Note finali
Ora, sai già cos'è l'etichettatura POS, analisi delle dipendenze e analisi costitutiva e come aiutano a comprendere i dati di testo, vale a dire, I tag POS ti parlano della parte grammaticale delle parole in una frase, L'analisi delle dipendenze ti informa sulle dipendenze tra le parole in una frase e l'analisi costitutiva ti informa sulle sottofrasi o sui componenti di una frase. Ora sei pronto per passare a parti più complesse della PNL.. Come prossimi passi, Puoi leggere i seguenti articoli sull'estrazione delle informazioni.
In questi articoli, imparerai come utilizzare i tag POS e i tag di dipendenza per estrarre informazioni dal corpus. Cosa c'è di più, per maggiori informazioni su spaCy, puoi leggere questo articolo: Tutorial SpaCy per imparare e padroneggiare l'elaborazione del linguaggio naturale (PNL) A parte questi, se vuoi imparare l'elaborazione del linguaggio naturale attraverso un corso, Posso consigliare quanto segue che include tutto, dai progetti ai tutorial individuali:
Se hai trovato questo articolo informativo, Condividi con i tuoi amici. Cosa c'è di più, puoi commentare sotto le tue domande.





