introduzione
Risolviamo gli ambienti Cartpole, Lunar Lander e Pong di OpenAI con l'algoritmo STRENGTH.
Il Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse.... es posiblemente la rama más genial de la inteligencia artificial. Ha già dimostrato la sua abilità: stupisci il mondo, batti i campioni del mondo nelle partite di scacchi, Vai e includi DotA 2.
In questo articolo, Analizzerei un algoritmo piuttosto rudimentale e mostrerei come anche questo possa raggiungere un livello di prestazioni sovrumano in alcuni giochi.
Offerte di apprendimento per rinforzo wiTh progettazione “agenti” che interagisce con a “Ambiente” e impara da solo come “organizzare” l'ambiente per tentativi ed errori sistematici. Un ambiente potrebbe essere un gioco come gli scacchi o le corse, o potrebbe anche essere un compito come risolvere un labirinto o raggiungere un obiettivo. L'agente è il bot che esegue l'attività.
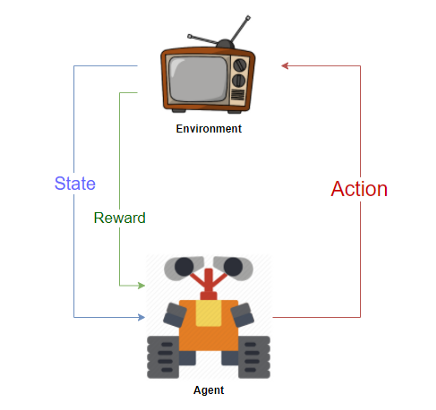
Un agente riceve “ricompense” quando si interagisce con l'ambiente. L'agente impara a eseguire il “Azioni” necessario per massimizzare la ricompensa che ricevi dall'ambiente. Un ambiente è considerato risolto se l'agente accumula una soglia di ricompensa predefinita. Questo discorso da nerd è come insegniamo ai robot a giocare a scacchi sovrumani o agli androidi bipedi a camminare.
RAFFORZARE Algoritmo
REINFORCE pertenece a una clase especial de algoritmos de aprendizaje por refuerzo llamados algoritmos de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... de políticas. Una semplice implementazione di questo algoritmo comporterebbe la creazione di a Politica: un modello che prende uno stato come input e genera la probabilità di eseguire un'azione come output. Una politica è essenzialmente una guida o un cheat sheet per l'agente che indica quale azione intraprendere in ogni stato.. Dopo, la politica viene ripetuta e leggermente modificata ad ogni passaggio fino a quando non otteniamo una politica che risolve l'ambiente.
La política suele ser una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. que toma el estado como entrada y genera una distribución de probabilidad en el espacio de acción como salida.
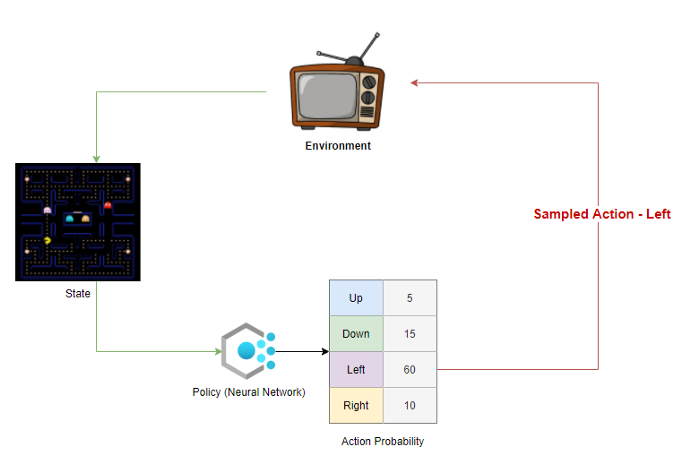
L'obiettivo della politica è massimizzare il "Ricompensa attesa".
Ogni polizza genera la probabilità di intraprendere un'azione in ogni stazione nell'ambiente.
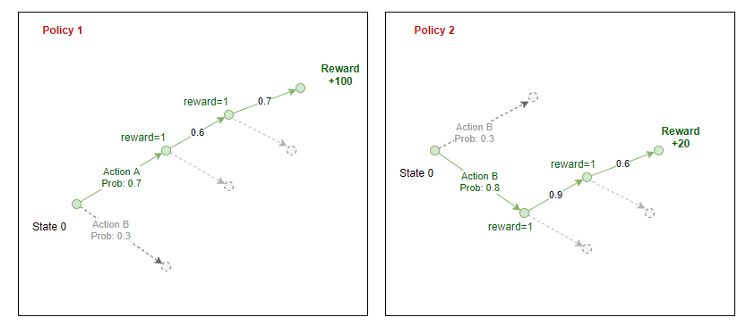
L'agente campiona queste probabilità e seleziona un'azione da intraprendere nell'ambiente. Alla fine di un episodio, conosciamo le ricompense totali che l'agente può ottenere se segue tale politica. Ripropifichiamo la ricompensa attraverso il percorso che l'agente ha preso per stimare il “ricompensa attesa” in ogni stato per una data politica.

Qui il premio scontato è la somma di tutti i premi che l'agente riceve in quel futuro scontati di un fattore Gamma.

Il premio scontato in qualsiasi fase è il premio che ricevi nel passaggio successivo + una somma scontata di tutti i premi che l'agente riceverà in futuro.
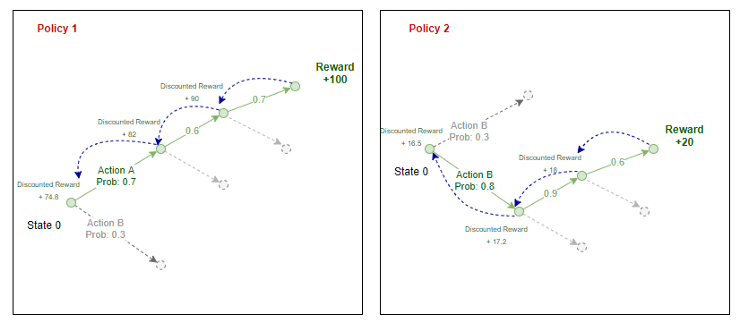
Per l'equazione di cui sopra, ecco come calcoliamo la ricompensa attesa:
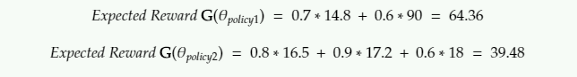
Secondo l'implementazione originale dell'algoritmo STRENGTH, il premio atteso è la somma dei prodotti di un record di quote e premi scontati.
Passaggi dell'algoritmo
I passaggi coinvolti nell'attuazione di REINFORCE sarebbero i seguenti:
- Inizializza un criterio casuale (un NN che prende in input lo stato e restituisce la probabilità delle azioni)
- Usa la politica per giocare a N passaggi del gioco: registrare le probabilità di azione, di politica, la ricompensa dell'ambiente, l'azione, campionato dall'agente
- Calcola il premio scontato per ogni passaggio tramite backpropagation
- Calcola la ricompensa attesa G
- Adeguare i pesi della politica (errore di propagazione inversa in NN) aumentare G
- Ripeti da 2
Guarda l'implementazione usando Pytorch in my Github.
Popolazione
Ho testato l'algoritmo in Pong, CartPole e Lunar Lander. Ci vuole un'eternità per allenarsi a Pong e Lunar Lander: più di 96 horas de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... cada uno en una GPU en la nube. Ci sono diversi aggiornamenti a questo algoritmo che possono farlo convergere più velocemente, che non ho discusso o implementato qui. Dai un'occhiata ai modelli di attori critici e all'ottimizzazione delle politiche in arrivo se sei interessato a saperne di più.
Carrello

Stato:
Posizione orizzontale, velocità orizzontale, angolo del polo, velocità angolare
Comportamento:
Spingere il carrello a sinistra, Spingi il carrello a destra
Gioco politico casuale:
Politica degli agenti formati con REINFORCE:
Lander lunare
Agente di gioco casuale
Stato:
Lo stato è una matrice di 8 vettore. Non sono sicuro di cosa rappresentino.
Comportamento:
0: fare niente
1: autopompa sinistra
2: Autopompa dei pompieri
3: autopompa destra
Politica degli agenti formati con REINFORCE:
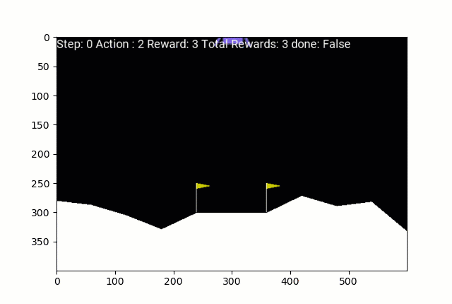
Lunar Lander addestrato con REINFORCE
Puzza
Questo è stato molto più difficile da addestrare. Addestrato su un server cloud GPU per giorni.
Stato: Immagine
Comportamento: Sposta la tavolozza a sinistra, sposta la tavolozza a destra
Agente addestrato
L'apprendimento del rinforzo ha compiuto passi da gigante oltre il RINFORZO. Il mio obiettivo in questo articolo era 1. apprendere le basi dell'apprendimento per rinforzo e 2. mostra quanto possono essere potenti anche metodi così semplici per risolvere problemi complessi. mi piacerebbe provarli su qualcuno “Giochi” fare soldi come fare trading di azioni … Immagino che questo sia il Santo Graal tra gli scienziati dei dati.
Repository Github: https://github.com/kvsnoufal/reinforce
Spalle di giganti:
- Algoritmi del gradiente di policy (https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html)
- Derivato RINFORZO (https://medium.com/@thechrisyoon/deriving-policy-gradients-and-implementing-reinforce-f887949bd63)
- Corso di apprendimento per rinforzo Udacity (https://github.com/udacity/deep-reinforcement-learning)
Circa l'autore

Noufal kvs
Lavora presso Dubai Holding, Emirati Arabi Uniti come data scientist. Puoi contattarmi a [e-mail protetta] oh https://www.linkedin.com/in/kvsnoufal/





