Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Fast.ai utiliza métodos y enfoques avanzados en el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... para generar resultados de vanguardia. Questo approccio di cui parleremo ci consente di addestrare modelli più accurati, Più veloce, con meno dati e in meno tempo e denaro.
Fast.ai è stata fondata da Jeremy Howard e raquel thomas para proporcionar a los profesionales del aprendizaje profundo una manera rápida y fácil de lograr resultados de vanguardia en los dominios de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... estándar del aprendizaje profundo, vale a dire, Filtraggio della vista, testo, tabulare e collaborativo.
Ora iniziamo con Fast.ai.
Questo tutorial presuppone una conoscenza di base di python3. È necessario un laptop Jupyter con una GPU, ya que la GPU acelera el proceso de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... Su 100 volte rispetto alla CPU. Puoi accedervi da Google Collaborativo che è un ambiente laptop jupyter e fornisce una GPU gratuita. Fare riferimento è per abilitare la GPU gratuita in Colab.
Addestra un classificatore di immagini
Addestriamo un classificatore di immagini MNIST di base utilizzando Fast.ai. Il set di dati MNIST è costituito da immagini di cifre scritte a mano dal 0 al 9. Perciò, avere 10 classi ed è un problema di classificazione multiclasse. Esso consiste in 60000 immagini nel training set e 10000 immagini nel set di convalida.
Importazioni
Nella prima cella, eseguire quanto segue per assicurarsi che tutte le librerie richieste siano installate. Altrimenti, la libreria fastai verrà installata e dovrai riavviare il runtime.
!pip install fastai --upgrade
Dopo, importiamo la libreria di visione fastai,
da fastai.vision.all import *
Se hai avuto esperienza nella programmazione Python o nello sviluppo di software, ti chiederai se importare tutti i sottomoduli e le funzioni della classe (vale a dire, usare *) è una pratica malsana. Ma la libreria fastai è progettata in modo tale che vengano importate solo le funzioni richieste e assicura che non ci sarà un carico inutile sulla memoria.
Download dati
Ora, scarichiamo i dati richiesti,
percorso = untar_data(URL.MNIST)
Qui usiamo una funzione fastai untar_data che prende l'URL del set di dati e scarica ed estrae il set di dati e quindi restituisce il percorso dei dati. Restituisce un Pathlib's PosixPath oggetto che può essere utilizzato per accedere e navigare con facilità nei file system. Accediamo all'URL del set di dati MNIST dal fastai URL metodo composto da URL di molti set di dati diversi.
Possiamo controllare il contenuto nel percorso usando
#to list the contents
path.ls()
Possiamo vedere che ci sono due cartelle. addestramento e test costituito da dati di addestramento e dati di convalida, rispettivamente.
Caricamento dati
Ora possiamo caricare i dati,
dls = ImageDataLoaders.from_folder(percorso=percorso,
treno='allenamento',
valido='in prova',
casuale=Vero)
ImageDataLoaders è uno dei tipi di classi che usiamo per caricare set di dati per problemi di visione artificiale. In genere, I set di dati di computer vision sono strutturati in modo tale che il tag di un'immagine sia il nome della cartella in cui è presente l'immagine. Come è strutturato il nostro set di dati in questo modo, usiamo un metodo from_folder per caricare immagini da cartelle nel percorso indicato.
Specifichiamo il percorso del set di dati da cui le immagini vengono caricate in batch, specifichiamo il nome delle cartelle costituite dai dati di training e validazione che verranno utilizzati per training e validazione, e poi inizializziamo mescola un vero, che garantisce che mentre il modello si sta allenando, le immagini vengono mescolate e inserite nel modello.
Per ulteriori informazioni su qualsiasi funzione Fastai, possiamo usare il metodo doc () che mostra la breve documentazione su tale funzione.
documento(ImageDataLoaders.from_folder)
Possiamo vedere alcuni dei dati usando show_batch () metodo,
dls.train.show_batch() dls.valid.show_batch()
Mostra alcune immagini rispettivamente del training set e del validation set.
Formazione modello
Ora creiamo il modello,
impara = cnn_discente(dls,
resnet18,
metriche=[precisione, tasso_errore])
Qui stiamo usando cnn_learne vale a dire, especificar fastai para construir un modelo de convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. a partir de la arquitectura dada, vale a dire resnet18 e allenati sul caricatore di dati specificato, vale a dire dls e monitorare le metriche fornite, vale a dire precisione e Tasso di errore.
La CNN è l'approccio all'avanguardia di oggi alla modellazione della visione artificiale. Qui stiamo usando una tecnica chiamata trasferimento di apprendimento per addestrare il nostro modello. Questa tecnica utilizza a Modello predefinito vale a dire, un'architettura standard e già addestrata per uno scopo diverso. Entriamo nel dettaglio nella prossima sezione.
Adesso alleniamoci (in realtà, accordiamo) il modello,
Possiamo vedere che il modello inizia ad allenarsi con i dati durante 4 epoche. I risultati sono i seguenti,
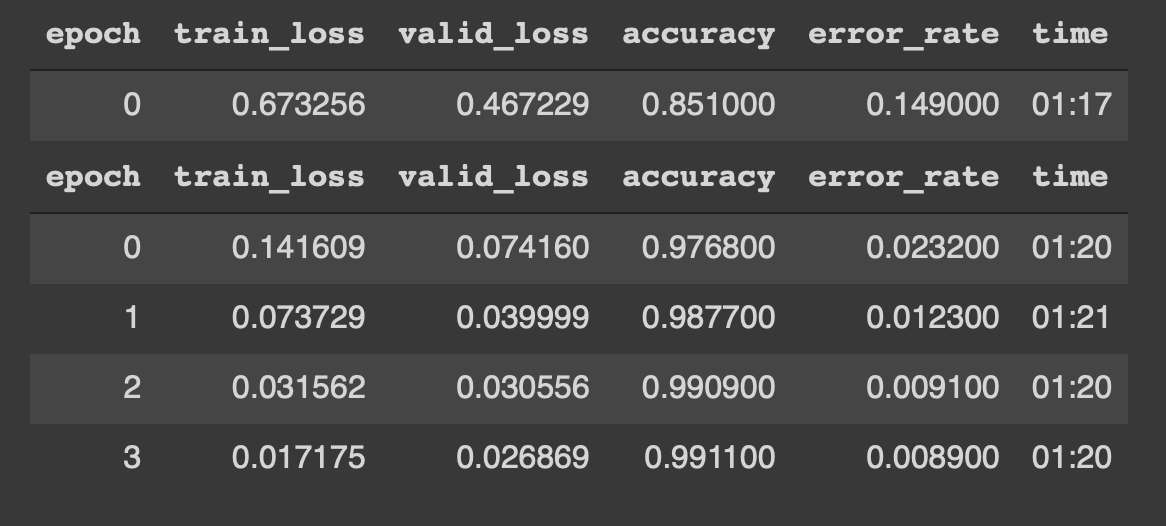
¡¡Woah !! una precisione di 99% e quasi a 0,8% di error_rate sono, letteralmente, risultati all'avanguardia. Cosa c'è di più, siamo stati in grado di raggiungere questo obiettivo con solo 4 epoche, 5 righe di codice e 5 minuti di allenamento.
Mettendo insieme,
da fastai.vision.all import *
percorso = untar_data(URL.MNIST)
dls = ImageDataLoaders.from_folder(percorso=percorso,
treno='allenamento',
valido='in prova',
casuale=Vero)
impara = cnn_discente(dls,
resnet18,
metriche=[precisione, tasso_errore])
impara.fine_tune(4)
Questo è possibile grazie a una tecnica chiamata Trasferire l'apprendimento. Discutiamone un po' in dettaglio.
Trasferire l'apprendimento
prima di continuare, dobbiamo conoscere i modelli preaddestrati.
Modelli precedentemente addestrati sono fondamentalmente architetture già addestrate su un set di dati diverso e per uno scopo diverso. Ad esempio, abbiamo usato risentirsi18 come la nostra rete preformata. Conosciuto anche come reti residue, risent18 consiste di 18 layer ed è addestrato su oltre un milione di immagini dal set di dati ImageNet. Questa rete pre-addestrata può facilmente classificare le immagini in 1000 Lezioni, come i libri, matite, animali, eccetera. Perciò, questo modello conosce vari oggetti e cose anche prima di essere addestrato sul nostro set di dati. Ecco perché si chiama Preentrenada rossa.
Ora, il transfer learning è la tecnica che ci consente di utilizzare un modello precedentemente addestrato per un nuovo compito e set di dati. Trasferire l'apprendimento è fondamentalmente il processo di utilizzo di un modello pre-addestrato per un compito diverso da quello originariamente addestrato, vale a dire, in questo caso stiamo usando risent18 per allenarci su immagini di cifre scritte a mano.
Questo è possibile grazie a un passaggio fondamentale chiamato sintonia FINA. Quando abbiamo un modello precedentemente addestrato, usiamo questo passaggio per aggiornare il modello precedentemente addestrato in base alle esigenze del nostro compito / dati. L'ottimizzazione fine è fondamentalmente una tecnica di apprendimento del trasferimento che aggiorna i pesi del modello preaddestrato mediante l'addestramento per alcune epoche nel nuovo set di dati..
Perciò, Utilizzando questa tecnica possiamo ottenere risultati all'avanguardia nel nostro compito, vale a dire, classificare le cifre scritte a mano.
Adesso facciamo qualche previsione
Prevedi immagini
Primo, prendiamo tutti i percorsi delle immagini nel set di prova e poi li convertiamo in un'immagine e facciamo la previsione.
# ottieni tutti i percorsi delle immagini dalla cartella di test immagini = get_image_files(percorso/'test')
# seleziona un'immagine e visualizza img = PILImage.create(immagini[4432]) img
Prevedi l'immagine
# prevedere la classe dell'immagine lbl, _ , _ = impara.prevedi(img) lbl
Rapporto di classificazione
Possiamo anche generare un rapporto di classificazione dal modello per l'inferenza.
interep = ClassificationInterpretation.from_learnner(imparare) interep.plot_confusion_matrix()
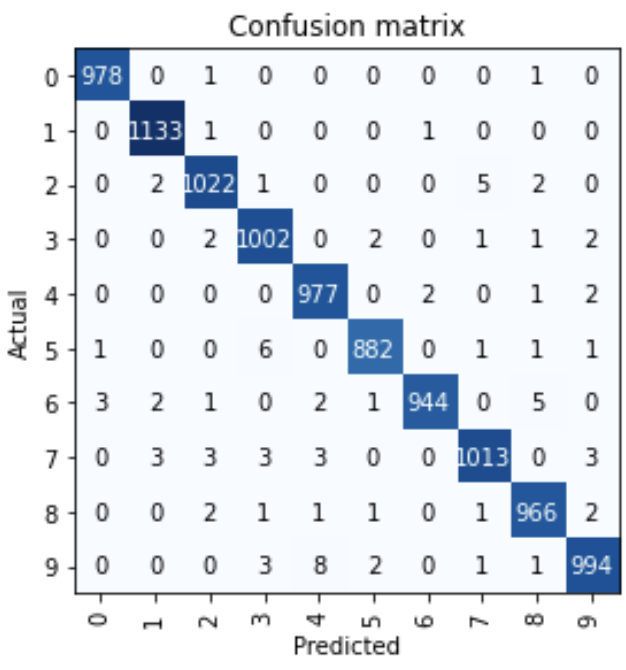
Lo vediamo quasi 10000 immagini, solo alcune immagini sono state classificate erroneamente.
Grazie e buon apprendimento profondo!!
Riferimenti:
1. Deep learning pratico per programmatori di Jeremy Howard e Sylvain Gugger
Di Narasimha Karthik J
Puoi connetterti con me attraverso Dal link oh Twitter
I media mostrati in questo articolo sulla creazione di modelli di deep learning di nuova generazione con Fast.ai non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





