Quando la giornata stava volgendo al termine, Ho pensato di inserirmi in un altro incontro. Due analisti del mio team stavano lavorando per creare un set di dati per uno dei modelli predittivi che volevamo costruire.. Esperienza lavorativa combinata (nei modelli predittivi) tra gli analisti era ~ 5 anni. Speravo di superare la riunione e uscire per la giornata.
Quindi, l'incontro è iniziato. Cinque minuti dopo l'incontro e sapevo che l'incontro sarebbe durato molto più tempo di quanto pensassi inizialmente!!
La ragione? Rivediamo la discussione così com'è andata:

Kunal: Quante righe hai nel set di dati??
Analista 1: (Dopo aver esaminato il set di dati) X righe
Kunal: Quante file stai aspettando?
Analista 1 e 2: Sguardo vuoto sui loro volti
Kunal: Quanti eventi / punti dati previsti nel periodo / ogni mese?
Analista 1 e 2: …. (Nessuno di loro aveva la più pallida idea)
Il numero di righe nel set di dati mi è sembrato più alto. Gli analisti l'avevano chiaramente trascurato, perché non lo hanno confrontato con le aspettative commerciali (o non ce l'avevano in primo luogo). Quando si approfondisce, abbiamo scoperto che alcuni eventi avevano più righe nei set di dati e, perché, un numero maggiore di righe.
Un'alta percentuale di analisti avrebbe vissuto un'esperienza simile ad un certo punto della loro carriera..
Qualche volta, a causa di pressioni temporali o per qualche altro motivo, trascuriamo di eseguire controlli di integrità di base sul set di dati su cui stiamo lavorando. Nonostante questo, trascurare l'accuratezza dei dati nelle prime fasi del progetto può essere molto costoso e, perché, in generale è importante evidenziare l'essere paranoici in relazione all'accuratezza dei dati.
Generalmente, Seguo un semplice framework per verificare l'accuratezza dei punti dati. In questo post, Condividerò la procedura che utilizzo abitualmente per verificare la correttezza dei dati. Il telaio va dall'alto verso il basso, cosa si adatta bene?. Se hai errori evidenti nei tuoi set di dati, sarà evidente all'inizio della procedura.
Nota che il post rimanente presuppone che tu stia lavorando su un set di dati strutturato. Per set di dati non strutturati, anche se i principi sarebbero ancora applicabili, la procedura cambierebbe.
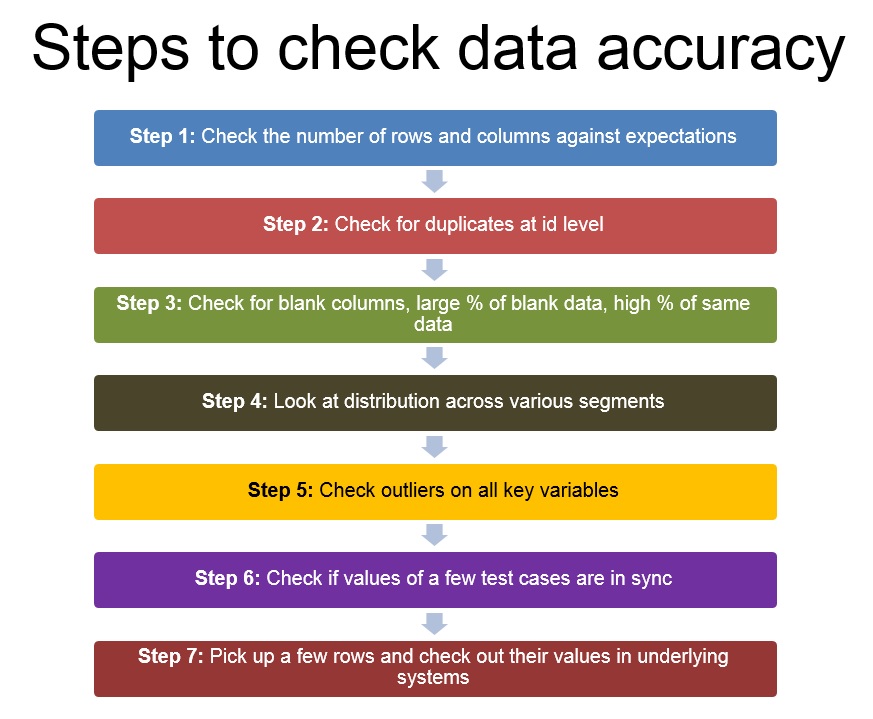
passo 1: controlla il numero di colonne e righe con le aspettative
Il primo passo non appena ottieni un set di dati sarebbe verificare se hai tutte le righe e le colonne richieste. Il numero di colonne sarebbe dettato dal numero di ipotesi che hai e dalle variabili che dovresti testare / confutare queste ipotesi.
D'altra parte, il numero di righe sarebbe dettato dal numero di eventi previsti nel periodo selezionato. Il benchmark più semplice sarebbe basato sulla tua comprensione aziendale.
passo 2: Verifica la presenza di duplicati a livello di identificazione (e non per l'intera riga)
Una volta che sei sicuro che tutte le colonne siano presenti e il numero di righe sembra all'interno dell'intervallo previsto, controlla rapidamente la presenza di duplicati a livello di ID (o il livello al quale le righe devono essere univoche; potrebbe essere una combinazione di variabili)
passo 3: controlla le colonne vuote, grande percentuale di dati vuoti, alta% degli stessi dati
Ora che sai che tutte le colonne ci sono e che non ci sono duplicati, cerca le colonne completamente vuote. Questo può accadere nel caso in cui qualche join fallisca o nel caso ci sia qualche errore nell'estrazione dei dati. Se nessuna delle colonne è vuota, guarda la % di casi vuoti per ogni colonna e le distribuzioni di frequenza per scoprire se gli stessi dati si ripetono in più casi del previsto.
passo 4: osservare la distribuzione nei vari segmenti; controlla la comprensione del business e usa le tabelle pivot
Questo passaggio continua dove finisce 3. Invece di guardare le frequenze dei punti dati individualmente, guarda le tue distribuzioni. Ti aspetti una distribuzione normale?, bipolare l'uniforme? Il layout è quello che ti aspettavi??
passo 5. Verifica la presenza di valori anomali in tutte le variabili chiave, soprattutto calcolati
Una volta che le distribuzioni sembrano buone, cercare valori anomali. Soprattutto nei casi in cui hai calcolato colonne. I valori di Extreme sono vicini a ciò che volevi?? Assicurati che non ci siano divisioni per zero, hai limitato i valori che vorresti.
passo 6: controlla se i valori di alcuni casi di test sono sincronizzati
Dopo aver controllato singolarmente tutte le colonne, controlla se sono sincronizzati tra loro. Controlla se le diverse date dei casi sono in ordine cronologico (P. Non., Fare i saldi, spesa e limite di credito sono sincronizzati tra loro per i clienti della tua carta di credito?
passo 7: scegli alcune righe e controlla i loro valori sui sistemi sottostanti
Una volta completati tutti i passaggi precedenti, è ora di controllare alcuni campioni interrogando i sistemi o i database sottostanti. Se c'era qualche errore nei dati, idealmente dovrei averlo già identificato. Questo passaggio garantisce solo che i dati siano come erano sui sistemi sottostanti.
Si prega di notare che alcuni di questi errori possono essere rilevati tramite l'uso di log forniti dal proprio strumento. Guardare i log in modo generale fornisce molte informazioni su errori e avvisi.
Questi erano i passaggi che ho usato per verificare l'esattezza dei dati e, generalmente, aiutami a rilevare errori evidenti nei dati. Apparentemente, non sono la soluzione a tutti i possibili errori, ma dovrebbero darti un buon punto di partenza e una buona direzione. Cosa ne pensi di questo telaio? Ci sono altri framework? / metodi utilizzati per verificare l'esattezza dei dati? Se è così, aggiungili nei commenti qui sotto.





