Nel mio articolo precedente, “Combinazione di set di dati in SAS – Semplificato”, analizziamo tre metodi per combinare i set di dati: allegare, concatenare e unire. In questo articolo, vedremo il metodo più comune e utilizzato per combinare i set di dati: FUSIONE o UNIONE.
La necessità di unire / unire i set di dati:
Prima di entrare nei dettagli, capiamo perché abbiamo davvero bisogno di unirci / unire. Ogni volta che abbiamo informazioni divise e disponibili in due o più set di dati e vogliamo combinarli in un unico set di dati, dobbiamo unirci / unisciti a questi tavoli. Una delle cose principali da tenere a mente è che l'unione dovrebbe essere basata su criteri o campi comuni. Ad esempio, in un'azienda di vendita al dettaglio, abbiamo una tabella delle transazioni giornaliere (la tabella contiene i dettagli del prodotto, dettagli di vendita e dettagli del cliente) e una tabella di inventario (che ha i dettagli del prodotto e la quantità disponibile). però, per avere le informazioni sull'Inventario o sulla disponibilità di un prodotto, cosa dovremmo fare? Combina la tabella TransazioneIl "transazione" si riferisce al processo mediante il quale avviene uno scambio di merci, servizi o denaro tra due o più parti. Questo concetto è fondamentale in campo economico e giuridico, poiché implica l'accordo reciproco e la considerazione di termini specifici. Le transazioni possono essere formali, come contratti, o informale, e sono essenziali per il funzionamento dei mercati e delle imprese.... con la tabella dell'inventario basata su Product_Code e sottrai la quantità venduta dalla quantità disponibile.
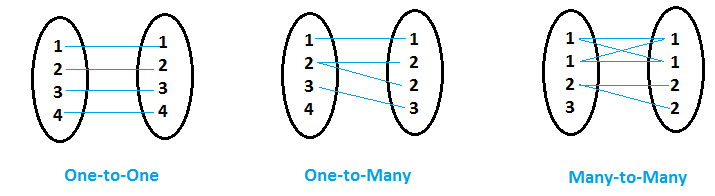
la fusione / l'unione può essere di vari tipi e dipende dai requisiti aziendali e dalla relazione tra i set di dati. Primo, Diamo un'occhiata ai vari tipi di relazioni che possono avere i set di dati.
- Quando per ogni valore di variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... Comune (diciamo variabile 'x') nel primo set di dati, il secondo set di dati ha un solo valore corrispondente per quella variabile comune "x", allora si chiama Dodici cinquantanove relazione.
- Quando per i valori della variabile comune (diciamo variabile 'y') nel primo set di dati, altri set di dati hanno più di un valore corrispondente per quella variabile comune "y", allora si chiama Uno a molti relazione.
- Quando entrambi i set di dati hanno più voci per lo stesso valore di variabile comune, allora si chiama Molti a molti relazione.
e SAS, possiamo fare unioni / fusioni attraverso varie forme, qui discuteremo i modi più comuni: Data Step e PROC SQL. Nel passaggio Dati, Utilizziamo l'istruzione merge per eseguire join, mentre in PROC SQL, scriviamo una query SQL. Analizziamo prima il passaggio dei dati:
PASSAGGI DATI
Sintassi:- Set di dati; Unisci Dataset1 Dataset2 Dataset3 ... Datasetn; Di CommonVariable1 CommonVariable2...... CommonVariablen; Correre;
Nota: – I set di dati devono essere ordinati per variabile (S) comune e nome, il tipo e la lunghezza della variabile comune devono essere gli stessi per tutti i set di dati di input.
Diamo un'occhiata ad alcuni scenari per ciascuna delle relazioni tra i set di dati di input.
Rapporto UNO a UNO
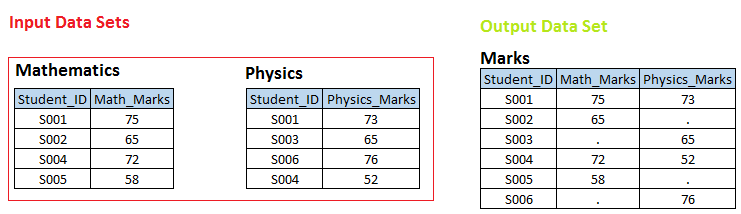
Palcoscenico 1 Nei seguenti set di dati di input, puoi vedere che esiste una relazione uno a uno tra queste due tabelle in ID studente. Ora vogliamo creare un set di dati. MARCHE, dove abbiamo tutti gli student_id unici con i rispettivi voti in matematica e fisica. Se student_id non è disponibile nella tabella Math, quindi math_marks dovrebbe avere un valore mancante e viceversa.
Soluzione utilizzando i passaggi dei dati: –
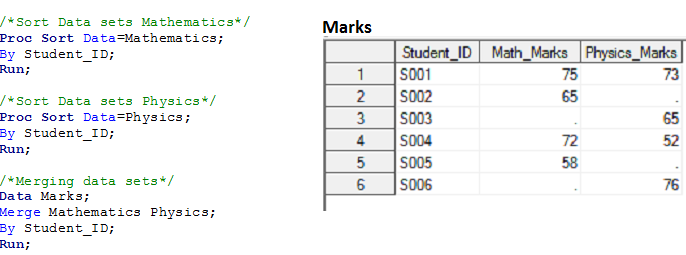
Come funziona:-
- SAS confronta entrambi i set di dati e crea un POS (Vettore di dati di programma) per tutte le variabili univoche e le inizializza con valori mancanti (il Program Data Vector è un intermediario tra i set di dati di input e di output). Nell'esempio attuale, Creerei un POV come questo:

- Leggi la prima osservazione dai set di dati di input e confronta i valori della variabile BY in entrambi i set di dati:
- se i valori sono uguali, viene confrontato con il valore della variabile BY in POS.
- se non lo stesso, le variabili POV vengono ripristinate con i valori mancanti e il valore dell'osservazione corrente viene copiato nel POV mentre l'altra osservazione rimane persa
- Se è lo stesso, Le variabili POS non vengono reinizializzate. Il valore disponibile dell'osservazione corrente viene aggiornato nel POS
- Successivamente, il puntatore del record si sposta all'osservazione successiva in entrambi i set di dati e, mentre l'istruzione RUN è in esecuzione, I valori PDV vengono passati al set di dati di output.
- Se il valore della variabile By non corrisponde, l'osservazione del set di dati con il valore più basso viene copiata in POS. Il puntatore del record del set di dati che ha un valore della variabile BY inferiore viene spostato all'osservazione e al passaggio successivi 2 (un) si ripete di nuovo.
- se i valori sono uguali, viene confrontato con il valore della variabile BY in POS.
- I passaggi precedenti vengono ripetuti fino a raggiungere l'EOF di entrambi i set di dati.
Puoi eseguire una prova per valutare il set di dati dei risultati.
Palcoscenico 2: – Sulla base dei set di dati di input dello scenario 1, vogliamo creare i seguenti set di dati di output.
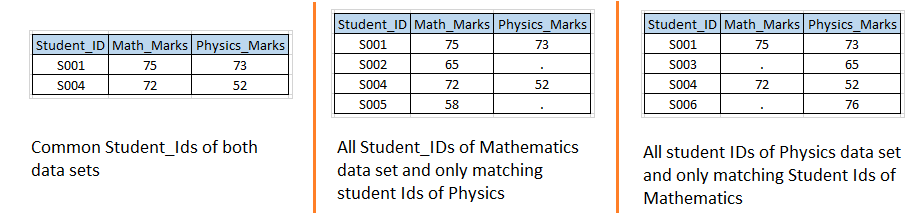
Soluzione utilizzando i passaggi dei dati: – Scriviamo un codice simile allo scenario 1 con l'opzione IN. 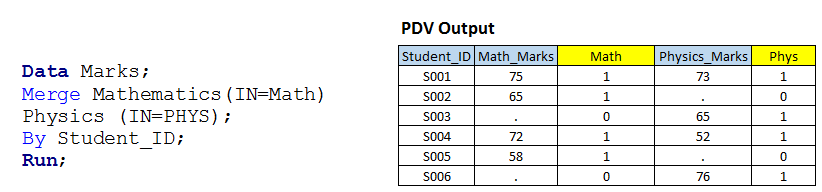 Al di sopra, puoi vedere che abbiamo usato l'opzione IN con entrambi i set di dati di input e assegnato i valori di questi alle variabili temporanee MATH e PHYS perché sono variabili temporanee, quindi non possiamo vederli nel set di dati di output.
Al di sopra, puoi vedere che abbiamo usato l'opzione IN con entrambi i set di dati di input e assegnato i valori di questi alle variabili temporanee MATH e PHYS perché sono variabili temporanee, quindi non possiamo vederli nel set di dati di output.
ti ho mostrato la tabella (Dati PDV) che ha un valore variabile per tutte le osservazioni insieme alle variabili temporanee. Ora, in base al valore di queste variabili, possiamo scrivere codice per le operazioni di sottoconfigurazione e ADERIRE"ADERIRE" è un'operazione fondamentale nei database che permette di combinare i record di due o più tabelle in base ad una relazione logica tra di esse. Esistono diversi tipi di JOIN, come INNER JOIN, LEFT JOIN e RIGHT JOIN, ognuno con le proprie caratteristiche e usi. Questa tecnica è essenziale per query complesse e informazioni più pertinenti e dettagliate provenienti da più fonti di dati.... come abbiamo bisogno:
- Se MATH e PHYS hanno valore 1, creerà il primo set di dati di output e verrà chiamato GIUNTO INTERNOun "Giunto interno" è un'operazione nei database che permette di combinare righe di due o più tabelle, in base a una specifica condizione di corrispondenza. Questo tipo di join restituisce solo le righe che hanno corrispondenze in entrambe le tabelle, risultante in un set di risultati che riflette solo i dati correlati. Nelle query SQL è fondamentale ottenere informazioni coerenti e accurate da più fonti di dati.....
- Se MATH ha 1, creerà un secondo set di dati di output e verrà chiamato JOIN A SINISTRAIl "JOIN A SINISTRA" è un'operazione in SQL che consente di combinare le righe di due tabelle, Mostra tutte le righe nella tabella di sinistra e le corrispondenze nella tabella di destra. Se non ci sono corrispondenze, vengono riempiti con valori nulli. Questo strumento è utile per ottenere informazioni complete, Anche quando alcune relazioni sono facoltative, facilitando così l'analisi dei dati in modo efficiente e coerente.....
- Se PHYS ha 1, creerà un terzo insieme di dati di output e verrà chiamato come DIRITTO JOINIl "DIRITTO JOIN" è un'operazione nei database che consente di combinare righe da due tabelle, assicurandosi che tutte le righe della tabella a destra siano incluse nel risultato, anche se non ci sono partite nella tabella a sinistra. Questo tipo di join è utile per conservare le informazioni dalla tabella secondaria, semplificando l'analisi e l'ottenimento di dati completi nelle query SQL....
- Se MATH e PHYS hanno 1, funzionerà come ADESIONE COMPLETAIl "ADESIONE COMPLETA" è un'operazione di database che combina i risultati di due tabelle, Mostra tutti i record per entrambi. Quando ci sono coincidenze, I dati vengono combinati, ma sono inclusi anche i record che non hanno una corrispondenza nell'altra tabella, Completamento con valori nulli. Questa tecnica è utile per ottenere una visione completa delle informazioni, consentendo un'analisi più esaustiva dei dati in relazione a...., è stato risolto anche nella fase-1.
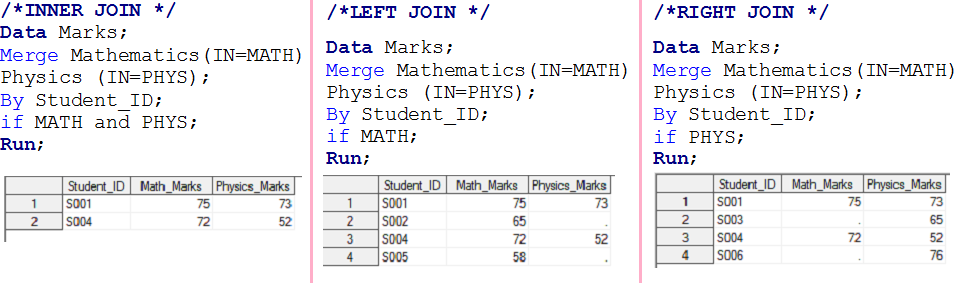
Relazione UNO a MOLTI
Palcoscenico – 3 Qui abbiamo due set di dati, Alunno e Esame e vogliamo creare un insieme di dati di output Marchi Trade.
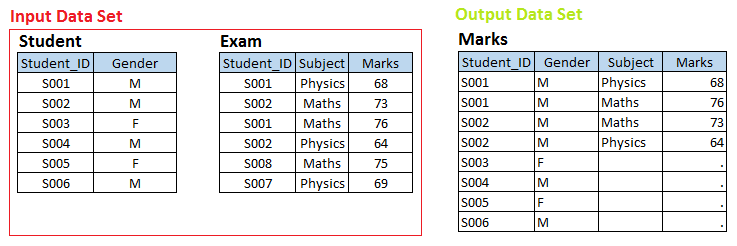
Oltre ai set di dati di input, c'è una relazione uno a molti tra lo studente e l'esame. Ora, se vuoi creare punteggi di set di dati di output con osservazione individuale per ogni esame dello studente, questi appartengono al set di dati STUDENTE, vale a dire, Unione sinistra.
Soluzione utilizzando i passaggi dei dati: –
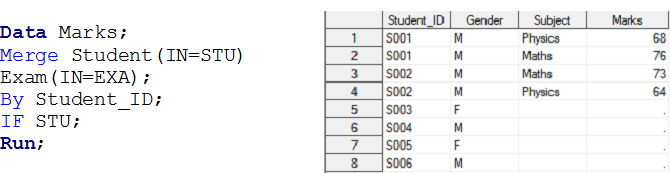
Allo stesso modo, possiamo eseguire operazioni di inner join, giusto e completo per una relazione uno a molti utilizzando l'operatore IN.
Rapporto MOLTI a MOLTI
Palcoscenico 4: Crea set di dati di output che hanno tutti i join basati su un campo comune. Puoi anche vedere che entrambi i set di dati di input hanno una relazione molti a molti.
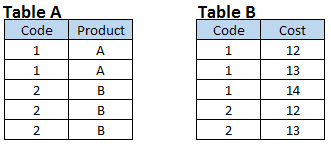
I passaggi dei dati non creano una relazione MOLTO a MOLTI, perché non forniscono output come prodotto cartesiano. Quando uniamo la tabella A e la tabella B utilizzando i passaggi dei dati, l'output è simile alla seguente istantanea.
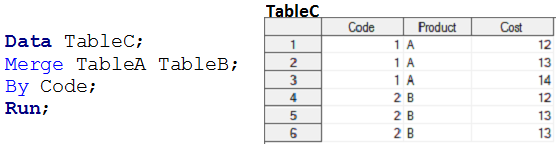 Abbiamo già visto, Come possiamo utilizzare i passaggi dei dati per unire due o più set di dati che hanno una qualsiasi delle relazioni?, tranne MOLTI a MOLTI? Ora vedremo i metodi PROC SQL per avere una soluzione per requisiti simili.
Abbiamo già visto, Come possiamo utilizzare i passaggi dei dati per unire due o più set di dati che hanno una qualsiasi delle relazioni?, tranne MOLTI a MOLTI? Ora vedremo i metodi PROC SQL per avere una soluzione per requisiti simili.
PROC SQL
Per comprendere la metodologia di join in SQL, dobbiamo prima capire il prodotto cartesiano. Il prodotto cartesiano è una query che ha più tabelle nella clausola from e produce tutte le possibili combinazioni di righe dalle tabelle di input. Se abbiamo due tavoli con 2 e 4 record rispettivamente, utilizzando il prodotto cartesiano, abbiamo un tavolo con 2 X 4 = 8 record.
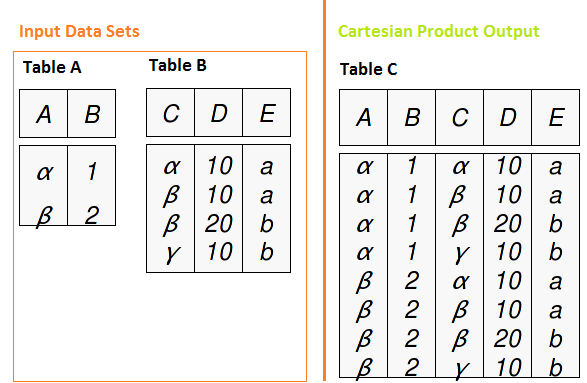
I join SQL funzionano per ciascuna delle relazioni tra i set di dati (uno per uno, uno a molti e molti a molti). Vediamo come funziona con i tipi di join.
Sintassi:-
Si prega di selezionare Colonna-1, Colonna-2,… Colonna-n di table1 GIUNTO INTERNO / SINISTRA / GIUSTO / COMPLETOcapaz2 SU Condizione di unione ;
Nota:-
- Le tabelle possono essere ordinate o meno per variabili comuni.
- Il nome delle variabili comuni potrebbe non essere simile, ma deve essere simile per lunghezza e tipo.
- Funziona con un massimo di due tabelle.
Risolviamo i requisiti di cui sopra utilizzando PROC SQL.
Palcoscenico 1 :- Questo era un esempio di FULL Join, dove tutti gli Student_ID erano richiesti nel set di dati di output con i rispettivi flag MATH e PHYSICS.

Su nel set di dati di output, puoi vedere che manca Student_ID per quegli studenti che si sono presentati solo per l'esame di fisica. Per risolverlo useremo una funzione COALESCE. Restituisce il valore del primo argomento che non manca tra le variabili date.
Sintassi:-
COALESCE (argomento-1, argomento-2,… ..argomento-n)
Modifichiamo il codice sopra: –
Palcoscenico 2: – Questo era un esempio di INNER, Unisciti a sinistra e a destra. Qui stiamo risolvendo per Inner Join. Nello stesso modo, possiamo fare per la giunzione sinistra e destra.
Nello stesso modo, possiamo fare per la giunzione sinistra e destra.
Palcoscenico -3 Questo era un problema vincolante sinistro per una relazione UNO a MOLTI.
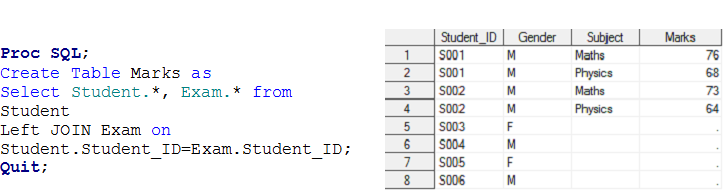
Palcoscenico -4 Questo era un problema di relazione Molti a MOLTI.. Abbiamo già discusso che SQL può produrre un prodotto cartesiano che contiene tutte le combinazioni di record tra due tabelle.

Sopra abbiamo visto Proc SQL unirsi / unire i set di dati.
Nota finale: –
In questa serie di articoli sulla combinazione di set di dati in SAS, analizziamo vari metodi per combinare set di dati come l'aggiunta, concatenare, unire, fusibile. In particolare in questo articolo, ne discutiamo a seconda della relazione tra i set di dati, vari tipi di join e come possiamo risolverli in base a diversi scenari. Abbiamo usato due metodi (Passi dati y PROC SQL) per ottenere risultati. Vedremo l'efficacia di questi metodi in uno dei prossimi articoli..
Questa serie ti è stata utile?? Abbiamo semplificato un argomento complesso come combinare set di dati e cercato di presentarlo in modo comprensibile. Se hai bisogno di ulteriore aiuto con la combinazione di set di dati, sentiti libero di fare le tue domande attraverso i commenti qui sotto.
PS Hai aderito?? Discussione di Vidhya analitico ancora? Se non è così, si stanno perdendo molti dibattiti sulla scienza dei dati. Queste sono alcune delle discussioni che si svolgono in SAS:
1. Seleziona le variabili e trasferiscile in un nuovo set di dati in SAS
2. Importa il primo 20 record da Excel a SAS
3. Dove l'istruzione non funziona in SAS





