Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
I dati sono ovunque nel mondo dei dati di oggi e possiamo trarne vantaggio solo se possiamo estrarre informazioni dai dati. La visualizzazione dei dati è l'aspetto visivamente più accattivante dell'analisi dei dati perché ci consente di interagire con i dati. È quella tecnica magica per trasmettere informazioni a grandi gruppi di persone con un solo sguardo e creare storie interessanti dai dati.. Pandas è uno degli strumenti di analisi dei dati più popolari e ampiamente utilizzati in Python. Ha anche una funzione di stampa incorporata per i campioni. tuttavia, quando si tratta di visualizzazione interattiva, Gli utenti Python che non hanno competenze di ingegneria front-end potrebbero avere alcune sfide, come molte biblioteche, come D3, grafico.js, richiede una certa conoscenza di JavaScript. Plotly e Twins sono utili a questo punto.
Quando c'è una grande quantità di dati e le aziende hanno difficoltà a estrarne informazioni critiche, la visualizzazione dei dati svolge un ruolo importante nel prendere decisioni aziendali critiche.
Plotly è una libreria grafica costruita su d3.js che può essere utilizzata direttamente con i frame di dati Pandas grazie a un'altra libreria chiamata Cufflinks.
Ti mostreremo come utilizzare i grafici interattivi di Plotly con i frame di dati di Panda in questo breve tutorial.. Per mantenere le cose semplici, useremo Jupyter Notebook (installato utilizzando Anaconda Distribution con Python) e il famoso set di dati del Titanic.
Visualizzazione dei dati in Python
Dopo aver completato la pulizia e la manipolazione dei dati, il passo successivo nel processo di analisi dei dati è estrarre approfondimenti e conclusioni significative dai dati, cosa si può ottenere con grafici e tabelle. Python ha diverse librerie che possono essere usate per questo scopo. Generalmente, ci vengono insegnate solo le due librerie matplotlib e seaborn. Queste librerie includono strumenti per la creazione di grafici a linee, grafici a torta, grafici a barre, box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... y una variedad de otros diagramas. Probabilmente ti starai chiedendo perché abbiamo bisogno di altre librerie per la visualizzazione dei dati se abbiamo già matplotlib e seaborn. Quando ho sentito per la prima volta della trama e dei gemelli, Avevo la stessa domanda nella mia testa.
trama
La versione più recente di Plotly è stata 5.1.0, mentre quello con i gemelli era 0.17.5. Poiché le versioni precedenti dei gemelli non sono compatibili con le versioni di stampa appena rilasciate, è essenziale aggiornare entrambi i pacchetti contemporaneamente o trovare versioni compatibili. In Anaconda Prompt, esegui i seguenti comandi per installare plotly (o it Il terminale stesso usa il sistema operativo o Ubuntu)
Plotly è una libreria open source e grafica che consente la stampa interattiva. Pitone, R, MATLAB, Arduino e REST, tra gli altri, sono tra i linguaggi di programmazione supportati dalla libreria.
Cufflink è una libreria Python che collega trama e panda, permettendoci di disegnare grafici direttamente su frame di dati. È essenzialmente un plugin.
I grafici sono interattivi, che ci permette di scorrere sopra i valori, ingrandire e rimpicciolire i grafici e identificare gli outlier nel set di dati. Le lettere Matplotlib e Seaborn, In secondo luogo, sono statici; non possiamo ingrandire o rimpicciolire l'immagine, e tutti i valori nel grafico non sono dettagliati. La caratteristica più importante di Plotly è che ci permette di creare grafica web dinamica direttamente da Python, cosa non è possibile con matplotlib. Possiamo anche realizzare grafici e animazioni interattive da dati geografici, scienziati, statistiche e dati finanziari utilizzando plotly.
Installa su PC “trama “ e “Gemelli“ utilizzando un ambiente anaconda
conda install -c plotly plotly
conda install -c conda-forge gemelli-py
o usando pip
pip install plotly --upgrade
pip installa gemelli --upgrade
Caricamento librerie
Librerie dei panda, Trama e gemelli verranno caricati per primi. Perché plotly è una piattaforma online, requiere una credencial de inicio de sessioneIl "Sessione" È un concetto chiave nel campo della psicologia e della terapia. Si riferisce a un incontro programmato tra un terapeuta e un cliente, dove si esplorano i pensieri, Emozioni e comportamenti. Queste sessioni possono variare in durata e frequenza, e il suo scopo principale è quello di facilitare la crescita personale e la risoluzione dei problemi. L'efficacia delle sessioni dipende dalla relazione tra il terapeuta e il terapeuta.. para usarla en línea. Useremo la modalità offline in questo articolo, che è sufficiente per Jupyter Notebook.
#importazione di panda importa panda come pd #importazione trama e gemelli in modalità offline
importare gemelli come cf import plotly.offline cf.go_offline() cf.set_config_file(offline=falso, world_readable=Vero)
Caricamento set di dati
Abbiamo detto che utilizzeremo il set di dati del Titanic, cosa puoi ottenere da questo? kaggle_link. Verrà utilizzato solo il file train.csv.
df=pd.read_csv("treno.csv")
df.head()

Istogramma
Il istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... se pueden utilizar para inspeccionar las distribuciones de una característica, come la caratteristica “Età” in questo caso. Usiamo semplicemente il (dataframe["nome della colonna"]) per selezionare una colonna e quindi aggiungere la funzione iplot. Come esempio, possiamo specificare la dimensione del contenitore, l'argomento, il titolo e i nomi degli assi. Con il comando “aiuto (df.iplot)”, puede ver todos los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... del parámetro iplot.
df["Età"].trama(gentile="istogramma", contenitori=20, tema="bianco", titolo="Età del passeggero",xTitolo="Età", yTitolo ="Contare")
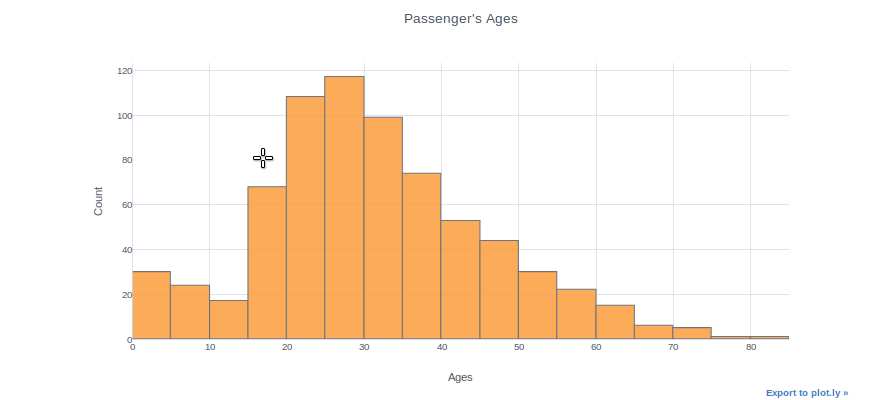
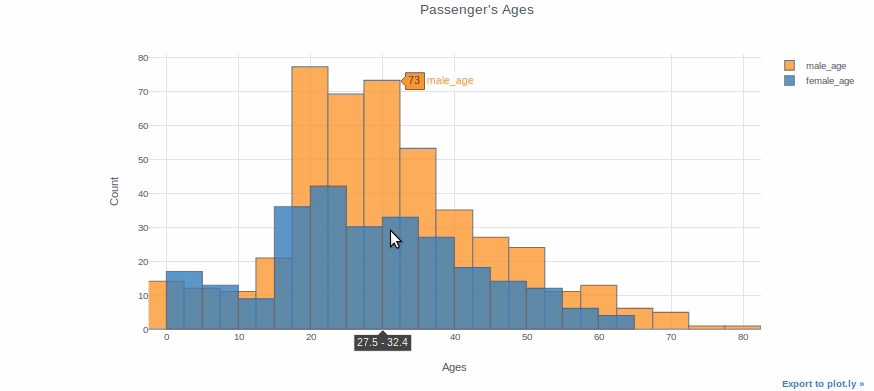
Puoi tracciare due diverse distribuzioni come due colonne diverse se vuoi confrontarle. Ad esempio, tracceremo l'età dei passeggeri maschi e femmine sullo stesso pacco.
df["età_maschile"]=df[df["Sesso"]=="maschio"]["Età"]
df["età_femminile"]=df[df["Sesso"]=="femmina"]["Età"]df[["età_maschile","età_femminile"]].trama(gentile="istogramma", contenitori=20, tema="bianco", titolo="Età del passeggero",
xTitolo="Età", yTitolo ="Contare")
Mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate....
Le mappe di calore possono essere utilizzate per una varietà di scopi, ma li useremo per verificare la correlazione tra le caratteristiche in un set di dati come esempio.
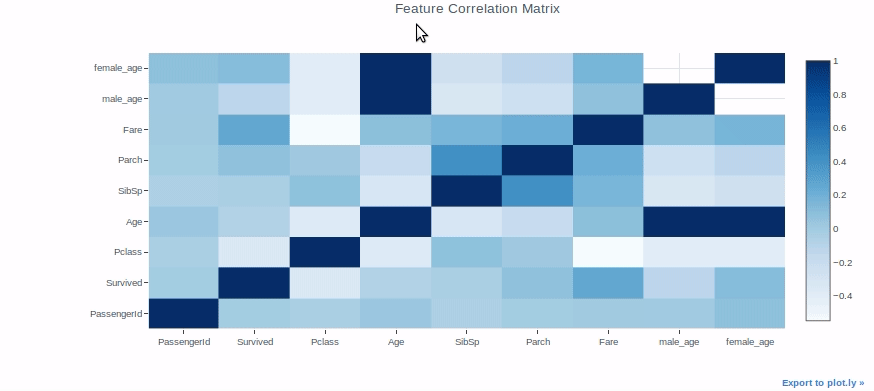
Trama scatola
I box plot sono estremamente utili per interpretare rapidamente l'asimmetria nei dati, valori anomali e intervalli di quartili. Useremo ora un box plot per mostrare la distribuzione di “Valutare” per ogni classe di Titanic.
#otterremo aiuto dalle tabelle pivot per ottenere i valori delle tariffe in colonne diverse per ogni classe. df[['classe', "Tariffa"]].perno(colonne="Pclass", valori="fare").trama(tipo='scatola')
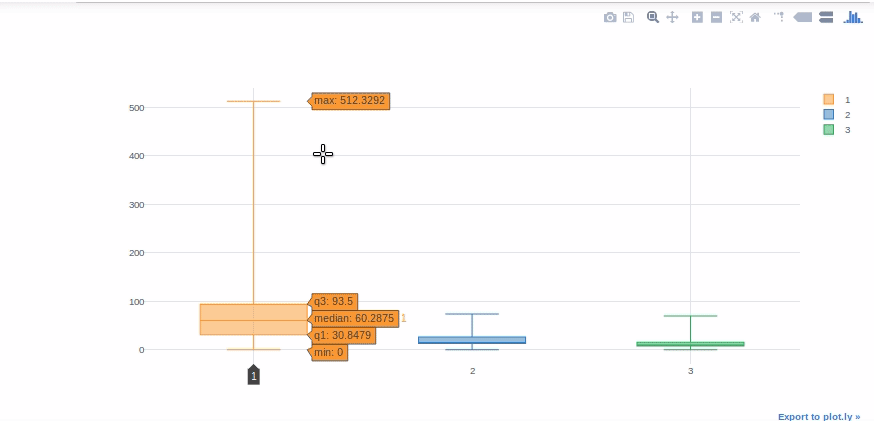
Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative....
I grafici a dispersione sono comunemente usati per visualizzare la relazione tra due variabili numeriche. Per le variabili “Valutare” e “Età”, useremo diagrammi a dispersione. "Categorie" ci permette di mostrare le variabili di una caratteristica selezionata in vari colori (sesso dei passeggeri in questo caso).
df.iplot(gentile="disperdere", tema="bianco",x="Età",y ="fare",
categorie="Sesso")
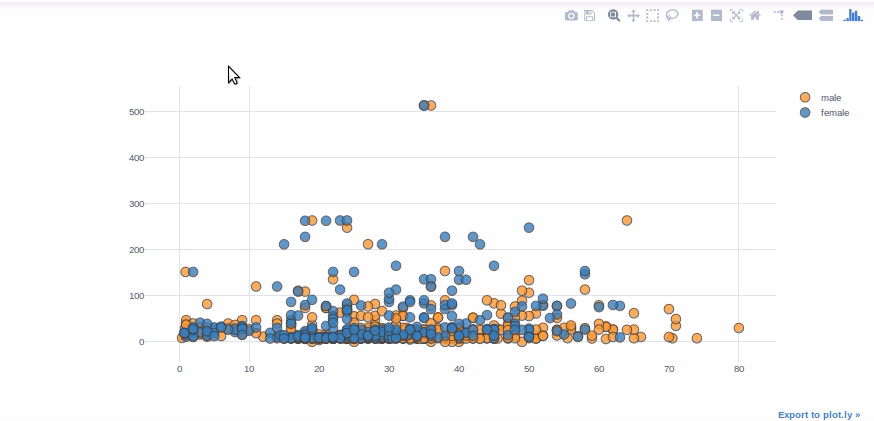
un rapido promemoria: il parametro “categorie” deve essere una stringa o una colonna di tipo float64. Ad esempio, nell'esempio del grafico a bolle, dovrebbe convertire la colonna “Sopravvissuto” di tipo intero in float64 o string.
Grafico a bolle
Possiamo usare i grafici a bolle per vedere più relazioni variabili contemporaneamente. Con i parametri di “categorie” e “dimensione” nel grafico, possiamo facilmente regolare le sottocategorie di colore e dimensione. Con il parametro “testo”, possiamo anche specificare la colonna di testo mobile.
#convertire la colonna sopravvissuta in float64 per poterla utilizzare in plotly
df[['Sopravvissuto']] = df[['Sopravvissuto']].come tipo('float64', copia=Falso)df.iplot(tipo='bolla', x="fare",y ="Età",categorie="Sopravvissuto", taglia="Pclass", testo="Nome", xTitolo="fare", yTitolo ="Età")
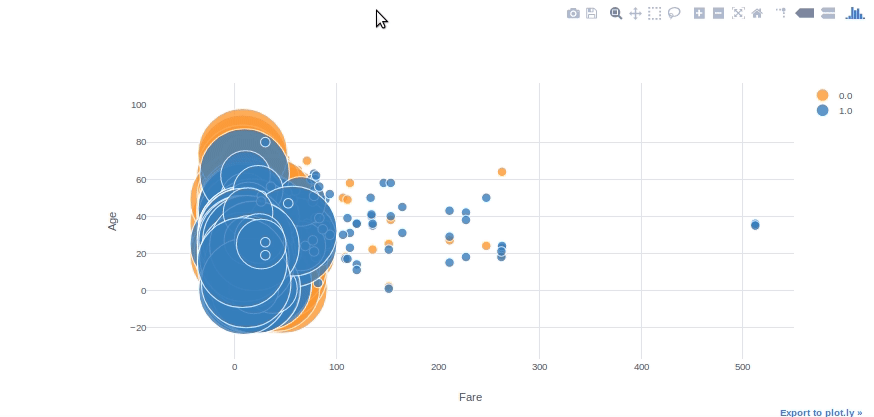
Grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia....
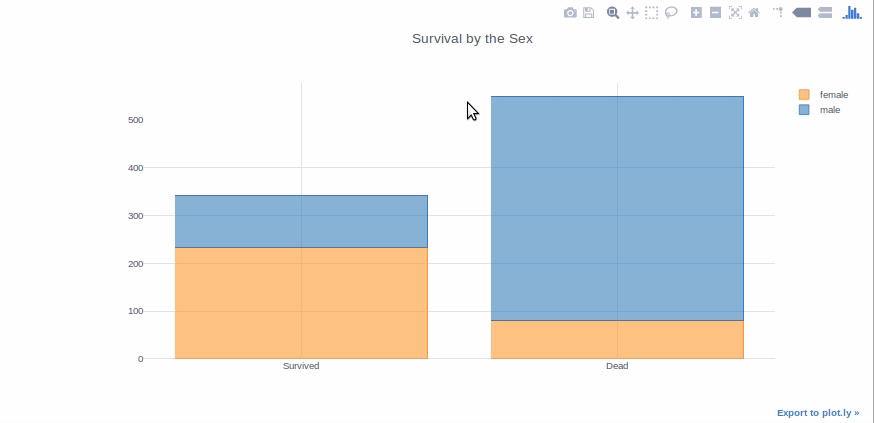
I grafici a barre sono utili per presentare i dati di diversi gruppi che vengono confrontati tra loro. Cosa c'è di più, può essere usato in pila per mostrare diversi effetti variabili. Faremo un grafico a barre per mostrare il conteggio dei passeggeri sopravvissuti per sesso.
sesso_sopravvissuto = df[df['Sopravvissuto']==1]['Sesso'].value_counts() dead_sex = df[df['Sopravvissuto']==0]['Sesso'].value_counts() df1 = pd.DataFrame([sesso_sopravvissuto,sesso_morto]) df1.index = ['Sopravvissuto','Morto'] df1.iplot(tipo='bar',moda da bar ="pila", titolo="Sopravvivenza del sesso")
Ho cercato di spiegare tutto il più semplice possibile. Spero sia più facile per i nuovi arrivati capire la trama.
Plotly fornisce anche grafici scientifici, Grafica 3D, mappe e animazioni. Puoi visitare la documentazione di plotly qui per ulteriori dettagli.
Dai un'occhiata a EDA – Analisi esplorativa dei dati con Python Pandas e SQL CLICCA PER LEGGERE
Nota finale
Grazie per aver letto!
Spero che l'articolo ti sia piaciuto e che abbia aumentato le tue conoscenze.
Per favore sentiti libero di contattarmi su E-mail
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Circa l'autore
Hardikkumar M. Dhaduk
Analista dati | Specialista nell'analisi dei dati digitali | Studente di Data Science
Connettiti con me su Linkedin
Connettiti con me su Github
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





