Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Il primo passo in un progetto di data science è riassumere, descrivere e visualizzare i dati. Cerca di conoscere diversi aspetti dei dati e dei suoi attributi. I migliori modelli sono creati da coloro che comprendono i loro dati.
Esplora le caratteristiche e gli attributi dei dati utilizzando le statistiche descrittive. Le informazioni dettagliate e il riepilogo numerico che ottieni dalle statistiche descrittive ti aiutano a comprendere meglio o a essere in grado di gestire i dati in modo più efficiente per le attività di apprendimento automatico.
Le statistiche descrittive sono il processo predefinito nell'analisi dei dati. Analisi esplorativa dei dati (EDA) non completo senza analisi statistica descrittiva.
Quindi, in questo articolo, Spiegherò gli attributi del set di dati utilizzando Statistiche descrittive. È diviso in due parti: MisurareIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... di punti dati centrali e misurazione della dispersione. Prima di iniziare la nostra analisi, dobbiamo completare la raccolta dei dati e il processo di pulizia.
Raccolta e pulizia dei dati
Raccoglieremo dati da qui. Userò solo i dati dei test per l'analisi. È possibile combinare test e dati da addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... per analisi. Ecco un codice per il processo di pulizia dei dati del treno.
Rimuovi dal codice
- Le colonne Item_Weight e Outlet_Size hanno valori null. Queste sono le opzioni:
-
- rimuovi le righe contenenti valori null
- rimuovere le colonne contenenti valori null
- o sostituisci i valori null.
- Il primo 2 le opzioni sono possibili quando i dati hanno righe in milioni o il conteggio dei valori è piccolo. Quindi, Sceglierò la terza opzione per risolvere il problema del valore nullo.
- Primo, trova l'Item_Identifier e il suo Item_Weight corrispondente. Quindi sostituisci ciò che manca / null in Item_Weight con il noto Item_weight del rispettivo item_identifier.
- Come sappiamo, la visibilità degli articoli in un negozio può essere vicina allo zero ma non zero. Quindi, Noi consideriamo 0 come valore null e seguiamo il passaggio precedente per Item_Visibility.
- Outlet_Size non è molto importante nella nostra analisi e previsione dei modelli. Quindi, Rilascio questa colonna.
- Sostituisci LF e reg nella colonna Item_fat_content con Low Fat e Regular Fat.
- Calcola l'età dei negozi e salva questi valori nella colonna Outlet_years e rilascia la colonna Outlet_Establishment_year.
Iniziamo con l'analisi dei dati della Statistica Descrittiva.
La misura del punto dati centrale
Trovare il data center numerico e categorico utilizzando la media, il medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... e la moda è conosciuta come Central Data Point Measurement. Calcolo dei valori centrali dei dati della colonna per media, mediana e modalità sono diverse l'una dall'altra.
Bene, poi, calcoliamo la media, mediano, il conteggio e la modalità degli attributi del set di dati utilizzando python.
- Raccontare
Il conteggio non aiuta direttamente a trovare il centro degli attributi del set di dati. Ma è usato nel calcolo della media, mediana e modalità. Calcoliamo il conteggio totale in ogni categoria delle variabili categoriali. Calcola anche il conteggio totale dei dati della colonna numerica.
Rimuovi dal codice.
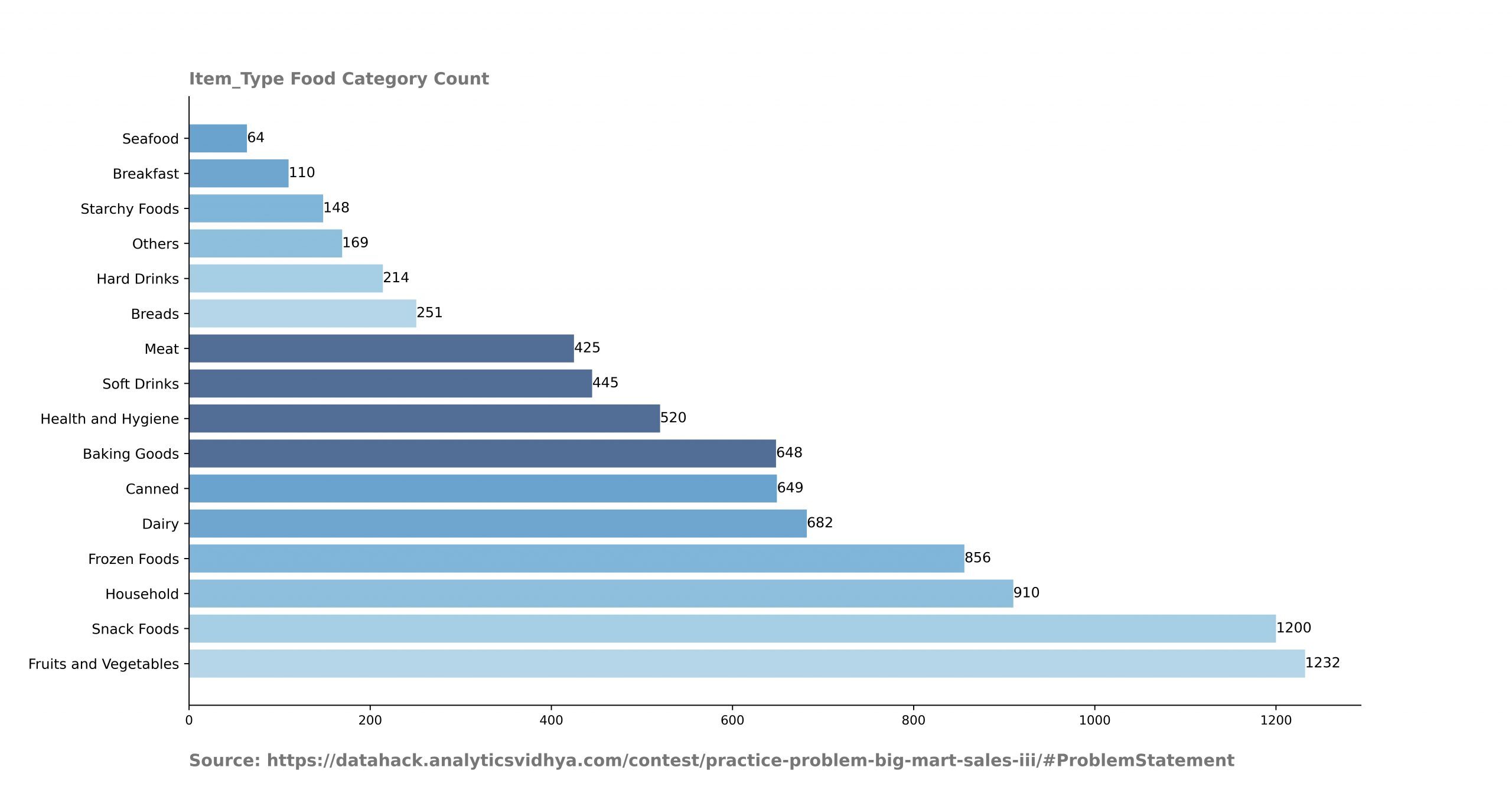
- Scorri le colonne categoriali per tracciare la categoria e il suo conteggio.
Analisi dell'output.
- Questi conteggi ti aiutano a scoprire se i dati sono bilanciati o meno. Da questo grafico, Posso dire che i ranghi della categoria frutta e verdura sono molto più che della categoria frutti di mare.
- Possiamo anche supporre che le vendite nella categoria frutta e verdura siano molto superiori a quelle della categoria frutti di mare..
-
per significare
La somma dei valori presenti nella colonna divisa per il numero totale di righe in quella colonna è nota come media. Conosciuto anche come medio.
Usare train.mean () calcolare il valore medio delle colonne numeriche nel set di dati del treno.
Ecco del codice per le colonne categoriali dal set di dati dei treni.
Stampa(treno[['Articolo_Outlet_Sales','Tipo_presa']].raggruppare per(['Tipo_presa']).agg({'Articolo_Outlet_Sales':'Significare'}))Analisi dell'output
- L'età media di partenza è 15 anni.
- Le vendite medie in uscita sono 2100.
- La categoria tipo supermercato 3 Outlet_Type's ha molte più vendite rispetto alla categoria del negozio di alimentari.
- Possiamo anche supporre che la categoria del supermercato sia più popolare della categoria del negozio di alimentari..
-
Mediano
Il valore centrale di un attributo è noto come mediana. Come calcoliamo il valore mediano?? Primo, ordina i dati della colonna in ordine crescente o decrescente. Quindi trova le righe totali e poi dividilo per 2.
Quel valore di output è la mediana di quella colonna.
Il valore mediano divide i punti dati in due parti. Ciò significa che 50% dei punti dati sono presenti sopra la mediana e il 50% sotto.
In genere, i valori mediana e media sono diversi per gli stessi dati.
La mediana non è influenzata dai valori anomali. A causa di valori anomali, la differenza tra i valori medi e mediani aumenta.
Usare train.median () calcolare il valore medio delle colonne numeriche nel set di dati del treno.
Ecco del codice per le colonne categoriali dal set di dati dei treni.
Stampa(treno[['Articolo_Outlet_Sales','Tipo_presa']].raggruppare per(['Tipo_presa']).agg({'Articolo_Outlet_Sales':'mediano'}))Analisi dell'output
- La maggior parte delle osservazioni è uguale al valore medio.
- La differenza nel valore medio e mediano è dovuta a valori anomali. Puoi anche osservare questa differenza nelle variabili categoriali.
- Modo
La modalità è quel punto dati il cui conteggio è il massimo in una colonna. C'è solo un valore medio e mediano per ogni colonna. Ma gli attributi possono avere più di un valore di modalità. Usare modalità.treno () calcolare il valore medio delle colonne numeriche nel set di dati del treno. Ecco del codice per le colonne categoriali del set di dati del treno.Stampa(treno[['Articolo_Outlet_Sales', 'Tipo_presa', 'Identificativo_uscita', 'Item_Identifier']].raggruppare per(['Tipo_presa']).agg(lambda x:x.value_counts().indice[0]))
Analisi dell'output
- Outlet_Type ha un valore di modalità. Tipo di supermercato 1. La categoria tipo supermercato 1 l'articolo o il valore della modalità più venduto è FDZ15.
- Item_Identifier FDH50 è l'articolo più venduto nella categoria Outlet_Type.
Misure di dispersione
Una misura della dispersione spiega quanto siano diversi i valori degli attributi nel set di dati. Conosciuto anche come misura di diffusione. Da questa statistica, conoscere come e perché i dati vengono propagati da un punto all'altro.
Queste sono le statistiche che entrano nella misura della dispersione.
- Distanza
- Percentili o quartili
- Deviazione standard
- Differenza
- Obliquità
-
Distanza
La differenza tra il valore massimo e il valore minimo in una colonna è nota come intervallo.
Ecco un codice per calcolare l'intervallo.
per io in num_col: Stampa(F"Colonna: {io} Max_Value: {max(treno[io])} Min_Value: {min(treno[io])} Gamma: {il giro(max(treno[io]) - min(treno[io]),2)}")Puoi anche calcolare il rango delle colonne categoriali. Ecco un codice per scoprire i valori minimo e massimo in ogni categoria di output.
Analisi dell'output
- La gamma di Item_MRP e Item_Outlet_sales è alta e potrebbe richiedere una trasformazione.
- C'è una grande variazione in Item_MRP nella categoria del tipo di supermercato 3.
- Percentili o quartiliPossiamo descrivere la distribuzione dei valori delle colonne calcolando il riassunto di più percentili. La mediana è anche conosciuta come percentile 50 dei dati. Ecco un percentile diverso.
- Il valore minimo è uguale al percentile 0.
- Il valore massimo è uguale al percentile 100.
- Il primo quartile è uguale al percentile 25.
- Il terzo quartile è uguale al percentile 75.
Ecco un codice per calcolare i quartili.
La differenza tra 3rd e il 1Ns Il quartile è anche noto come interquartile (IQR). Cosa c'è di più, i punti dati massimi sono inclusi in IQR.

-
Deviazione standard
Il valore della deviazione standard ci dice quanto tutti i punti dati si discostano dal valore medio. La deviazione standard è influenzata dai valori anomali perché utilizza la media per il suo calcolo.
Ecco un codice per calcolare la deviazione standard.
per io in num_col: Stampa(io , il giro(treno[io].standard(),2))I panda hanno anche una scorciatoia per calcolare tutti i valori statistici di cui sopra.
Train.descrivi()
- DifferenzaLa varianza è il quadrato della deviazione standard. In caso di outlier, il valore della varianza diventa grande e evidente. Perciò, è influenzato anche da outlier. Ecco un codice per calcolare la varianza
per io in num_col: Stampa(io , il giro(treno[io].dove(),2))Analisi dell'output.
- Le colonne Item_MRP e Item_Outlet_sales hanno una grande varianza a causa di valori anomali.
-
Obliquità
Idealmente, la distribuzione dei dati dovrebbe essere in forma gaussiana (campana curva). Ma praticamente, le forme dei dati sono distorte o distorte. Questo è noto come skew nei dati..
Puoi calcolare l'asimmetria dei dati del treno usando treno.skew (). Il valore di bias può essere negativo (sinistra) il positivo (Giusto). Il suo valore deve essere vicino a zero.
Note finali
Queste sono le statistiche a cui ci rivolgiamo quando eseguiamo analisi esplorative dei dati sul set di dati. Dovresti prestare attenzione ai valori generati da queste statistiche e chiedere perché questo numero. Queste statistiche ci aiutano a determinare gli attributi per la trasformazione dei dati e la rimozione delle variabili dalla post-elaborazione..
La libreria Pandas ha funzioni davvero buone che ti aiutano a ottenere valori statistici descrittivi in una riga di codice.





