introduzione
Hai mai risolto un problema di apprendimento automatico una tantum??
Risolvere un problema utilizzando l'apprendimento automatico non è facile. Richiede diversi passaggi per arrivare a una soluzione precisa. Il processo / pasos a seguir para resolver un problema de ml se conoce como ML OleodottoPipeline è un termine che viene utilizzato in una varietà di contesti, principalmente nella tecnologia e nella gestione dei progetti. Si riferisce a un insieme di processi o fasi che consentono il flusso continuo di lavoro dal concepimento di un'idea alla sua realizzazione finale. Nel campo dello sviluppo software, ad esempio, Una pipeline può includere la programmazione, Test e distribuzione, garantendo così una maggiore efficienza e qualità nel... / Ciclo ML.
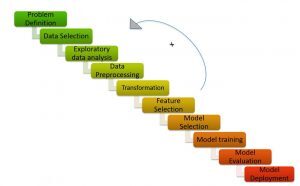
ML Pipeline / Ciclo ML (Titoli di coda: https://medium.com/analytics-vidhya/machine-learning-development-life-cycle-dfe88c44222e)
Como se muestra en la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline...., La pipeline di Machine Learning consiste in diversi passaggi come:
Comprendere l'affermazione del problema, generazione di ipotesi, analisi esplorativa dei dati, pre-elaborazione dei dati, ingegneria delle caratteristiche, selezione delle funzioni, costruzione di modelli, adattamento del modello e implementazione del modello.
Consiglierei di leggere gli articoli seguenti per ottenere una comprensione dettagliata della pipeline di machine learning:
- Spiegazione del ciclo di vita del machine learning!
- Passaggi per completare un progetto di machine learning
Il processo di risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... de un problema de aprendizaje automático implica mucho tiempo y esfuerzo humano. evviva! Non è più un processo noioso e dispendioso in termini di tempo! Grazie ad AutoML per aver fornito soluzioni istantanee ai problemi di machine learning.
AutoML si basa sulla creazione automatica del modello ad alte prestazioni con il minimo intervento umano.
Le librerie AutoML offrono programmazione low-code e no-code.
Probabilmente hai sentito parlare dei termini “codice basso” e “senza codice”.
- Senza codice I framework sono semplici interfacce utente che consentono anche agli utenti non tecnici di creare modelli senza scrivere una sola riga di codice.
- Codice basso si riferisce alla codifica minima.
Aunque las plataformas sin código facilitan el addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... de un modelo de aprendizaje automático mediante una interfaz de arrastrar y soltar, sono limitati in termini di flessibilità. Il basso codice ML, In secondo luogo, è il punto ottimo e il termine medio, in quanto offrono flessibilità e codice facile da usare.
In questo articolo, Capiamo come costruire un modello di classificazione del testo all'interno di poche righe di codice utilizzando una libreria AutoML a basso codice, PyCaret.
Sommario
- Cos'è PyCaret?
- Perché abbiamo bisogno di PyCaret?
- Diversi approcci per risolvere la classificazione del testo in PyCaret
- Modellazione a tema
- Conta vettori
- Argomento di studio: classificazione del testo con PyCaret
Cos'è PyCaret?
PyCaret è una libreria di apprendimento automatico open source a basso codice in Python che ti consente di passare dalla preparazione dei dati all'implementazione del modello in pochi minuti..

PyCaret (Titoli di coda: https://pycaret.org/)
PyCaret è essenzialmente una libreria a basso codice che sostituisce centinaia di righe di codice in scikit impara a 5-6 righe di codice. Aumenta la produttività del team e aiuta il team a concentrarsi sulla comprensione del problema e sulle caratteristiche tecniche piuttosto che sull'ottimizzazione del modello.
PyCaret (Titoli di coda: https://pycaret.org/about/)
PyCaret è basato su una libreria di apprendimento scikit. Di conseguenza, tutti gli algoritmi di apprendimento automatico disponibili in scikit learn sono disponibili in pycaret. Di seguito, PyCaret può risolvere problemi relativi alla classificazione, regressione, raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.., rilevamento anomalie, classificazione del testo, regole e serie temporali associate all'estrazione mineraria.
Ora, Analizziamo le ragioni dietro l'utilizzo di PyCaret.
Perché abbiamo bisogno di PyCaret?
PyCaret crea automaticamente il modello di riferimento dato un set di dati all'interno 5-6 righe di codice. Vediamo come pycaret semplifica ogni passaggio nella pipeline del machine learning.
- Preparazione dei dati: PyCaret esegue la pulizia e la preelaborazione dei dati con il minimo intervento manuale.
- Ingegneria delle funzioni: PyCaret crea automaticamente le caratteristiche matematiche e seleziona le caratteristiche più importanti necessarie per il modello
- Costruzione del modello: Semplifica notevolmente la parte di modellazione del tuo progetto. Possiamo costruire diversi modelli e selezionare i modelli più performanti con una sola riga di codice.
- Vestibilità del modello: PyCaret ottimizza il modello senza passare esplicitamente iperparametri a ciascun modello.
Prossimo, ci concentreremo sulla risoluzione di un problema di classificazione del testo in PyCaret.
Diversi approcci per risolvere la classificazione del testo in PyCaret
Risolviamo un problema di classificazione del testo in PyCaret usando 2 diverse tecniche:
- Modellazione a tema
- Conta vettori
Toccherò ogni punto in dettaglio
Modellazione a tema
Modellazione a tema, Come il nome suggerisce, è una tecnica per identificare diversi temi presenti nei dati di testo.
I temi sono definiti come un gruppo ripetuto di simboli (o parole) statisticamente significativo in un corpus. Qui, la significatività statistica si riferisce a parole importanti nel documento. Generalmente, le parole che appaiono frequentemente con punteggi TF-IDF più alti sono considerate parole statisticamente significative.
La modellazione degli argomenti è una tecnica non supervisionata per trovare automaticamente argomenti nascosti nei dati di testo. Può anche essere chiamato l'approccio di estrazione del testo per trovare modelli ricorrenti nei documenti di testo.
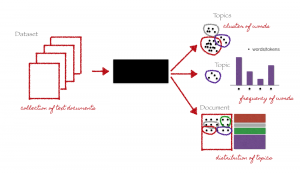
Modellazione a tema (Titoli di coda: https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045)
Alcuni casi d'uso comuni per la modellazione dei temi includono quanto segue:
-  Risolvere problemi di classificazione / regressione del testo
- Crea tag rilevanti per i documenti
- Generare informazioni per i moduli di feedback dei clienti, recensioni dei clienti, risultati del sondaggio, eccetera.
Esempio di modellazione del tema
Supponi di lavorare per uno studio legale e di lavorare con un'azienda in cui è stato sottratto denaro e sai che ci sono informazioni chiave nelle e-mail che sono state distribuite nell'azienda.
- Quindi, controlla le email e ci sono centinaia di migliaia di email. Ora, quello che devi fare è scoprire quali sono legati al denaro rispetto ad altri argomenti.
- Puoi etichettarli a mano in base a ciò che leggi nel testo, che richiederebbe molto tempo, oppure puoi usare la tecnica chiamata modellazione del tema per scoprire cosa sono questi tag e taggare automaticamente tutte queste email.
Come spiegato sopra, l'obiettivo della modellazione del tema è estrarre temi diversi dal testo grezzo. Ma, Qual è l'algoritmo sottostante per raggiungerlo??
Questo ci porta ai diversi algoritmi / tecniche per modellare temi: assegnazione latente dirichlet (LDA), fattorizzazione di matrici non negative (NNMF), assegnazione semantica latente (LSA).
Consiglierei di fare riferimento alle seguenti risorse per leggere in dettaglio gli algoritmi
- Parte 2: Modellazione del tema e assegnazione latente di Dirichlet (LDA) usando Gensim e Sklearn
- Guida per principianti alla modellazione di temi in Python
- Modellazione a tema con LDA: un'introduzione pratica
Venendo alla modellazione a tema, è un processo di 2 Passi:
- Distribuzione dell'argomento del termine: Trova gli argomenti più importanti nel corpus.
- Distribuzione da documento a argomento: Assegna punteggi per ogni argomento a ciascun documento.
Avendo capito la modellazione del tema, vedremo come risolvere la classificazione del testo utilizzando la modellazione degli argomenti con l'aiuto di un esempio.
Considera un corpus:
- Documento 1: Voglio della frutta a colazione.
- Documento 2: mi piace mangiare le mandorle, uova e frutta.
- Documento 3: Porterò frutta e biscotti con me quando andrò allo zoo.
- Documento 4: Il guardiano dello zoo nutre il leone con molta attenzione.
- Documento 5: Biscotti di buona qualità vanno dati ai vostri cani.
L'algoritmo di modellazione del tema (LDA) identifica gli argomenti più importanti nei documenti.
- Tema 1: 30% frutta, 15% uova, 10% biscotti,… (pasto)
- Tema 2: 20% Leone, 10% cani, 5% Zoo,… (animali)
Prossimo, assegnare punteggi per ogni argomento ai documenti come segue.
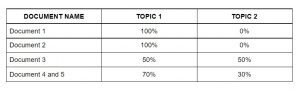
Assegna argomenti a ciascun documento utilizzando LDA
Questa matrice agisce come caratteristiche dell'algoritmo di apprendimento automatico. Prossimo, vedremo la borsa delle parole.
Borsa di parole
Borsa Di Parole (ARCO) è un altro algoritmo popolare per rappresentare il testo in numeri. Dipende dalla frequenza delle parole nel documento. BOW ha numerose applicazioni come la classificazione dei documenti, modellazione del tema e somiglianza del testo. E INCHIOSTRO, ogni documento è rappresentato come la frequenza delle parole presenti nel documento. Quindi, la frequenza delle parole rappresenta l'importanza delle parole nel documento.
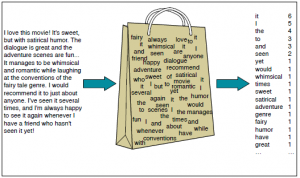
Borsa di parole (Titoli di coda: Jurafsky et al., 2018)
Segui l'articolo qui sotto per ottenere una comprensione dettagliata di Bag Of Words:
Nella prossima sezione, risolveremo il problema della classificazione del testo in PyCaret.
Argomento di studio: classificazione del testo con PyCaret
Comprendiamo l'affermazione del problema prima di risolverlo.
Comprendere l'affermazione del problema
Steam è un servizio di distribuzione di videogiochi digitali con una vasta comunità di giocatori in tutto il mondo. Molti giocatori scrivono recensioni sulla pagina del gioco e hanno la possibilità di scegliere se consigliare questo gioco ad altri o meno.. tuttavia, determinare automaticamente questo sentimento dal testo può aiutare Steam a contrassegnare automaticamente le recensioni prese da altri forum su Internet e può aiutarli a giudicare meglio la popolarità dei giochi.
Dato il testo della recensione con la raccomandazione dell'utente, il compito è prevedere se il revisore ha consigliato i titoli dei giochi disponibili nel set di test in base al testo della recensione e ad altre informazioni.
In termini più semplici, il compito da svolgere è identificare se una determinata recensione dell'utente è buona o cattiva. Puoi scaricare il set di dati da qui.
Implementazione
Per valutare le recensioni dei giochi Steam utilizzando PyCaret, ho discusso 2 diversi approcci nell'articolo.
- Il primo approccio utilizza la modellazione del tema utilizzando PyCaret.
- Il secondo approccio utilizza le caratteristiche di Bag Of Words. Usa queste funzioni per la classificazione usando PyCaret.
Attueremo l'approccio BOW ora.
Nota: Il tutorial è implementato in Google Colab. Consiglierei di eseguire il codice al suo interno.
Installazione PyCaret
Puoi installare PyCaret come qualsiasi altra libreria Python.
- Installa PyCaret su Google Colab o Azure Notebooks
Importazione di librerie
Caricamento dati
In che modo PyCaret non supporta il vettore di conteggio, importare il modulo CountVectorizer da sklearn.feature_extraction.
Dopo, Inizializzo un oggetto CountVectorizer chiamato 'tf_vectorizer'.
Cosa fa esattamente la funzione fit_transform con i tuoi dati??
- “Regolare” estrae le caratteristiche del set di dati.
- “Trasformare” esegue effettivamente le trasformazioni sul set di dati.
Convertiamo l'output di fit_transform nel frame di dati.
Ora, concatenare le caratteristiche e l'obiettivo lungo la colonna.
Prossimo, divideremo il set di dati in dati di test e training.
Ora che l'estrazione delle caratteristiche è terminata. Usiamo queste funzioni per costruire modelli diversi. Quindi, il prossimo passo è configurare l'ambiente in PyCaret.
Impostazione dell'ambiente
- Questa funzione imposta il quadro formativo e costruisce il processo di transizione. La funzione di configurazione deve essere chiamata prima di poter chiamare qualsiasi altra funzione.
- L'unico parametro obbligatorio sono i dati e l'obiettivo.
Creazione di modelli
Vestibilità del modello
Dall'uscita precedente, possiamo vedere che le metriche del modello adattato sono migliori delle metriche del modello base.
Valutare e prevedere il modello
Qui, Ho previsto i valori dei flag per il nostro set di dati elaborati, 'tuned_lightgbm'.
Note finali
PyCaret, addestramento di modelli di machine learning in un ambiente low-code, ha suscitato il mio interesse. Dal tuo ambiente laptop preferito, PyCaret ti aiuta a passare dalla preparazione dei dati all'implementazione del modello in pochi secondi. Prima di usare PyCaret, Ho provato altri metodi tradizionali per risolvere il problema dell'hackathon NLP JanataHack, Ma i risultati non sono stati molto soddisfacenti!!
PyCaret ha dimostrato di essere esponenzialmente veloce ed efficiente rispetto alle altre librerie di machine learning open source e ha anche il vantaggio di sostituire più righe di codice con poche parole..
Qui, se eviti la prima parte del mio approccio in cui utilizzo le tecniche di incorporamento del vettore di conteggio nel mio set di dati e poi passo alla configurazione e alla creazione di modelli utilizzando PyCaret, poi puoi notare che tutte le trasformazioni, come la codifica a caldo , l'imputazione dei valori perduti, eccetera., accadrà automaticamente dietro le quinte, e poi otterrai un frame di dati con le previsioni, Come quello che abbiamo!
Spero di aver chiarito il mio approccio generale all'hackathon.





