introduzione
“I dati sono il carburante per gli algoritmi di apprendimento automatico”.
Prima di cercare informazioni dai dati, dobbiamo prima eseguire attività di pre-elaborazione che poi ci consentono solo di utilizzare quei dati per ulteriori osservazioni e addestrare il nostro modello di apprendimento automatico.
La correzione del valore mancante è necessaria per ridurre la distorsione e produrre potenti modelli adatti. La maggior parte degli algoritmi non è in grado di gestire i dati mancanti, quindi devi agire in qualche modo per non lasciare che il tuo codice si blocchi. Quindi, iniziamo con i metodi per risolvere il problema.
Metodi per trattare i valori mancanti
Esempio 1, Diamo un set di dati fittizi in cui ci sono tre caratteristiche indipendenti (predittori) e una caratteristica dipendente (Rispondere).
| Caratteristica-1 | Caratteristica-2 | Caratteristica-3 | Produzione |
| Maschile | 23 | 24 | sì |
| – – – – | 24 | 25 | No |
| Donna | 25 | 26 | sì |
| Maschile | 26 | 27 | sì |
Qui, abbiamo un valore mancante nella riga 2 per la funzione-1.
I metodi popolari utilizzati dalla comunità di apprendimento automatico per gestire il valore mancante delle variabili categoriali nel set di dati sono i seguenti:
1. Elimina le osservazioni: Se c'è un gran numero di osservazioni nel set di dati, dove tutte le classi da prevedere sono sufficientemente rappresentate nei dati di allenamento, prova a rimuovere le osservazioni sui valori mancanti, che non genererebbe modifiche significative al tuo feed dal tuo modello.
Ad esempio, 1, Implementa questo metodo su un dato set di dati, possiamo rimuovere l'intera riga contenente i valori mancanti (elimina riga-2).
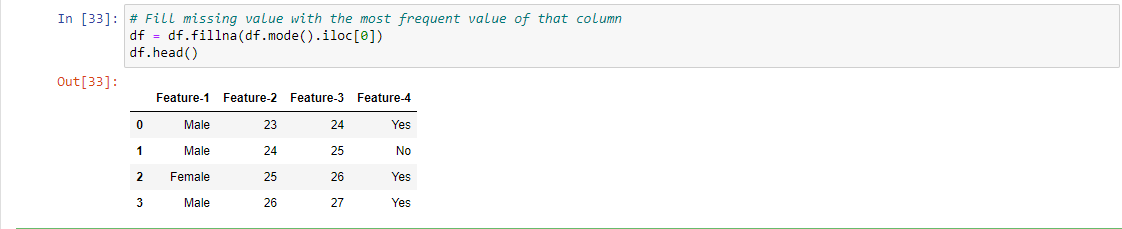
2. Sostituisci i valori mancanti con il valore più frequente: Puoi sempre addebitarli in base a Modo nel caso di variabili categoriali, assicurati di non avere distribuzioni di classi molto distorte.
NOTA: Ma in alcuni casi, questa strategia può rendere sbilanciati i dati nelle classi wrt se ci sono molti valori mancanti presenti nel nostro dataset.
– In genere, sostituire i valori mancanti con media / medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... / la moda è un modo rozzo di affrontare i valori mancanti. A seconda del contesto, como si la variación es baja o si la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... tiene un apalancamiento bajo sobre la respuesta, un'approssimazione così approssimativa è accettabile e potrebbe dare risultati soddisfacenti. In questo caso, visto che dici che è una variabile categoriale, questo passaggio potrebbe non essere applicabile.
Ad esempio, 1, Per implementare questo metodo, sostituiamo il valore mancante con il valore più frequente per quella particolare colonna, qui sostituiamo il valore mancante con Maschio poiché il conteggio di Maschio è maggiore di Femmina (maschio = 2 e femminile = 1).
3. Sviluppa un modello per prevedere i valori mancanti: Un modo intelligente per farlo potrebbe essere addestrare un classificatore sulle colonne dei valori mancanti come variabile dipendente rispetto ad altre caratteristiche nel set di dati e provare a eseguire l'imputazione in base al classificatore appena addestrato.
Ecco l'algoritmo che puoi seguire:
– Dividi i dati in due parti. Una parte avrà i valori correnti della colonna, inclusa la colonna di output originale, l'altra parte avrà le righe con i valori mancanti.
– Dividi la prima parte (valori attuali) in un set di convalida incrociata per la selezione del modello.
– Addestra i tuoi modelli e testa le tue metriche con dati a convalida incrociata. Puoi anche eseguire una ricerca a griglia o una ricerca casuale per ottenere i migliori risultati.
– Finalmente, con il modello, prevede valori sconosciuti mancanti dal nostro problema.
NOTA: Dal momento che stai cercando di imputare i valori mancanti, le cose saranno più piacevoli in questo modo, poiché non sono di parte e ottieni le migliori previsioni dal miglior modello.
Ad esempio, 1, Per attuare la strategia data, per prima cosa considereremo la colonna Caratteristica-2, Feature-3 e Output per il nostro nuovo classificatore, cosa significa che sei? 3 Le colonne sono utilizzate come caratteristiche indipendenti per il nostro nuovo classificatore e Caratteristica-1 è considerata un risultato e una nota oggettiva che qui consideriamo solo le righe che non mancano, poiché i dati del nostro treno e le osservazioni che hanno un valore mancante diventeranno i nostri dati di prova. Dobbiamo fare la previsione usando il nostro modello sui dati del test e, dopo le previsioni, abbiamo il set di dati a cui non manca alcun valore.
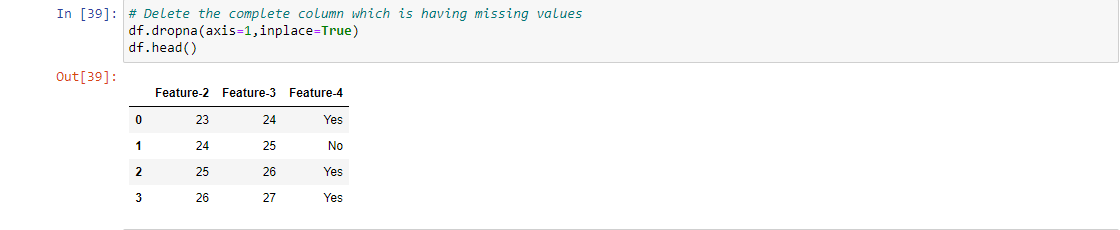
4. Eliminando la variabile: Se c'è un insieme eccezionalmente più grande di valori mancanti, prova a escludere la variabile stessa per un modello aggiuntivo, ma devi assicurarti che non sia molto significativo prevedere la variabile target, vale a dire, la correlazione tra la variabile scartata e la variabile target è molto bassa o ridondante.
Ad esempio, 1, Per implementare questa strategia per gestire i valori mancanti, dobbiamo rimuovere l'intera colonna che contiene i valori mancanti, quindi per un dato set di dati rimuoviamo completamente Caratteristica-1 e utilizziamo solo le caratteristiche a sinistra per prevedere la nostra variabile di destinazione.
5. Applicare tecniche di apprendimento automatico senza supervisione: In questo approccio, usiamo tecniche non supervisionate come K-significa, Raggruppamento gerarchico, eccetera. L'idea è che puoi saltare quelle colonne che hanno valori mancanti e considerare tutte le altre colonne tranne la colonna di destinazione e provare a creare il massimo di nessun cluster di caratteristiche indipendenti (dopo aver rimosso le colonne dei valori mancanti), finalmente trova la categoria in cui cade la riga mancante.
Ad esempio, 1, Per attuare questa strategia, eliminiamo la colonna Caratteristica-1 e quindi utilizziamo Caratteristica-2 e Caratteristica-3 come nostre caratteristiche per il nuovo classificatore e quindi, Finalmente, después de la formación del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro...., proviamo a guardare in quale cluster si trova il record mancante e siamo pronti con il nostro set di dati finale per ulteriori analisi.
Implementazione Python
Importa le dipendenze richieste.
![]()
Carica e leggi il set di dati.

Trova il numero di valori mancanti per colonna.

Applicare la strategia-1 (rimuovere le osservazioni mancanti).

Applica Strategia-2 (Sostituisci i valori mancanti con il valore più frequente).
Applicare la strategia-3 (Rimuovi la variabile che ha valori mancanti).
Applicare la strategia 4 (Sviluppa un modello per prevedere i valori mancanti).
Per questa strategia, prima codifichiamo le nostre colonne categoriali indipendenti usando "One Hot Encoder" e le colonne categoriali dipendenti usando "Label Encoder".
– Leggere e caricare il set di dati codificato.

– Crea record mancanti come i nostri dati di test.
– Haga registros que no falten como nuestros datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
– Separare variabili indipendenti e dipendenti.
![]()
– Adatta il nostro modello di regressione logistica.

– Prevedi la classe dei record mancanti.

Questo completa la nostra parte di implementazione!!
Note finali
Grazie per aver letto!
Questo articolo ti introduce a diversi modi per affrontare il problema di avere valori mancanti per le variabili categoriali..
Se ti è piaciuto e vuoi saperne di più, visita gli altri miei articoli sulla scienza dei dati e sull'apprendimento automatico facendo clic sul collegamento
Sentiti libero di contattarmi a Linkedin, E-mail.
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Fino ad allora, stare a casa, stare al sicuro per prevenire la diffusione di COVID-19, E continua a imparare!
Circa l'autore
Chirag Goyal
Attualmente, Sto perseguendo il mio Bachelor of Technology (B.Tech) in informatica e ingegneria da l'Indian Institute of Technology Jodhpur (IITJ). Sono molto entusiasta dell'apprendimento automatico, il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... e intelligenza artificiale.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





