introduzione
Il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... está ganando fuerza rápidamente a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que surgen más y más artículos de investigación de todo el mundo. Decisamente, questi documenti contengono una grande quantità di informazioni, ma spesso possono essere difficili da analizzare. E per capirli, potresti dover rivedere quel documento più volte (E forse anche altri documenti dipendenti!).
Questo è davvero un compito arduo per i non accademici come noi..

Personalmente, Trovo il compito di rivedere un articolo di ricerca, interpretare il punto cruciale e implementare il codice come un'abilità importante che ogni appassionato e praticante di deep learning dovrebbe possedere. L'implementazione pratica delle idee di ricerca fa emergere il processo di pensiero dell'autore e aiuta anche a trasformare tali idee in applicazioni industriali del mondo reale..
Quindi, in questo articolo (e la seguente serie di articoli) il motivo per cui scrivo è duplice:
- Consenti ai lettori di tenere il passo con la ricerca all'avanguardia suddividendo gli articoli di deep learning in concetti comprensibili.
- Impara a trasformare le idee di ricerca in codice per me stesso e incoraggia le persone a farlo contemporaneamente.
Questo articolo presuppone che tu abbia una buona conoscenza delle basi del deep learning.. Nel caso non ne avessi bisogno, o hai solo bisogno di un aggiornamento, controlla prima gli articoli qui sotto, poi torna qui presto:
Sommario
- Riepilogo documento “Immergiti nelle convoluzioni”
- Obiettivo del lavoro
- Dettagli architettonici proposti
- Metodologia di allenamento
- Implementazione di GoogLeNet in Keras
Riepilogo documento “Immergiti nelle convoluzioni”
Questo articolo si concentra sulla carta “Scava più a fondo con le convoluzioni” da dove nasce l'idea distintiva della homenet. La rete domestica una volta era considerata un'architettura (il modello) deep learning di nuova generazione per risolvere i problemi di riconoscimento e rilevamento delle immagini.
Prestazioni rivoluzionarie in primo piano nell'ImageNet Visual Recognition Challenge (Su 2014), che è una piattaforma rinomata per il benchmarking degli algoritmi di riconoscimento e rilevamento delle immagini. insieme a questo, sono state avviate molte ricerche sulla creazione di nuove architetture di deep learning con idee innovative e di impatto.
Esamineremo le principali idee e suggerimenti proposti nel documento sopra menzionato e cercheremo di comprendere le tecniche in esso contenute. Nelle parole dell'autore:
“In questo articolo, nos centraremos en una arquitectura de neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. profunda eficiente para la visión por computadora, il cui nome in codice è Inception, che deriva il suo nome da (…) il famoso meme di internet” dobbiamo approfondire “.

Sembra intrigante, no? Bene, Continua a leggere allora!
Obiettivo del lavoro
Esiste un modo semplice ma potente per creare modelli di deep learning migliori. Puoi semplicemente fare un modello più grande, sia in termini di profondità, vale a dire, numero di strati, o il numero di neuroni in ogni strato. Ma come puoi immaginare, questo spesso può creare complicazioni:
- Più grande è il modello, più incline alla regolazione eccessiva. Esto es particularmente notable cuando los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... son pequeños.
- Aumentar la cantidad de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... significa que necesita aumentar sus recursos computacionales existentes
Una soluzione per questo, come suggerisce il documento, è passare ad architetture di rete poco connesse che sostituiranno le architetture di rete completamente connesse, specialmente all'interno degli strati convoluzionali. Questa idea può essere concettualizzata nelle immagini seguenti:
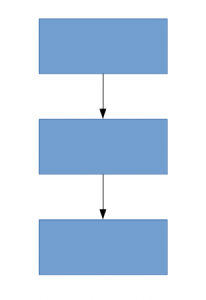
Architettura densamente connessa
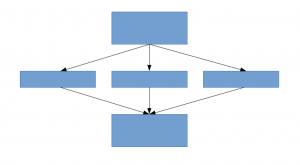
Architettura scarsamente connessa
Questo articolo propone una nuova idea di creare architetture profonde. Questo approccio consente di mantenere “budget computazionale”, aumentando la profondità e la larghezza della rete. Sembra troppo bello per essere vero! Ecco come appare l'idea concettualizzata:
Vediamo un po' più in dettaglio l'architettura proposta.
Dettagli architettonici proposti
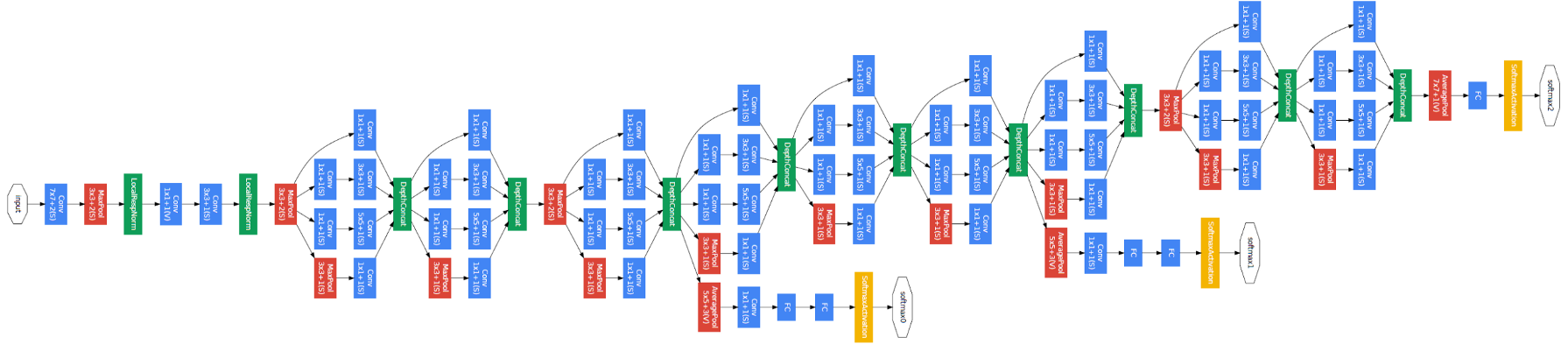
Il documento propone un nuovo tipo di architettura: GoogLeNet o Inception v1. Es básicamente una convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. (CNN) che cosa c'è che non va 27 strati profondi.. Di seguito il riepilogo del modello:

Nota nell'immagine sopra che c'è un livello chiamato livello iniziale. Questa è in realtà l'idea principale alla base del focus del documento. Il livello iniziale è il concetto centrale di un'architettura liberamente connessa.
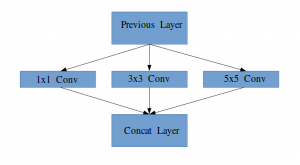
Idea di un modulo di partenza
Lascia che ti spieghi un po' più in dettaglio di cosa tratta un livello di avvio. Tomando un estrarreL'estratto è una sostanza ottenuta concentrando composti di origine vegetale, animale o minerale. Utilizzato in una varietà di applicazioni, come l'industria alimentare, Farmaceutico e cosmetico. Gli estratti possono essere presentati in forma liquida, in polvere o sotto forma di tinture, e la sua produzione prevede tecniche come la macerazione, distillazione o estrazione con solvente. Il suo utilizzo permette di sfruttare in modo più ampio le proprietà benefiche degli ingredienti originali.. del artículo:
“(Livello iniziale) è una combinazione di tutti quegli strati (vale a dire, copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale.. 1 × 1, copertina convolutiva 3 × 3, copertina convolutiva 5 × 5) con i loro banchi di filtri di uscita concatenati in un unico vettore di uscita che costituisce l'ingresso del seguente scenario.”
Insieme agli strati sopra menzionati, ci sono due plugin principali nel livello iniziale originale:
- copertina convolutiva 1 × 1 prima di applicare un'altra mano, che viene utilizzato principalmente per la riduzione della dimensionalità
- Un livello di raggruppamento massimo parallelo, che fornisce un'altra opzione al livello iniziale
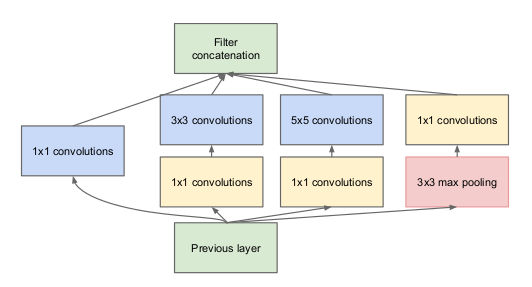
Livello iniziale
Per comprendere l'importanza della struttura del livello iniziale, l'autore attinge al principio hebbiano dell'apprendimento umano. Questo dice che “neuroni che si attivano insieme, si connettono insieme”. L'autore suggerisce che Quando si crea un post layer in un modello di deep learning, attenzione dovrebbe essere prestata agli apprendimenti dal livello precedente.
supponiamo, ad esempio, che uno strato del nostro modello di apprendimento profondo ha imparato a concentrarsi sulle singole parti di un viso. Il livello successivo della rete si concentrerebbe probabilmente sulla faccia generale dell'immagine per identificare i diversi oggetti presenti lì. Ora, per fare questo, il livello deve avere le dimensioni del filtro appropriate per rilevare oggetti diversi.
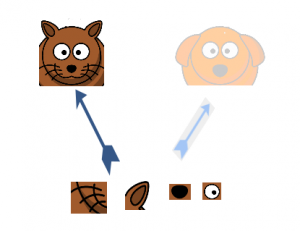
È qui che viene alla ribalta lo strato iniziale. Consente agli strati interni di selezionare e scegliere quale dimensione del filtro sarà rilevante per conoscere le informazioni richieste. Quindi, anche se la dimensione del viso nella foto è diversa (come si vede nelle immagini qui sotto), il mantello funziona di conseguenza per riconoscere il viso. Per la prima immagine, probabilmente avresti bisogno di una dimensione del filtro più alta, mentre ne prenderei una più bassa per la seconda immagine.

Architettura generale, con tutte le specifiche, sembra così:
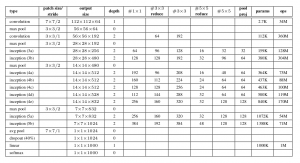
Metodologia di allenamento
Si noti che questa architettura è nata in gran parte perché gli autori hanno partecipato a una sfida di rilevamento e riconoscimento delle immagini.. Perciò, ce ne sono in abbondanza “campane e fischi” che hanno spiegato nel documento. Questi includono:
- L'hardware che hanno usato per addestrare i modelli.
- La tecnica di aumento dei dati per creare il set di dati di addestramento.
- Gli iperparametri della rete neurale, come la tecnica di ottimizzazione e il programma del tasso di apprendimento.
- Formazione ausiliaria necessaria per addestrare il modello.
- Tecniche di assemblaggio utilizzate per costruire la presentazione finale.
Tra questi, la formazione ausiliaria svolta dagli autori è piuttosto interessante e nuova per natura. Quindi per ora ci concentreremo su questo.. I dettagli del resto delle tecniche possono essere presi dall'articolo stesso, o nella realizzazione che vedremo di seguito.
Per evitare che la parte centrale della rete "sparisca", gli autori hanno introdotto due classificatori ausiliari (i quadrati viola nell'immagine). Fondamentalmente, applicato softmax alle uscite di due dei moduli starter e calcolato una perdita ausiliaria sulle stesse etichette. Il Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... total es una suma ponderada de la pérdida auxiliar y la pérdida real. Il valore di peso utilizzato sulla carta era 0,3 per ogni perdita ausiliaria.
Implementazione di GoogLeNet in Keras
Ora che hai capito l'architettura di GoogLeNet e l'intuizione che c'è dietro, È ora di avviare Python e implementare le nostre conoscenze utilizzando Keras!! Useremo il set di dati CIFAR-10 per questo scopo.

CIFAR-10 è un popolare set di dati per la classificazione delle immagini. Esso consiste in 60.000 immagini di 10 Lezioni (ogni classe è rappresentata come una riga nell'immagine sopra). Il set di dati è suddiviso in 50.000 immagini di allenamento e 10.000 immagini di prova.
Tieni presente che devi avere le librerie necessarie installate per implementare il codice che vedremo in questa sezione. Questo include Keras e TensorFlow (come backend per Keras). Puoi controllare il guida ufficiale all'installazione nel caso tu non abbia già installato Keras sulla tua macchina.
Ora che ci siamo occupati dei prerequisiti, possiamo finalmente iniziare a codificare la teoria che abbiamo trattato nelle sezioni precedenti. La prima cosa che dobbiamo fare è importare tutte le librerie e i moduli necessari che useremo nel codice.
importare duro
a partire dal hard.layers.core importare Strato
importare keras.backend come K
importare flusso tensoriale come tf
a partire dal hard.dataset importare cifar10
a partire dal hard.models importare Modello
a partire dal hard.layers importare Conv2D, MaxPool2D,
Ritirarsi, Denso, Ingresso, concatenare,
GlobalMediaPooling2D, Media Pooling2D,
Appiattire
importare cv2
importare insensibile come per esempio
a partire dal hard.dataset importare cifar10
a partire dal duro importare backend come K
a partire dal hard.utils importare np_utils
importare matematica
a partire dal hard.optimizers importare SGD
a partire dal forte.richiamate importare Apprendimento RateScheduler
Quindi caricheremo il set di dati e faremo alcuni passaggi di pre-elaborazione. Questo è un compito fondamentale prima che il modello di deep learning sia addestrato.
num_classi = 10
def load_cifar10_data(img_rows, img_cols):
# Caricare i set di formazione e convalida cifar10
(X_treno, Y_train), (X_valido, Y_valido) = cifar10.caricare dati()
# Ridimensiona le immagini dell'allenamento
X_treno = per esempio.Vettore([cv2.ridimensionare(img, (img_rows,img_cols)) per img in X_treno[:,:,:,:]])
X_valido = per esempio.Vettore([cv2.ridimensionare(img, (img_rows,img_cols)) per img in X_valido[:,:,:,:]])
# Trasforma i bersagli in un formato compatibile con Keras
Y_train = np_utils.to_categorical(Y_train, num_classi)
Y_valido = np_utils.to_categorical(Y_valido, num_classi)
X_treno = X_treno.come tipo('float32')
X_valido = X_valido.come tipo('float32')
# pre-elaborare i dati
X_treno = X_treno / 255.0
X_valido = X_valido / 255.0
Restituzione X_treno, Y_train, X_valido, Y_valido
X_treno, y_train, X_test, y_test = load_cifar10_data(224, 224)
Ora, definiremo la nostra architettura di deep learning. Definiremo rapidamente una funzione per farlo, Quello, quando ti vengono fornite le informazioni necessarie, restituisce l'intero livello iniziale.
def inception_module(X,
filtri_1x1,
filtri_3x3_riduci,
filtri_3x3,
filtri_5x5_riduci,
filtri_5x5,
filter_pool_proj,
nome=Nessuno):
conv_1x1 = Conv2D(filtri_1x1, (1, 1), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_3x3 = Conv2D(filtri_3x3_riduci, (1, 1), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_3x3 = Conv2D(filtri_3x3, (3, 3), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filtri_5x5_riduci, (1, 1), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_5x5 = Conv2D(filtri_5x5, (5, 5), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), passi avanti=(1, 1), imbottitura='stesso')(X)
pool_proj = Conv2D(filter_pool_proj, (1, 1), imbottitura='stesso', Attivazione='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
produzione = concatenare([conv_1x1, conv_3x3, conv_5x5, pool_proj], asse=3, nome=nome)
Restituzione produzione
Quindi creeremo l'architettura GoogLeNet, come indicato nel documento.
kernel_init = duro.inizializzatori.glorot_uniform()
bias_init = duro.inizializzatori.Costante(valore=0.2)
input_layer = Ingresso(forma=(224, 224, 3))
X = Conv2D(64, (7, 7), imbottitura='stesso', passi avanti=(2, 2), Attivazione='relu', nome='conv_1_7x7/2', kernel_initializer=kernel_init, bias_initializer=bias_init)(input_layer)
X = MaxPool2D((3, 3), imbottitura='stesso', passi avanti=(2, 2), nome='max_pool_1_3x3/2')(X)
X = Conv2D(64, (1, 1), imbottitura='stesso', passi avanti=(1, 1), Attivazione='relu', nome='conv_2a_3x3/1')(X)
X = Conv2D(192, (3, 3), imbottitura='stesso', passi avanti=(1, 1), Attivazione='relu', nome='conv_2b_3x3/1')(X)
X = MaxPool2D((3, 3), imbottitura='stesso', passi avanti=(2, 2), nome='max_pool_2_3x3/2')(X)
X = inception_module(X,
filtri_1x1=64,
filtri_3x3_riduci=96,
filtri_3x3=128,
filtri_5x5_riduci=16,
filtri_5x5=32,
filter_pool_proj=32,
nome='inizio_3a')
X = inception_module(X,
filtri_1x1=128,
filtri_3x3_riduci=128,
filtri_3x3=192,
filtri_5x5_riduci=32,
filtri_5x5=96,
filter_pool_proj=64,
nome='inizio_3b')
X = MaxPool2D((3, 3), imbottitura='stesso', passi avanti=(2, 2), nome='max_pool_3_3x3/2')(X)
X = inception_module(X,
filtri_1x1=192,
filtri_3x3_riduci=96,
filtri_3x3=208,
filtri_5x5_riduci=16,
filtri_5x5=48,
filter_pool_proj=64,
nome='inizio_4a')
x1 = Media Pooling2D((5, 5), passi avanti=3)(X)
x1 = Conv2D(128, (1, 1), imbottitura='stesso', Attivazione='relu')(x1)
x1 = Appiattire()(x1)
x1 = Denso(1024, Attivazione='relu')(x1)
x1 = Ritirarsi(0.7)(x1)
x1 = Denso(10, Attivazione='softmax', nome='output_ausiliario_1')(x1)
X = inception_module(X,
filtri_1x1=160,
filtri_3x3_riduci=112,
filtri_3x3=224,
filtri_5x5_riduci=24,
filtri_5x5=64,
filter_pool_proj=64,
nome='inizio_4b')
X = inception_module(X,
filtri_1x1=128,
filtri_3x3_riduci=128,
filtri_3x3=256,
filtri_5x5_riduci=24,
filtri_5x5=64,
filter_pool_proj=64,
nome='inizio_4c')
X = inception_module(X,
filtri_1x1=112,
filtri_3x3_riduci=144,
filtri_3x3=288,
filtri_5x5_riduci=32,
filtri_5x5=64,
filter_pool_proj=64,
nome='inizio_4d')
x2 = Media Pooling2D((5, 5), passi avanti=3)(X)
x2 = Conv2D(128, (1, 1), imbottitura='stesso', Attivazione='relu')(x2)
x2 = Appiattire()(x2)
x2 = Denso(1024, Attivazione='relu')(x2)
x2 = Ritirarsi(0.7)(x2)
x2 = Denso(10, Attivazione='softmax', nome='output_ausiliario_2')(x2)
X = inception_module(X,
filtri_1x1=256,
filtri_3x3_riduci=160,
filtri_3x3=320,
filtri_5x5_riduci=32,
filtri_5x5=128,
filter_pool_proj=128,
nome='inizio_4e')
X = MaxPool2D((3, 3), imbottitura='stesso', passi avanti=(2, 2), nome='max_pool_4_3x3/2')(X)
X = inception_module(X,
filtri_1x1=256,
filtri_3x3_riduci=160,
filtri_3x3=320,
filtri_5x5_riduci=32,
filtri_5x5=128,
filter_pool_proj=128,
nome='inizio_5a')
X = inception_module(X,
filtri_1x1=384,
filtri_3x3_riduci=192,
filtri_3x3=384,
filtri_5x5_riduci=48,
filtri_5x5=128,
filter_pool_proj=128,
nome='inizio_5b')
X = GlobalMediaPooling2D(nome='avg_pool_5_3x3/1')(X)
X = Ritirarsi(0.4)(X)
X = Denso(10, Attivazione='softmax', nome='produzione')(X)
modello = Modello(input_layer, [X, x1, x2], nome='inizio_v1')
Riassumiamo il nostro modello per verificare se il nostro lavoro finora è andato bene.
Il modello sembra buono, come puoi misurare dall'output sopra?. Possiamo aggiungere alcuni ritocchi finali prima di addestrare il nostro modello. Definiremo quanto segue:
- Función de pérdida para cada Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati....
- Peso assegnato a quel livello di output
- Funzione di ottimizzazione, che viene modificato per includere una diminuzione di peso dopo ogni 8 epoche.
- Metrica di valutazione
epoche = 25
valore_iniziale = 0.01
def decadimento(epoca, passi=100):
valore_iniziale = 0.01
gocciolare = 0.96
epochs_drop = 8
lrate = valore_iniziale * matematica.pow(gocciolare, matematica.pavimento((1+epoca)/epochs_drop))
Restituzione lrate
sgd = SGD(lr=valore_iniziale, quantità di moto=0.9, nesterov=falso)
lr_sc = Apprendimento RateScheduler(decadimento, verboso=1)
modello.compilare(perdita=['categorical_crossentropy', 'categorical_crossentropy', 'categorical_crossentropy'], perdita_pesi=[1, 0.3, 0.3], ottimizzatore=sgd, metrica=['precisione'])
Il nostro modello è ora pronto! Provalo per vedere come funziona.
storia = modello.in forma(X_treno, [y_train, y_train, y_train], validation_data=(X_test, [y_test, y_test, y_test]), epoche=epoche, dimensione del lotto=256, richiamate=[lr_sc])
Di seguito è riportato il risultato che ho ottenuto durante l'addestramento del modello:
Il nostro modello ha fornito una precisione impressionante del 80% + nel set di convalida, il che dimostra che vale davvero la pena provare questa architettura del modello.
Note finali
Questo è stato davvero un bell'articolo da scrivere e spero che tu lo abbia trovato ugualmente utile. Inception v1 è stato il punto focale di questo articolo, in cui ho spiegato il nocciolo di questo framework e dimostrato come implementarlo da zero in Keras.
Nei prossimi articoli, Mi concentrerò sui progressi nelle architetture Inception. Questi progressi sono stati dettagliati negli articoli successivi., vale a dire, Inizio v2, Inizio v3, eccetera. E se, sono intriganti come suggerisce il nome, Quindi restate sintonizzati!
Se hai qualche suggerimento / commento relativo all'articolo, postalo nella sezione commenti qui sotto.





