[*]
Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
tempo metereologico. Si tratta di dati così grandi e complessi che nessuno dei tradizionali strumenti di gestione dei dati li memorizzerà o li elaborerà in modo efficiente..
I Big Data sono un campo che si occupa delle modalità di indagine, analizzare ed estrarre costantemente informazioni da una grande quantità di dati strutturati o non strutturati.
Python ha diverse funzionalità integrate per supportare l'elaborazione dei dati, di piccole o grandi dimensioni. Queste funzioni supportano il trattamento di dati non strutturati e non convenzionali. Questo è il motivo per cui i data scientist e le aziende di Big Data preferiscono scegliere Python per l'elaborazione dei dati, in quanto è considerato uno dei requisiti più importanti nei Big Data.
Esistono anche altre tecnologie in grado di elaborare i Big Data in modo più efficiente di Python.. Figlio Hadoop e Spark.
Hadoop
Hadoop es la mejor solución para almacenar y procesar Big Data porque Hadoop almacena archivos enormes en forma de sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... (HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni..) Hadoop senza specificare alcuno schema.
È altamente scalabile, poiché è possibile aggiungere un numero qualsiasi di nodi per migliorare le prestazioni. E Hadoop, i dati sono altamente disponibili se si verifica anche un guasto hardware.
Scintilla – scintilla
Spark è anche una buona opzione per elaborare un gran numero di set di dati strutturati o non strutturati., poiché i dati sono archiviati in cluster. Spark concepirà di archiviare la quantità massima di dati in memoria in modo che si riversi sul disco. Memorizzerà una parte del set di dati in memoria e, così, i dati rimanenti sul disco.
La prima scelta del linguaggio di Toady Data Scientist è Python e sia Hadoop che Spark forniscono API Python che forniscono l'elaborazione dei Big Data e consentono anche un facile accesso alle piattaforme Big Data..
Fonte immagine: per me
Necessità di Python nei Big Data
1. Open Source:
Python è un linguaggio di programmazione open source sviluppato di seguito con una licenza Open Supply approvata da OSI., ciò che lo rende liberamente utilizzabile e distribuibile, anche per uso commerciale.
Python è un linguaggio interpretato generico e di alto livello.. Non è necessario compilare per l'esecuzione. Un programma noto come interprete esegue il codice Python praticamente su qualsiasi tipo di sistema.. Ciò significa che uno sviluppatore può modificare il codice e vedere rapidamente i risultati..
2. facile da imparare:
Python è molto facile da imparare proprio come la lingua inglese. La sua sintassi e il codice sono facili e leggibili anche dai principianti. Python ha molte applicazioni come lo sviluppo di applicazioni web, scienza dei dati, apprendimento automatico, eccetera.
Python ci consente di scrivere programmi con meno righe di codice rispetto alla maggior parte degli altri linguaggi di programmazione.. La popolarità di Python sta crescendo rapidamente grazie alla sua semplicità..
3. Biblioteche di elaborazione dati:
Quando si tratta di elaborazione dati, Python ha un
ricco set di strumenti con una vasta gamma di vantaggi. Com'è un linguaggio open source?, è facile da imparare e migliora continuamente. Python è costituito da un elenco di diverse librerie utili per l'elaborazione dati e integrate anche con altri linguaggi. (come Java), anche con le strutture esistenti. Python è più ricco di librerie che ne migliorano ulteriormente la funzionalità.
4. Supporto Hadoop e Spark:
Il framework Hadoop è scritto nel linguaggio Java.; tuttavia, I programmi Hadoop possono essere codificati in linguaggio Python o C ++. Possiamo scrivere programmi come MapReduce in linguaggio Python, sebbene non sia necessario tradurre il codice in file jar java.
Spark fornisce un'API Python chiamata PySpark rilasciata dalla community di Apache Spark per supportare Python con Spark.. Utilizzo di PySpark, si integrerà e lavorerà semplicemente con RDD anche all'interno del linguaggio di programmazione Python.
Spark viene fornito con una shell Python interattiva chiamata shell PySpark.. Questa shell PySpark è responsabile dell'associazione tra l'API Python e lo spark core e dell'inizializzazione del contesto spark. PySpark può anche essere avviato direttamente dalla riga di comando dando alcune istruzioni per un uso interattivo.
5. velocità ed efficienza:
Python è un linguaggio di programmazione di alto livello potente ed efficiente.. Che si tratti di sviluppare un'app o di lavorare per risolvere qualsiasi problema aziendale attraverso la scienza dei dati, Python ti ha coperto tutti questi limiti. Python funziona sempre bene per ottimizzare la produttività e l'efficienza degli sviluppatori.
Possiamo creare rapidamente un programma in grado di risolvere un problema aziendale e soddisfare un'esigenza pratica. tuttavia,
Le soluzioni potrebbero non raggiungere le prestazioni ottimizzate di Python mentre vengono sviluppate rapidamente.
6. Scalabile e flessibile:
Python è il linguaggio più popolare per ML / AI grazie alla tua comodità. La flessibilità di Python consente inoltre di strumentare il codice Python per formare la scalabilità ML. / IA possibilmente senza richiedere ulteriore esperienza di sistema distribuito e molte modifiche invasive del codice. Perciò, Utenti ML / L'IA ottiene i vantaggi della scalabilità in tutto il cluster con il minimo sforzo.
Componenti Hadoop:
Ci sono principalmente due componenti di Hadoop:
- HDFS (File system distribuito Hadoop)
- Mappa piccola
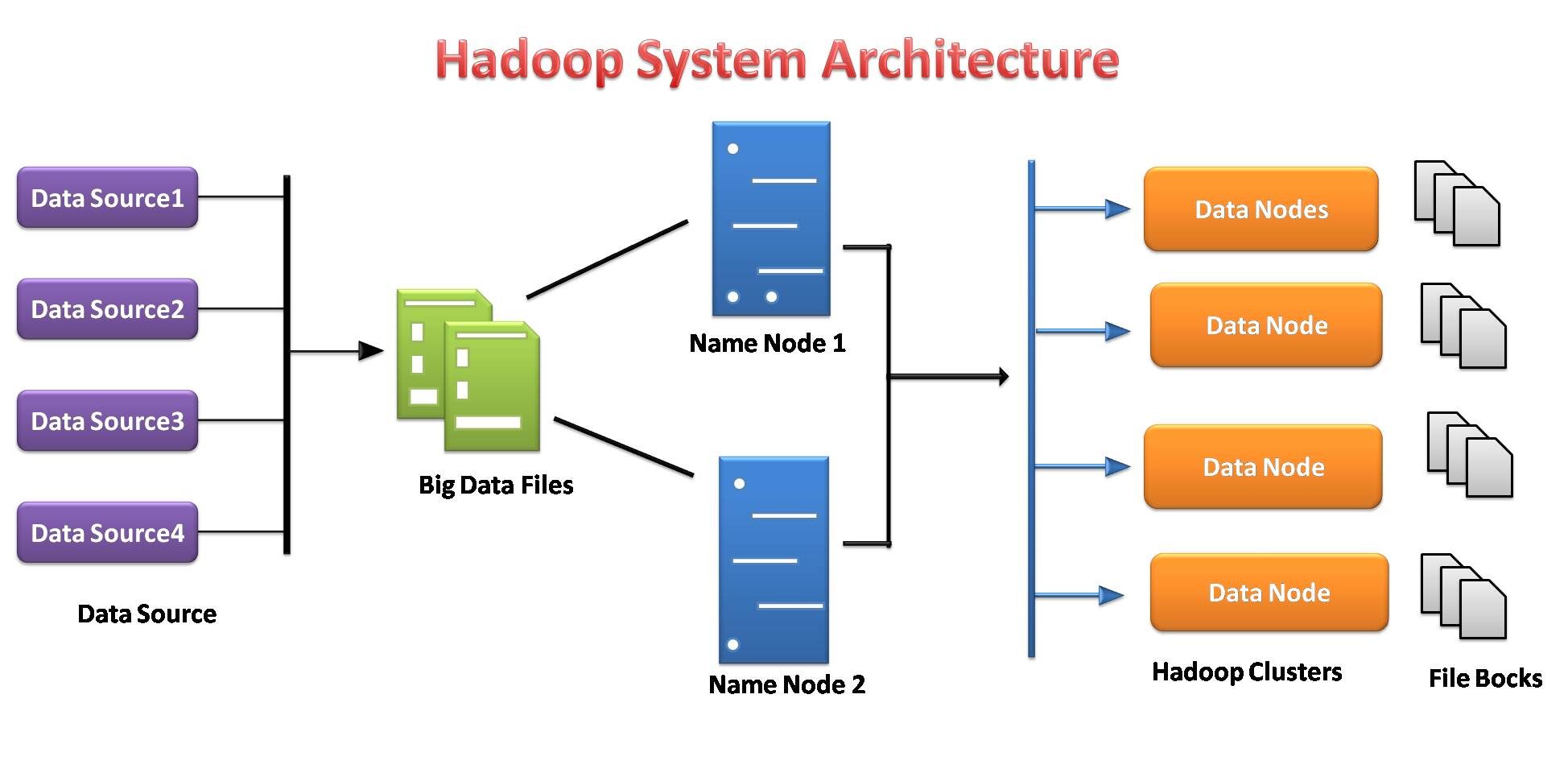
File system distribuito Hadoop
Il file system Hadoop è stato sviluppato sulla base del modello del file system distribuito.. Funziona con hardware di base. A differenza dei diversi sistemi distribuiti, HDFS è estremamente tollerante ai guasti e progettato su hardware economico.
HDFS può archiviare una grande quantità di dati e fornisce anche un accesso più semplice a tali dati.. Per memorizzare una così grande quantità di dati, i file sono archiviati su più sistemi. Questi file vengono archiviati in modo ridondante per salvare il sistema da possibili perdite di dati in caso di guasto.. Cosa c'è di più, HDFS offre applicazioni per il multiprocessing.
- Es responsable de almacenar datos en un grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... como almacenamiento y procesamiento distribuidos.
- Los servidores de datos del nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... de nombre y del nodo de conocimiento facilitan a los usuarios comprobar simplemente el estado del clúster.
- Ogni blocco viene replicato più volte per impostazione predefinita 3 volte. Le repliche sono archiviate su nodi completamente diversi.
- Hadoop Streaming funge da ponte tra il tuo codice Python e, così, l'HDFS basato su Java, y le permite acceder sin problemas a los clústeres de Hadoop y ejecutar tareas de Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data.....
- HDFS fornisce l'autenticazione e le autorizzazioni dei file.
Fonte immagine: per me
Installazione di Hadoop su Google Colab
Hadoop è un framework di elaborazione dati basato sulla programmazione Java. Installiamo le impostazioni di Hadoop passo dopo passo in Google Colab. Ci sono due modi, il primo è che dobbiamo installare java sulle nostre macchine e il secondo è che installiamo java in google colab, quindi non è necessario installare java sulle nostre macchine. Come utilizziamo Google colab, abbiamo scelto il secondo modo per installare Hadoop:
# Installare java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#create java home variable
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/contenuto/spark-3.0.0-bin-hadoop3.2"
passo 1: installare Hadoop
#scaricare hadoop !wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
#useremo il comando tar con il flag -x per estrarre, -z per decomprimere, #-v per output dettagliato, e -f per specificare che stiamo estraendo da un file !tar -xzvf hadoop-3.3.0.tar.gz
#copiando il file hadoop in user/local !cp -r hadoop-3.3.0/ /usr/local/
passo 2: configurar la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de inicio de Java
#trovare il percorso Java predefinito !readlink -f /usr/bin/java | sed "S:bin/java::"
passo 3: Esegui Hadoop
#Esecuzione di Hadoop !/usr/local/hadoop-3.3.0/bin/hadoop
!mkdir ~/input
!cp /usr/local/hadoop-3.3.0/etc/hadoop/*.xml ~/input
!/usr/local/hadoop-3.3.0/bin/hadoop jar /usr/local/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep ~/input ~/grep_example ' permesso[.]*'
Ora, Google Colab è pronto per implementare HDFS.
Mappa piccola
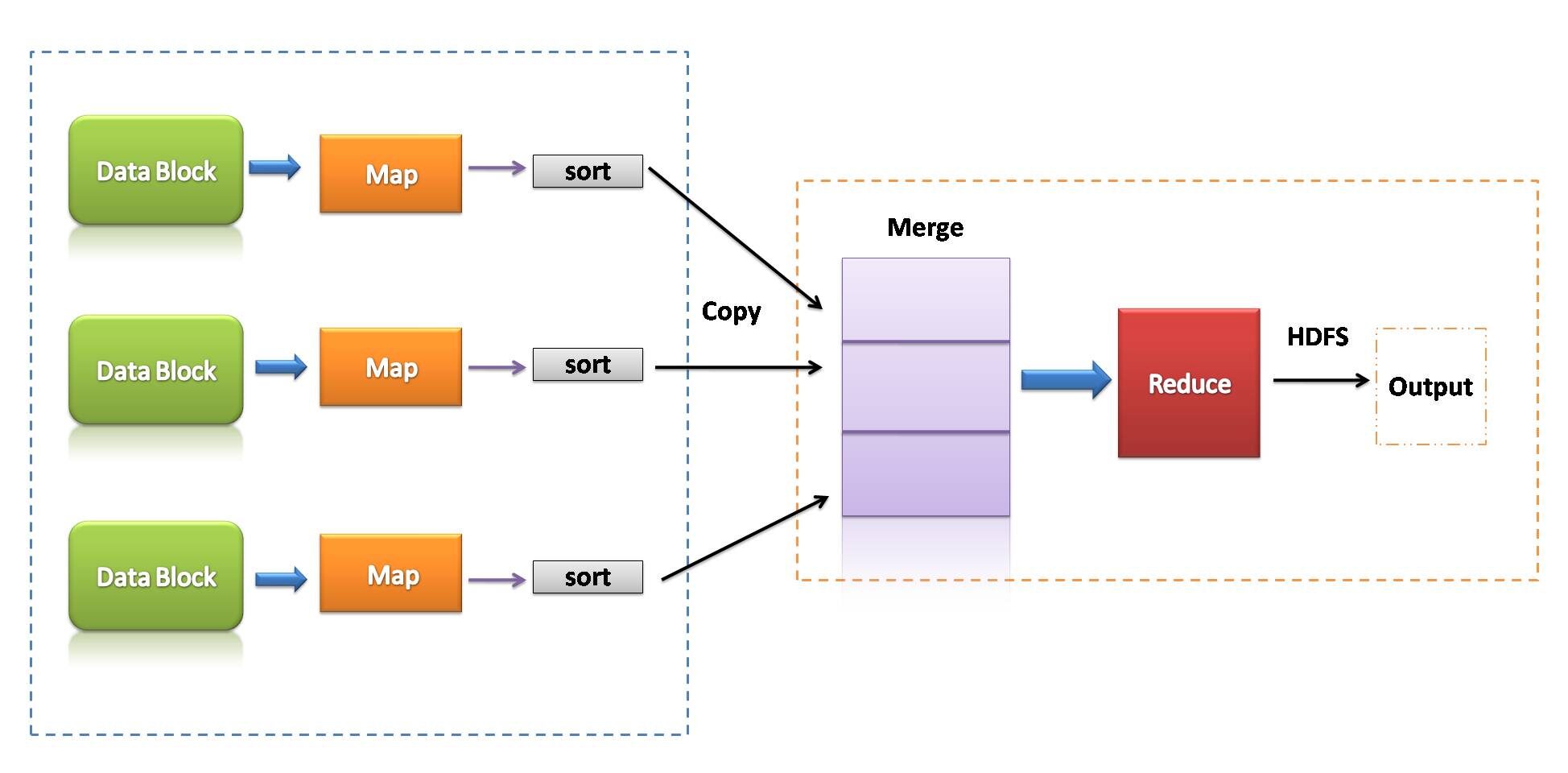
MapReduce è un modello di programmazione associato all'implementazione dell'elaborazione e alla generazione di grandi set di dati con l'aiuto di regole algoritmiche distribuite in parallelo in un cluster.
Un programma MapReduce consiste in una procedura di mappatura, che esegue il filtraggio e l'ordinamento, e una tecnica di riduzione, che esegue un'operazione sullo schema.
Fonte immagine: per me
- MapReduce potrebbe essere un framework di elaborazione dati per elaborare i dati nel cluster.
- Due fasi consecutive: mappare e ridurre.
- Ciascuna attività della mappa opera su dati separati.
- dopo la mappa, il riduttore lavora con i dati generati dal mapper sui nodi dati distribuiti.
- MapReduce usato E / Disco S per eseguire operazioni sui dati.
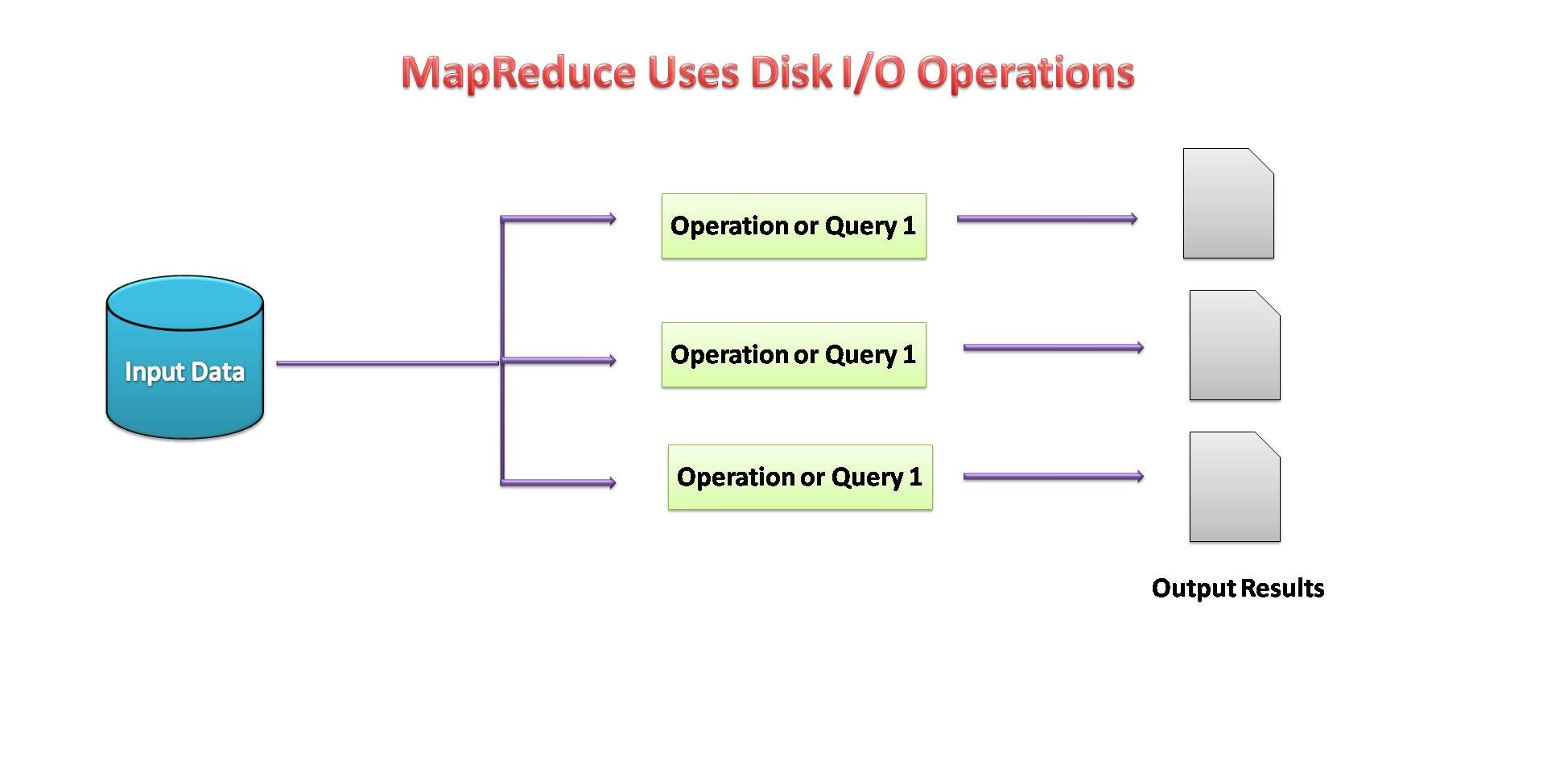
Fonte immagine: per me
Apache SparkApache Spark è un motore di elaborazione dati open source che consente l'analisi di grandi volumi di informazioni in modo rapido ed efficiente. Il suo design si basa sulla memoria, che ottimizza le prestazioni rispetto ad altri strumenti di elaborazione batch. Spark è ampiamente utilizzato nelle applicazioni di big data, Apprendimento automatico e analisi in tempo reale, grazie alla sua facilità d'uso e...
Apache Spark è un motore di analisi dei dati open source per l'elaborazione su larga scala di dati strutturati o non strutturati.. Per lavorare con Python, comprese le funzionalità Spark, la comunità di Apache Spark aveva rilasciato uno strumento chiamato PySpark.
L'API Spark Python (PySpark) rivela il modello di programmazione da Spark a Python. Utilizzo di PySpark, possiamo lavorare con RDD nel linguaggio di programmazione Python. È attribuibile a una libreria nota come Py4j che può raggiungere questo obiettivo.
Fonte immagine: Xanon Stack
Set di dati distribuiti resilienti (RDD)
Concetti relativi a set di dati distribuiti resilienti (RDD) figlio:
- L'obiettivo principale della programmazione Spark è RDD.
- Spark è estremamente tollerante ai guasti. Dispone di raccolte di oggetti distribuiti in un cluster che può operare in parallelo.
- Al usar Spark, può recuperare automaticamente da un guasto alla macchina.
- Possiamo creare un RDD copiando gli elementi di una raccolta esistente o facendo riferimento a un set di dati archiviato esternamente.
- Esistono due tipi di operazioni eseguite dagli RDD: trasformazioni e azioni.
- L'operazione di trasformazione usa un set di dati esistente per crearne uno nuovo. Esempio: carta geografica, filtro, aderire.
- Azioni eseguite sul set di dati e restituiscono il valore al programma del controller. Esempio: ridurre, raccontare, raccogliere, Salva.
Se la disponibilità di memoria sembra insufficiente, i dati vengono scritti su disco come MapReduce.
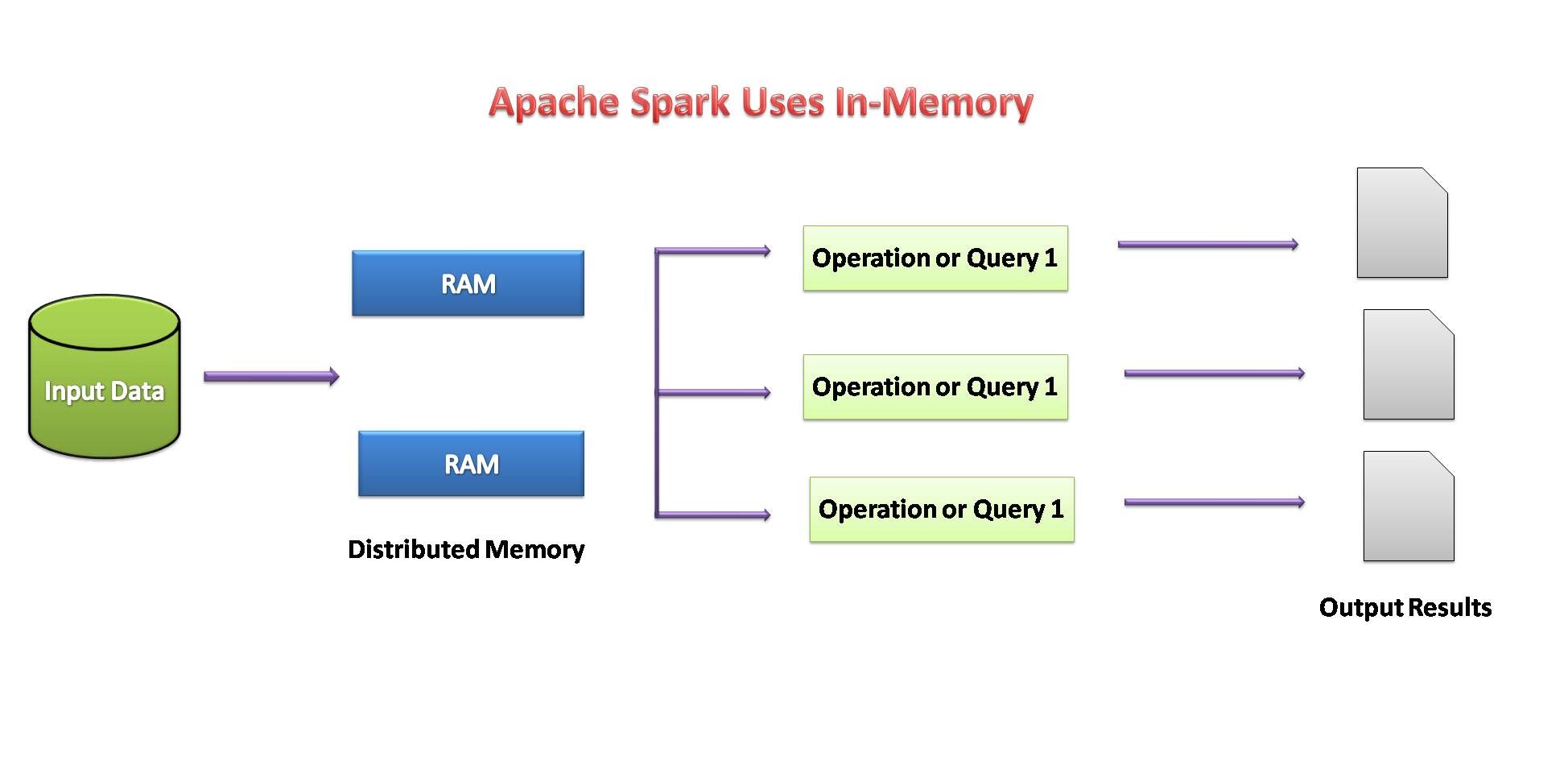
Fonte immagine: per me
Installazione di Spark e Google colab:
Spark è un efficiente framework per l'elaborazione dei dati. podemos instalarlo fácilmente en el colab de Google.
# Installare java !apt-get install openjdk-8-jdk-headless -qq > /dev/null
#Installa spark (Modificare il numero di versione, se necessario) !wget -q https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
#Decomprimere il file spark nella cartella corrente !tar xf spark-3.0.0-bin-hadoop3.2.tgz
#Impostare la cartella spark sull'ambiente del percorso di sistema. importare il sistema operativo os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/contenuto/spark-3.0.0-bin-hadoop3.2"
#Installa findspark usando pip !pip install -q findspark
#Spark per Python (pyspark) !pip install pyspark
#importing pyspark
import pyspark
#importing sparksessio
from pyspark.sql import SparkSession
#creating a sparksession object and providing appName
spark=SparkSession.builder.appName("Locale[*]").getOrCreate()
#printing the version of spark
print("Versione Apache Spark: ", spark.version)

Ora, Google Colab está listo para implementar Spark en Python.
Ventajas de Apache Spark:
- Spark es de 10 un 100 veces más rápido que Hadoop MapReduce cuando se habla de procesamiento de datos.
- Tiene sImplementa un framework di elaborazione dati e API interattive per Python per velocizzare lo sviluppo delle applicazioni.
- Cosa c'è di più, è più efficiente poiché ha più strumenti per operazioni analitiche complesse.
- Può essere facilmente integrato con l'infrastruttura Hadoop esistente.
conclusione:
In questo blog, studiamo come Python possa diventare anche uno strumento valido ed efficiente per l'elaborazione di Big Data. Possiamo integrare tutti gli strumenti Big Data con Python, che rende l'elaborazione dei dati più facile e veloce. Python è diventato un'opzione adatta non solo per la scienza dei dati, ma anche per l'elaborazione di Big Data..
Grazie per aver letto. Per favore fatemi sapere se ci sono commenti o feedback.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





