Panoramica
- I database relazionali sono onnipresenti, ma cosa succede quando hai bisogno di ridimensionare la tua infrastruttura??
- Discuteremo il ruolo svolto da Spark SQL in questa situazione e capiremo perché è uno strumento così utile per l'apprendimento.
- Questo tutorial mostra anche come funziona Spark SQL utilizzando un case study Python
introduzione
Quasi tutte le organizzazioni utilizzano database relazionali per varie attività, dalla gestione e monitoraggio di una grande quantità di informazioni all'organizzazione e all'elaborazione delle transazioni. È uno dei primi concetti insegnati a noi nella scuola di programmazione.
E siamo grati per questo perché questo è un ingranaggio cruciale nel set di abilità di uno scienziato dei dati!! Non puoi farcela senza sapere come funzionano i database. È un aspetto fondamentale di qualsiasi apprendimento automatico brutta copia.
Structured Query Language (SQL) è facilmente la lingua più popolare quando si tratta di database. A differenza di altri linguaggi di programmazione, è facile da imparare e ci aiuta a iniziare con il nostro processo di estrazione dei dati. Per la maggior parte dei lavori di data science, La competenza in SQL è più alta della maggior parte degli altri linguaggi di programmazione.

Ma c'è una grande sfida con SQL: avrà difficoltà a farlo funzionare quando si ha a che fare con enormi set di dati. È qui che Spark SQL prende un posto in prima fila e colma il divario.. Parlerò di più di questo nella prossima sezione..
Questo tutorial pratico ti introdurrà al mondo di Spark SQL, Come funziona, quali sono le diverse funzionalità che offre e come puoi implementarlo usando python. Parleremo anche di un concetto importante che incontrerete spesso nelle interviste.: l'ottimizzatore del catalizzatore.
Cominciamo!
Nota: Se sei completamente nuovo nel mondo SQL, Consiglio vivamente il seguente corso:
Sommario
- Sfide con il ridimensionamento del database relazionale
- Panoramica di Spark SQL
- Funzionalità di Spark SQL
- In che modo Spark SQL esegue una query??
- Che cos'è un catalizzatore ottimizzatore??
- Esecuzione di comandi SQL con Spark
- Utilizzo di Apache Spark su larga scala
Sfide con il ridimensionamento del database relazionale
La domanda è perché dovrei imparare Spark SQL?? Ne ho parlato brevemente prima, ma diamo un'occhiata un po' più in dettaglio ora.
Database relazionali per un grande progetto (apprendimento automatico) contengono centinaia o forse migliaia di tabelle e la maggior parte delle funzionalità in una tabella viene mappata ad altre funzionalità in altre tabelle. Questi database sono progettati per funzionare solo su una singola macchina al fine di mantenere le regole dei mapping delle tabelle ed evitare i problemi del calcolo distribuito..
Questo spesso diventa un problema per le organizzazioni quando vogliono scalare con questo design.. Richiederebbe hardware più complesso e costoso con una capacità di elaborazione e archiviazione significativamente maggiore. Come puoi immaginare, L'aggiornamento da hardware più semplice a hardware più complesso può essere una grande sfida.
Un'organizzazione potrebbe dover mettere offline il proprio sito Web per un po' di tempo per apportare le modifiche necessarie. Durante questo periodo, perderebbero affari con nuovi clienti che avrebbero potuto potenzialmente acquisire.
Cosa c'è di più, all'aumentare del volume dei dati, le organizzazioni faticano a gestire questa enorme quantità di dati utilizzando i database relazionali tradizionali. È qui che entra in gioco Spark SQL..
Panoramica di Spark SQL
““
~
I framework Hadoop e MapReduce esistono da molto tempo nell'analisi dei big data. Ma questi frame richiedono molte operazioni di lettura e scrittura su un disco rigido, il che li rende molto costosi in termini di tempo e velocità.
Apache Spark è il framework di elaborazione dati più efficiente oggi nelle aziende. È vero che il costo di Spark è elevato poiché richiede molta RAM per il calcolo in memoria, ma è ancora uno dei preferiti dai data scientist e dai big data engineer.
Nell'ecosistema Spark, abbiamo i seguenti componenti:
- MLlib: Questa è la libreria di apprendimento automatico scalabile di Spark che fornisce algoritmi di alta qualità per la regressione, raggruppamento, classificazione, eccetera. Puoi iniziare a creare pipeline di machine learning utilizzando MLlib di Spark utilizzando questo articolo: Come costruire pipeline di machine learning usando PySpark?
- Spark in streaming: Stiamo generando dati a un ritmo e una scala senza precedenti in questo momento. Come possiamo garantire che la nostra pipeline di machine learning continui a produrre risultati non appena i dati vengono generati e raccolti?? Impara a utilizzare un modello di apprendimento automatico per fare previsioni sulla trasmissione dei dati con PySpark?
- GraficoX: È un'API Spark per la grafica, un motore grafico di rete che supporta il calcolo grafico parallelo.
- Spark SQL: Questo è un framework distribuito per l'elaborazione dei dati strutturati fornito da Spark
Sappiamo che i database relazionali memorizzano anche le relazioni tra le diverse variabili e le diverse tabelle e sono progettati in modo tale da poter gestire query complesse..
Spark SQL è una straordinaria combinazione di elaborazione relazionale e programmazione Spark funzionale.. Fornisce supporto per più origini dati e rende possibili le query SQL, risultando in uno strumento molto potente per analizzare i dati strutturati su larga scala.
Funzionalità di Spark SQL
Spark SQL ha un sacco di fantastiche funzionalità, ma volevo evidenziare alcuni tasti che utilizzerai molto nella tua funzione:
- Query sulla struttura dei dati all'interno dei programmi Spark: Molti di voi potrebbero già avere familiarità con SQL. Perciò, non è necessario imparare a definire una funzione complessa in Python o Scala per usare Spark. Puoi utilizzare esattamente la stessa query per ottenere i risultati dei tuoi set di dati più grandi!!
- Compatibile con Hive: Nessun SQL da solo, ma puoi anche eseguire le stesse query Hive con Spark SQL Engine. Consente la piena compatibilità con le attuali query Hive.
- Un modo per accedere ai dati: Nei tipici progetti a livello aziendale, non ha una fonte di dati comune. Anziché, deve gestire vari tipi di file e database. Spark SQL supporta quasi tutti i tipi di file e offre un modo comune per accedere a una varietà di origini dati, nel ruolo di Hive, Euro, Parquet, JSON e JDBC
- Prestazioni e scalabilità: Quando si lavora con set di dati di grandi dimensioni, ci sono possibilità che si verifichino errori tra il momento in cui viene eseguita la query. Spark SQL supporta la piena tolleranza agli errori mid-query, così possiamo lavorare anche con mille nodi contemporaneamente
- Funzioni definite dall'utente: UDF è una funzionalità Spark SQL che definisce nuove funzioni basate su colonne che estendono il vocabolario Spark SQL per la trasformazione dei set di dati
In che modo Spark SQL esegue una query??
Come funziona Spark SQL?, essenzialmente? Comprendiamo il processo in questa sezione.
- Analisi: Primo, quando consulti qualcosa, Spark SQL trova la relazione da calcolare. Viene calcolato utilizzando un albero di sintassi astratto (AST) dove controlli il corretto utilizzo degli elementi utilizzati per definire la query e quindi crei un piano logico per eseguire la query.

- Ottimizzazione logica: In questo prossimo passo, l'ottimizzazione basata su regole viene applicata al piano logico. Usa tecniche come:
- Filtra i dati in anticipo se la query contiene a dove clausola
- Usa l'indice disponibile sulle tabelle, in quanto può migliorare le prestazioni, e
- Anche assicurandosi che le diverse fonti di dati siano riunite nell'ordine più efficiente.
- Pianificazione fisica: In questo passaggio, uno o più piani fisici sono formati utilizzando il piano logico. Spark SQL seleziona quindi il piano che sarà in grado di eseguire la query nel modo più efficiente, vale a dire, utilizzando meno risorse di calcolo.
- Codice GENERAZIONE: Nella fase finale, Spark SQL genera codice. Si tratta di generare un bytecode Java da eseguire su ogni macchina. Catalyst utilizza una funzione speciale del linguaggio Scala chiamata “quasi citazioni” per facilitare la generazione del codice.

Che cos'è un catalizzatore ottimizzatore??
Ottimizzazione significa aggiornare il sistema o il flusso di lavoro esistente in modo che funzioni in modo più efficiente, utilizzando meno risorse. Un ottimizzatore noto come Ottimizzatore catalizzatore è implementato in Spark SQL che supporta tecniche di ottimizzazione basate su regole e costi.
Nell'ottimizzazione basata su regole, abbiamo definito una serie di regole che determineranno come verrà eseguita la query. Riscriverà la query esistente in un modo migliore per migliorare le prestazioni.
Ad esempio, diciamo che c'è un indice disponibile sul tavolo. Dopo, l'indice verrà utilizzato per l'esecuzione della query secondo le regole e i filtri DOVE verrà applicato prima sui dati iniziali se possibile (invece di applicarli per ultimi).
Cosa c'è di più, ci sono alcuni casi in cui l'uso di un indice rallenta una query. Sappiamo che non è sempre possibile che un insieme di regole definite prenda sempre grandi decisioni, verità?
Ecco il problema: l'ottimizzazione basata su regole non tiene conto della distribuzione dei dati. È qui che ci rivolgiamo a un ottimizzatore basato sui costi. Usa le statistiche sul tavolo, i tuoi indici e la distribuzione dei dati per prendere decisioni migliori.
Esecuzione di comandi SQL con Spark
È ora di programmare!
Ho creato un set di dati casuali di 25 milioni di righe. Puoi scaricare il set di dati completo qui. Abbiamo un file di testo con valori separati da virgole. Quindi, primo, importeremo le librerie richieste, leggeremo il set di dati e vedremo come Spark partizionirà i dati in partizioni:
![]()
Qui,
- Il primo valore in ogni riga è l'età della persona (che deve essere un numero intero)
- Il secondo valore è il gruppo sanguigno della persona (che deve essere una stringa)
- Il terzo e il quarto valore sono città e genere (entrambi sono catene), e
- Il valore finale è un id (che è di tipo intero)
Mapperemo i dati in ogni riga su un tipo di dati e un nome specifici utilizzando le righe Spark:
![]()

Prossimo, creeremo un frame di dati usando le righe analizzate. Il nostro obiettivo è trovare i conteggi dei valori della variabile di genere utilizzando un semplice raggruppare per funzione nel frame di dati:

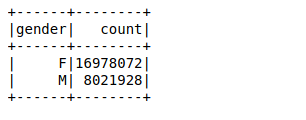

Ci sono voluti circa 26 ms per calcolare il conteggio dei valori di 25 milioni di righe utilizzando una funzione groupby nel frame di dati. Puoi calcolare il tempo usando %%tempo metereologico nella cella privata del suo taccuino Jupyter.
Ora, eseguiremo la stessa query utilizzando Spark SQL e vedremo se migliora le prestazioni o meno.
Primo, è necessario registrare il frame di dati come tabella temporanea utilizzando la funzione registerTempTable. Questo crea una tabella in memoria che ha come ambito solo il cluster in cui è stata creata. La durata di questa tabella temporanea è limitata a una sola sessione. Viene memorizzato utilizzando Formato colonna in memoria di Hive che è altamente ottimizzato per i dati relazionali.
Cosa c'è di più, Non hai nemmeno bisogno di scrivere funzioni complesse per ottenere risultati se hai dimestichezza con SQL!! Qui, devi solo passare la stessa query SQL per ottenere i risultati desiderati su dati più grandi:
![]()
Ci è voluto solo un giro 18 ms calcolare i conteggi dei valori. Questo è molto più veloce anche di un frame di dati Spark.
Prossimo, eseguiremo un'altra query SQL per calcolare l'età media in una città:
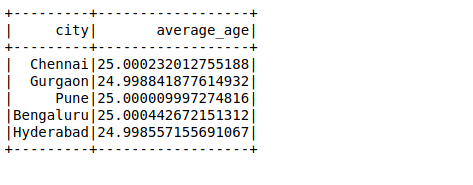
Caso d'uso di Apache Spark su larga scala
Sappiamo che Facebook ha più di 2000 milioni di utenti attivi mensili e con più dati, affrontare sfide altrettanto complesse. Per una singola query, bisogno di analizzare decine di terabyte di dati in una singola query. Facebook ritiene che Spark fosse maturato al punto da poterlo confrontare con Hive per una serie di casi d'uso di elaborazione batch..
Permettetemi di illustrare questo utilizzando un caso di studio di Facebook stesso.. Uno dei suoi compiti era quello di preparare le caratteristiche per la classifica delle entità che Facebook utilizza nei suoi vari servizi online. In precedenza, utilizzato l'infrastruttura basata su Hive, che richiedeva molte risorse ed era difficile da mantenere, poiché il gasdotto è stato diviso in centinaia di lavori Hive. Quindi hanno creato una pipeline più veloce e più gestibile con Spark. Puoi leggere il suo tour completo qui.
Hanno confrontato i risultati di Spark vs Hive Pipeline. Ecco una tabella di confronto in termini di latenza (tempo trascorso da un'estremità all'altra del lavoro) che mostra chiaramente che Spark è molto più veloce di Hive.

Note finali
Abbiamo trattato l'idea alla base di Spark SQL in questo articolo e abbiamo anche imparato come utilizzarla a nostro vantaggio.. Abbiamo anche preso un grande set di dati e applicato il nostro apprendimento in Python.
Spark SQL è relativamente sconosciuto a molti aspiranti alla scienza dei dati, ma sarà utile nel tuo ruolo nel settore o anche nelle interviste. È un'aggiunta piuttosto importante agli occhi del responsabile delle assunzioni..
Condividi i tuoi pensieri e suggerimenti nella sezione commenti qui sotto..





