introduzione
Amo lavorare con C ++, anche dopo aver scoperto il linguaggio di programmazione Python per l'apprendimento automatico. C ++ è stato il primo linguaggio di programmazione che ho imparato e sono felice di usarlo nello spazio di apprendimento automatico.
Ho scritto sulla creazione di modelli di apprendimento automatico nel mio post precedente e la community ha adorato l'idea. Ho ricevuto una risposta travolgente e una domanda si è distinta per me (di più persone): Ci sono librerie C? ++ per l'apprendimento automatico?
È una domanda giusta. Linguaggi come Python e R hanno un gran numero di pacchetti e librerie per adattarsi a diverse attività di apprendimento automatico.. Quindi, C ++ avete qualche offerta di questo tipo??

sì, lo fa?! Evidenzierò due di queste librerie C ++ in questo post, e li vedremo anche in azione (con codice). Se sei nuovo in C ++ per l'apprendimento automatico, Ti consiglio di nuovo di leggere il primo post.
Sommario
- Perché dovremmo usare le librerie di machine learning?
- Librerie di Machine Learning in C ++
- Biblioteca SHARK
- Libreria MLPACK
Perché dovremmo usare le librerie di machine learning?
Questa è una domanda che molti nuovi arrivati avranno.. Qual è la rilevanza delle biblioteche nell'apprendimento automatico?? Lascia che te lo spieghi in questa sezione.
Diciamo che professionisti stagionati e veterani del settore hanno provato duramente e hanno trovato una soluzione a un ostacolo.. Preferiresti usarlo o preferiresti passare ore a cercare di ricreare la stessa cosa da zero?? Generalmente, non ha molto senso optare per quest'ultimo metodo, soprattutto quando si lavora o si studia entro le scadenze prefissate.
La cosa migliore della nostra community di machine learning è che ci sono già molte soluzioni sotto forma di librerie e pacchetti. Qualcun altro, dagli esperti agli appassionati, hai già fatto il duro lavoro e hai messo insieme la risposta ben confezionata in una libreria.
Queste librerie di machine learning sono efficienti e ottimizzate, e accuratamente testato per molteplici casi d'uso. La fiducia in queste librerie è ciò che guida il nostro apprendimento e rende la scrittura del codice, o in Do ++ o Pitone, essere molto più semplice e intuitivo.
Librerie di Machine Learning in C ++
In questa sezione, esamineremo le due librerie di machine learning più popolari in C +:
- Biblioteca SHARK
- Libreria MLPACK
Diamo un'occhiata a ciascuno singolarmente e vediamo come funziona il codice C ++.
1) Biblioteca SHARK C ++
Shark es una biblioteca modular rápida y tiene un soporte abrumador para algoritmos de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in..., come regressione lineare, reti neurali, raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.., k-calzini, eccetera. Include anche le funzionalità di algebra lineare e ottimizzazione numerica.. Queste sono funzioni o aree matematiche chiave che sono molto importanti quando si eseguono attività di apprendimento automatico.
Vedremo prima come installare Shark e configurare un ambiente. Dopo, implementeremo la regressione lineare con Shark.
Installa Shark e configura l'ambiente (lo farò per linux)
- Shark si fida di Boost e cmake. fortunatamente, tutte le dipendenze possono essere installate con il seguente comando:
sudo apt-get install cmake cmake-curses-gui libatlas-base-dev libboost-all-dev
- Per installare Shark, esegui i seguenti comandi riga per riga nel tuo terminale:
- clone de git https://github.com/Shark-ML/Shark.git (puoi anche scaricare il file zip ed estrarlo)
- cd squalo
- build mkdir
- cd build
- cmake ..
- fare
Se non l'hai mai visto prima, non è un ostacolo. È abbastanza semplice e ci sono molte informazioni online se ti trovi nei guai. Per Windows e altri sistemi operativi, puoi fare una rapida ricerca su google su come installare Shark. Ecco il sito di riferimento Guida all'installazione dello squalo.
Compila programmi con Shark
Implementazione della regressione lineare con Shark
Il mio primo post di questa serie aveva un'introduzione alla regressione lineare. Userò la stessa idea in questo post, ma questa volta usando la libreria Shark C ++.
Fase di inizializzazione
Inizieremo includendo le librerie e le funzioni di intestazione per la regressione lineare:
Poi viene il set di dati. Ho creato due file CSV. Il file input.csv contiene i valori x e il file label.csv contiene i valori y. Di seguito un'istantanea dei dati:
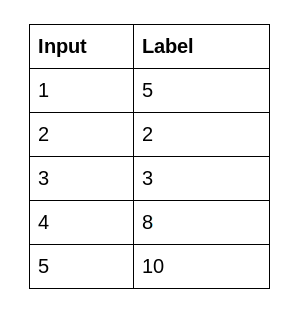
Puoi trovare entrambi i file qui: Apprendimento automatico con C ++. Primo, creeremo contenitori di dati per salvare i valori dei file CSV:
Prossimo, dobbiamo importarli. Shark è dotato di una bella funzione di importazione CSV, e specifichiamo il contenitore di dati che vogliamo inizializzare, e anche la posizione del file di percorso CSV:
Dopo, dobbiamo istanziare un tipo di set di dati di regressione. Ora, questo è solo un oggetto generale per la regressione, e quello che faremo nel costruttore è passare i nostri input e anche le nostre etichette per i dati.
Prossimo, dobbiamo addestrare il modello di regressione lineare. Come lo facciamo? Dobbiamo istanziare un trainer e stabilire un modello lineare:
Etapa de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....
Poi arriva il passaggio chiave in cui formiamo veramente il modello. Qui, l'allenatore ha una funzione membro chiamata treno. Quindi, esta función entrena este modelo y encuentra los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para el modelo, cosa vogliamo fare esattamente.
Fase di previsione
In conclusione, generiamo i parametri del modello:
I modelli lineari hanno una funzione membro chiamata rimediare che genera l'intersezione della linea di miglior adattamento. Prossimo, generiamo una matrice invece di un moltiplicatore. Questo perché il modello può essere generalizzato (non solo lineare, potrebbe essere un polinomio).
Calcoliamo la linea di miglior adattamento minimizzando i minimi quadrati, In altre parole, minimizzazione della perdita al quadrato.
Quindi, fortunatamente, il modello ci consente di generare quell'informazione. La libreria Shark è molto utile per dare un'indicazione di quanto bene i modelli si adattano:
Primo, dobbiamo inizializzare un oggetto di perdita quadratica, e poi abbiamo bisogno di istanziare un contenitore di dati. Dopo, la previsione è calcolata in base agli input al sistema, e poi tutto quello che faremo è fare la perdita, che viene calcolato passando le etichette e anche il valore di previsione.
In conclusione, dobbiamo compilare. Nel terminale, digita il seguente comando (assicurati che la directory sia configurata correttamente):
g++ -o lr linear_regression.cpp -std=c++11 -lboost_seriaization -lshark -lcblas
Una volta compilato, avrebbe creato un lr oggetto. Ora basta eseguire il programma. L'output che otteniamo è:
B : [1](-0,749091)
UN :[1,1]((2.00731))
Perduto: 7.83109
Il valore di b è un po' lontano da 0, ma questo è dovuto al rumore sulle etichette. Il valore del moltiplicatore è vicino a 2, che è abbastanza equivalente ai dati. Ed è così che puoi usare la libreria Shark in C! ++ costruire un modello di regressione lineare!
2) Libreria MLPACK C ++
mlpack è una libreria di machine learning veloce e flessibile scritta in C ++. Il suo obiettivo è fornire implementazioni veloci ed estensibili di algoritmi di apprendimento automatico all'avanguardia.. mlpack fornisce questi algoritmi come semplici programmi da riga di comando, ha lasciato il Python, Collegamenti Julia e classi C ++ che possono quindi essere integrati in soluzioni di apprendimento automatico su larga scala.
Vedremo prima come installare mlpack e l'ambiente di configurazione. Quindi implementeremo l'algoritmo k-means usando mlpack.
Installa mlpack e l'ambiente di configurazione (lo farò per linux)
mlpack dipende dalle seguenti librerie che devono essere installate sul sistema e hanno le intestazioni presenti:
- Armadillo> = 8.400.0 (con il supporto di LAPACK)
- Aumento (math_c99, opzioni_programma, serializzazione, unit_test_framework, mucchio, spirito)> = 1.49
- ingrandisci> = 2.10.0
Su Ubuntu e Debian, puoi ottenere tutte queste dipendenze tramite in forma:
sudo apt-get install libboost-math-dev libboost-program-options-dev libboost-test-dev libboost-serialization-dev binutils-dev python-pandas python-numpy cython python-setuptools
Ora che tutte le dipendenze sono installate sul tuo sistema, puoi eseguire direttamente i seguenti comandi per compilare e installare mlpack:
- wget
- tar -xvzpf mlpack-3.2.2.tar.gz
- mkdir mlpack-3.2.2 / compilare && cd mlpack-3.2.2 / costruire
- cmake ../
- make -j4 # Il -j è il numero di core che vuoi usare per una build
- sudo make install
Su molti sistemi Linux, mlpack verrà installato di default per / usr / Locale / libi y es factible que deba configurar la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de entorno LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=/usr/local/lib
Le istruzioni di cui sopra sono il modo più semplice per ottenere, compila e installa mlpack. Se la tua distribuzione Linux supporta i binari, segui questo sito per installare mlpack usando un comando di una riga a seconda della tua distribuzione: Istruzioni per l'installazione di MLPACK. Il metodo sopra funziona per tutte le distribuzioni.
Compila programmi con mlpack
- Includi i file di intestazione pertinenti nel tuo programma (assumendo k significa implementazione):
-
- #includere
- #includere
- #includere
- Per compilare dobbiamo collegare le seguenti librerie:
-
- std = c ++ 11 -larmadillo -lmlpack -lboost_seriaization
Implementando K-Means con mlpack
K-means è un algoritmo basato sul centroide, o un algoritmo basato sulla distanza, dove calcoliamo le distanze per assegnare un punto a un gruppo. En K-Mezzi, ogni gruppo è legato a un centroide.
El objetivo principal del algoritmo K-Means es minimizar la suma de distancias entre los puntos y su respectivo centroide de grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.....
K-means è effettivamente una procedura iterativa in cui vogliamo segmentare i dati in determinati gruppi. Primo, assegniamo dei centroidi iniziali, quindi questi possono essere assolutamente casuali. Prossimo, per ogni punto dati, troviamo il baricentro più vicino. Quindi assegneremo quel punto dati a quel centroide. Quindi, ogni centroide rappresenta una classe. E una volta mappati tutti i punti dati su ciascun centroide, calcoleremo la media di questi centroidi.
Per una comprensione dettagliata dell'algoritmo delle medie K, leggi questo tutorial: La guida più completa per raggruppare i K-mezzi di cui avrai mai bisogno.
Qui, implementeremo k-means usando la libreria mlpack in C ++.
Fase di inizializzazione
Inizieremo includendo le librerie e le funzioni di intestazione per k-means:
Prossimo, creeremo alcune variabili di base per determinare il numero di cluster, la dimensionalità del programma, il numero di campioni e il numero massimo di iterazioni che vogliamo fare. Come mai? Perché K-means è una procedura iterativa.
Prossimo, creeremo i dati. Quindi è qui che useremo per la prima volta il Armadillo Biblioteca. Creeremo una classe di mappa che è effettivamente un contenitore di dati:
Ecco qua! Questa classe mat, i dati dell'oggetto che possiedi, gli abbiamo dato una dimensionalità di due, e lui sa che sta per avere 50 campioni, e hai inizializzato tutti questi valori di dati per essere 0.
Prossimo, assegneremo alcuni dati casuali a questa classe di dati e quindi eseguiremo K-means in modo efficace. vado a creare 25 punti intorno alla posizione 1 1, e possiamo farlo dicendo efficacemente che ogni punto dati è 1 1 o nella posizione X è uguale a 1, ed è uguale a 1. Dopo, aggiungeremo un po' di rumore casuale. per ciascuno dei 25 punti dati. Vediamolo in azione:
Qui, andare da 0 un 25, la i-esima colonna deve essere questo tipo di arma vettore in posizione 11, e poi aggiungeremo una certa quantità di rumore casuale di dimensioni 2. Quindi, sarà a Il vettore del rumore casuale bidimensionale moltiplicato per 0,25 fino a questa posizione, e quella sarà la nostra colonna di dati. E poi faremo esattamente lo stesso per il punto x è uguale a 2 e y è uguale a 3.
E i nostri dati sono pronti! È ora di passare alla fase di allenamento.
Fase di formazione
Quindi, primo, istanziamo un tipo di riga di arma mat per contenere i gruppi, e poi istanziamo un'arma mat per contenere i centroidi:
Ora, dobbiamo creare un'istanza della classe K-means:
Abbiamo istanziato la classe K-means e specificato il numero massimo di iterazioni da passare al costruttore. Quindi ora possiamo andare avanti e fare gruppo.
Chiameremo la funzione membro Cluster di questa classe K-means. Dobbiamo passare i dati, il numero di cluster, e poi dobbiamo passare anche l'oggetto cluster e l'oggetto centroide.
Ora, questa funzione cluster eseguirà K-means su questi dati con un numero specifico di cluster, e poi inizializzerà questi due oggetti: cluster e centroidi.
Generazione di risultati
Possiamo semplicemente visualizzare i risultati usando il centroids.print funzione. Questo ti darà la posizione dei centroidi:
Prossimo, dobbiamo compilare. Nel terminale, digita il seguente comando (ancora, assicurati che la directory sia configurata correttamente):
g++ k_means.cpp -o kmeans_test -O3 -std=c++11 -larmadillo -lmlpack -lboost_seriaization && ./kmeans_test
Una volta compilato, avrebbe creato un oggetto kmeans. Ora basta eseguire il programma. L'output che otteniamo è:
centroidi:
0,9497 1,9625
0,9689 3,0652
E questo è!
Note finali
In questo post, Abbiamo visto due famose librerie di machine learning che ci aiutano a implementare modelli di machine learning in c ++. Adoro l'ampio supporto disponibile nella documentazione ufficiale, quindi dai un'occhiata. Se hai bisogno d'aiuto, contattami qui sotto e sarò felice di ricontattarti.
Nel prossimo post, implementeremo alcuni modelli di apprendimento automatico interessanti come alberi decisionali e foreste casuali. Quindi restate sintonizzati!





